第三次作业
作业一
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取
输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
单线程:
1 # 031804127王璐 2 3 from wsgiref import headers 4 from bs4 import BeautifulSoup 5 from bs4 import UnicodeDammit 6 import urllib.request 7 8 9 def imageSpider(start_url): 10 try: 11 urls = [] 12 req = urllib.request.Request(start_url, headers=headers) 13 data = urllib.request.urlopen(req) 14 data = data.read() 15 dammit = UnicodeDammit(data, ["utf-8", "gbk"]) 16 data = dammit.unicode_markup 17 soup = BeautifulSoup(data, 'lxml') 18 images = soup.select("img") # 爬取所有图片 19 for image in images: 20 try: 21 # 获取图片的url 22 src = image["src"] 23 url = urllib.request.urljoin(start_url, src) 24 if url not in urls: 25 urls.append(url) # 没有被爬取过的图片就添加 26 print(url) 27 download(url) # 下载图片 28 except Exception as err: 29 print(err) 30 except Exception as err: 31 print(err) 32 33 34 def download(url): 35 global count # 声明全局变量count 36 try: 37 count = count + 1 38 if (url[len(url) - 4] == "."): # 图片格式后缀为三位,格式后缀前面的字符为"." 39 ext = url[len(url) - 4:] # 获取图片格式 40 else: 41 ext = "" 42 # 获取图片文件 43 req = urllib.request.Request(url, headers=headers) 44 data = urllib.request.urlopen(req, timeout=100) 45 data = data.read() 46 # 存储图片到指定位置并命名 47 fobj = open("D:\\images(1)\\" + str(count) + ext, "wb") # 以二进制形式打开文件 48 fobj.write(data) 49 fobj.close() 50 print("downloaded" + str(count) + ext) 51 except Exception as err: 52 print(err) 53 54 55 start_url = "http://www.weather.com.cn" 56 headers = {"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"} 57 count = 0 # 用于记录爬取图片的个数 58 imageSpider(start_url)
实验结果:
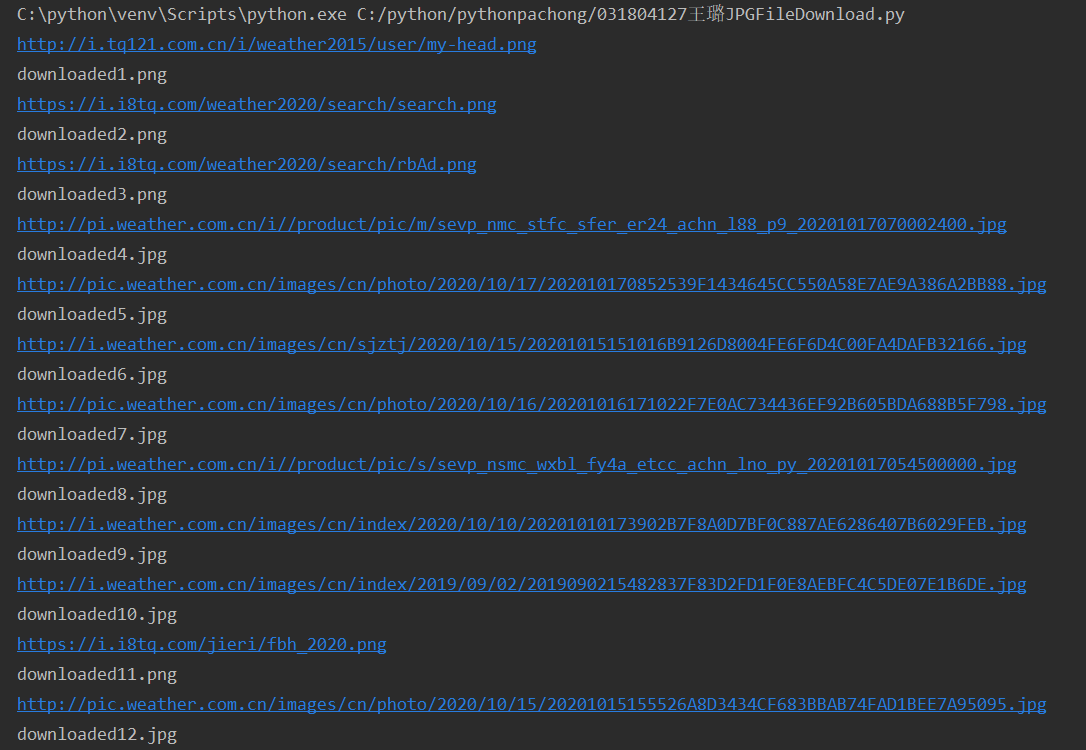
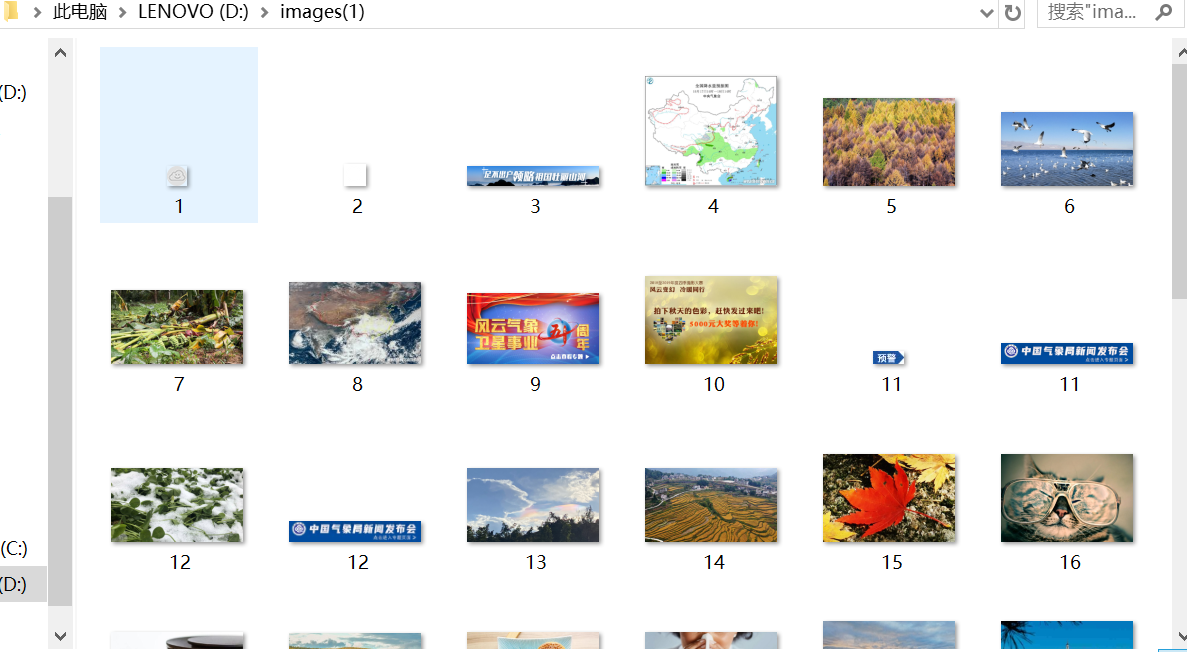
多线程:
