第一次个人编程作业
我的github地址:https://github.com/bambilu32/031804127
思路:
● 使用jieba包分别对两篇中文txt文件进行分词,得如['今天', '我', '遇到', '一只', '蹦蹦跳跳', '的', '兔子']的两个字符串数组;
● 对得到的分词后的数组通过进行词袋模型统计,得到他们每个词在文中出现的次数向量;
● 对得到的两个次数的矩阵进行余弦相似度计算,得到余弦相似度作为它们的文本相似度。
流程图:
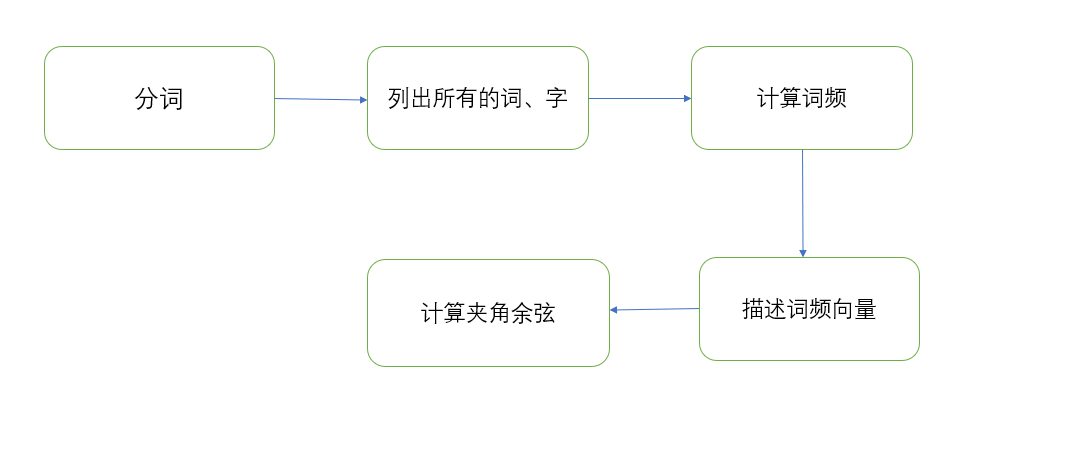
一、计算模块接口的设计与实现过程
首先我定义了一个计算文本相似度度的类Similarity()
class Similarity():
然后我在这个类里定义了__init__()、vector()、mix()、mapminmax()、similar()五个方法,下面来分别说它们的作用:
(1)init()
init()方法在对象被创立的时候就会自动调用,target1,target2两个参数用于接收两个文本,参数topK在下面的方法讲解里面会提到。
def __init__(self, target1, target2, topK=10):
(2)vector()
介绍一下基于TF-IDF的关键词提取的原理:
● TF:如果某个单词在这段文字中出现频率越高,TF越大,说明这个单词对于这段文字越重要
● IDF:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力
如果某个词出现的频率很高(TF越大),并且在其他文章中很少出现(IDF越大),即TF*IDF越大,则认为这个词适合用来分类,也适合用来当作关键字,因此,这里的topK参数,就是用来返回TF、IDF权重最大的关键字的个数,设为10。
我使用了ieba.analyse.extract_tags()方法进行关键字提取,并返回每个关键字的权重
top_keywords1 = jieba.analyse.extract_tags(self.target1, topK=self.topK, withWeight=True)
top_keywords2 = jieba.analyse.extract_tags(self.target2, topK=self.topK, withWeight=True)
然后建立两个字典,分别统计两个文本关键字的权重
self.vdict1 = {}
self.vdict2 = {}
for k, v in top_keywords1:
self.vdict1[k] = v
for k, v in top_keywords2:
self.vdict2[k] = v
(3)mix()
主要看此方法中的mapminmax()方法,用于计算关键词的相对词频率,因为文章的长度可能不一致,所以使用相对词频率更可靠。
def mapminmax(vdict):
"""计算相对词频"""
_min = min(vdict.values())
_max = max(vdict.values())
_mid = _max - _min
# print _min, _max, _mid
for key in vdict:
if _mid != 0:
vdict[key] = (vdict[key] - _min) / _mid
else:
vdict[key] = 0
return vdict
(4)similar()
举一个具体的例子,假如文本X 和文本 Y 对应向量分别是
● x1,x2,…,x64000
● y1,y2,…