1 # 031804127王璐 2 3 from bs4 import BeautifulSoup 4 from bs4 import UnicodeDammit 5 import urllib.request 6 import threading 7 8 9 def imageSpider(start_url): 10 global threads 11 global count 12 try: 13 urls = [] 14 req = urllib.request.Request(start_url, headers=headers) 15 data = urllib.request.urlopen(req) 16 data = data.read() 17 dammit = UnicodeDammit(data, ["utf-8", "gbk"]) 18 data = dammit.unicode_markup 19 soup = BeautifulSoup(data, 'lxml') 20 images = soup.select("img") # 爬取所有图片 21 for image in images: 22 try: 23 # 获取图片的url 24 src = image["src"] 25 url = urllib.request.urljoin(start_url, src) 26 if url not in urls: 27 print(url) 28 count = count + 1 29 T = threading.Thread(target=download, args=(url, count)) 30 T.setDaemon(False) 31 T.start() 32 threads.append() 33 except Exception as err: 34 print(err) 35 except Exception as err: 36 print(err) 37 38 39 def download(url, count): 40 try: 41 if (url[len(url) - 4] == "."): # 图片格式后缀为三位,格式后缀前面的字符为"." 42 ext = url[len(url) - 4:] # 获取图片格式 43 else: 44 ext = "" 45 # 获取图片文件 46 req = urllib.request.Request(url, headers=headers) 47 data = urllib.request.urlopen(req, timeout=100) 48 data = data.read() 49 # 存储图片到指定位置并命名 50 fobj = open("D:\\images(2)\\" + str(count) + ext, "wb") # 以二进制形式打开文件 51 fobj.write(data) 52 fobj.close() 53 print("downloaded" + str(count) + ext) 54 except Exception as err: 55 print(err) 56 57 start_url = "http://www.weather.com.cn" 58 headers = {"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"} 59 count = 0 # 用于记录爬取图片的个数 60 threads = [] 61 62 imageSpider(start_url) 63 64 for t in threads: 65 t.join() 66 print("The End")
实验结果:
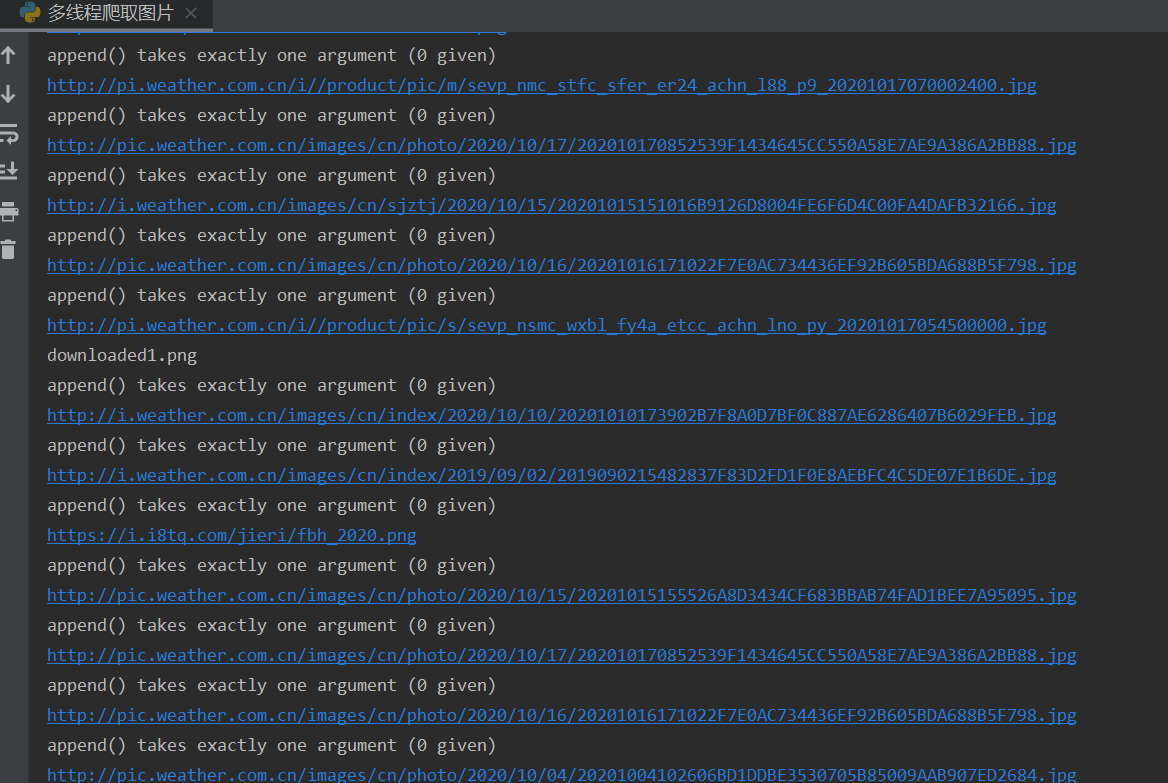

实验心得:
与单线程相比,多线程的效率更高,因为它可以在后台同时下载多张图片,多张图片的下载互不干扰,不会像单线程那样会因某个图像下载缓慢而效率低下。使用多线程时,要注意前后台线程的区别,也要合理运用线程锁,防止多线程冲突。
作业二
要求:使用scrapy框架复现作业一
输出信息:同作业一
DownloadImaes.py
1 # 031804127王璐 2 import scrapy 3 from Images.items import ImagesItem 4 5 6 class DownloadimagesSpider(scrapy.Spider): 7 name = 'DownloadImages' 8 start_urls = ['http://www.weather.com.cn/'] 9 10 def parse(self, response): 11 data = response.body.decode() 12 selector = scrapy.Selector(text=data) 13 item = ImagesItem() 14 item['img_urls'] = selector.xpath("//img/@src").extract() # 提取图片链接 15 # print 'image_urls',item['image_urls'] 16 yield item
pipelines.py
1 # 031804127王璐 2 3 import os 4 import urllib.request 5 from Images.settings import IMAGES_STORE 6 7 8 class ImagesPipeline(object): 9 def process_item(self, item, spider): 10 dir_path = IMAGES_STORE + '/' + spider.name # 存储路径 11 if not os.path.exists(dir_path): 12 os.makedirs(dir_path) 13 for image_url in item['img_urls']: 14 list_name = image_url.split('/') 15 file_name = list_name[len(list_name) - 1] # 图片名称 16 # print 'filename',file_name 17 file_path = dir_path + '/' + file_name 18 # print 'file_path',file_path 19 if os.path.exists(file_name): 20 continue 21 req = urllib.request.Request(image_url) 22 data = urllib.request.urlopen(req, timeout=100) 23 data = data.read() 24 fobj = open(file_path, "wb") 25 fobj.write(data) 26 fobj.close() 27 return item
items.py
1 # 031804127王璐 2 3 import scrapy 4 5 6 class ImagesItem(scrapy.Item): 7 # define the fields for your item here like: 8 # name = scrapy.Field() 9 img_urls = scrapy.Field()
settings.py
1 BOT_NAME = 'Images' 2 3 SPIDER_MODULES = ['Images.spiders'] 4 NEWSPIDER_MODULE = 'Images.spiders' 5 6 ITEM_PIPELINES = { 7 'Images.pipelines.ImagesPipeline': 300 8 } 9 # 开启报头 10 USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) ' \ 11 'Chrome/19.0.1084.54 Safari/536.5 ' 12 13 IMAGES_STORE = 'C:/My work/pachong/test1/Images' 14 DOWNLOAD_DELAY = 0.25 15 ROBOTSTXT_OBEY = False
实验结果:


实验心得:
了解和学习了运用scrapy框架进行爬虫,其实实现方式和作业一差不多,但是由于scrapy框架的特点,需要将不同的的功能分成不同的py文件书写,条理清晰的同时,也具有更加强大的爬虫功能。Xpath语法我自认为是目前学过的最方便的查找HTML元素的语法,但是还需多加练习。
然后由于中国天气网中的图片链接都是这种形式

所以我没有运用书本例题用数字+提取'.'后图片格式命名图片的方式,而是直接用‘/’分割图片地址,直接用分割完成后的最后一个字符串命名图片。
作业三
要求:使用scrapy框架爬取股票相关信息
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
stocks.py
1 # 031804127王璐 2 3 import json 4 import scrapy 5 from Gupiao.items import GupiaoItem 6 7 8 class StocksSpider(scrapy.Spider): 9 name = 'stocks' 10 start_urls = [ 11 'http://49.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240918880626239239_1602070531441&pn=1&pz=20&po=1&np=3&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602070531442'] 12 13 def parse(self, response): 14 jsons = response.text[41:][:-2] # 将前后用不着的字符排除 15 text_json = json.loads(jsons) 16 for data in text_json['data']['diff']: 17 item = GupiaoItem() 18 item["f12"] = data['f12'] 19 item["f14"] = data['f14'] 20 item["f2"] = data['f2'] 21 item["f3"] = data['f3'] 22 item["f4"] = data['f4'] 23 item["f5"] = data['f5'] 24 item["f6"] = data['f6'] 25 item["f7"] = data['f7'] 26 yield item 27 print("完成") 28 29 # 再爬取后10页的内容 30 for i in range(2, 11): 31 new_url = 'http://49.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240918880626239239_1602070531441&pn=' + str( 32 i) + '&pz=20&po=1&np=3&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602070531442' 33 if new_url: 34 yield scrapy.Request(new_url, callback=self.parse)
pipelines.py
1 # 031804127王璐 2 3 class GupiaoPipeline: 4 count = 0 5 print("序号\t", "代码\t", "名称\t", "最新价\t ", "涨跌幅\t ", "跌涨额\t", "成交量\t", "成交额\t", "涨幅\t") 6 7 # 打印结果 8 def process_item(self, item, spider): 9 try: 10 self.count += 1 11 print(str(self.count) + "\t", item['f12'] + "\t", item['f14'] + "\t", str(item['f2']) + "\t", 12 str(item['f3']) + "%\t", str(item['f4']) + "\t", str(item['f5']) + "\t", str(item['f6']) + "\t", 13 str(item['f7']) + "%") 14 15 except Exception as err: 16 print(err) 17 18 return item
items.py
1 # 031804127王璐 2 3 import scrapy 4 5 6 class GupiaoItem(scrapy.Item): 7 # define the fields for your item here like: 8 # name = scrapy.Field() 9 f12 = scrapy.Field() 10 f14 = scrapy.Field() 11 f2 = scrapy.Field() 12 f3 = scrapy.Field() 13 f4 = scrapy.Field() 14 f5 = scrapy.Field() 15 f6 = scrapy.Field() 16 f7 = scrapy.Field()
settings.py
1 BOT_NAME = 'Gupiao' 2 3 SPIDER_MODULES = ['Gupiao.spiders'] 4 NEWSPIDER_MODULE = 'Gupiao.spiders' 5 6 ROBOTSTXT_OBEY = False # 必须设为False,否则无法打印结果 7 8 ITEM_PIPELINES = { 9 'Gupiao.pipelines.GupiaoPipeline': 300, 10 }
实验结果:

实验心得:
实现方式同样是和之前使用request库差不多。但是在我前几次测试的时候,发现一直打印不出结果,经过网上查找后发现需要在settings.py中把ROBOTSTXT_OBEY设置为false。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号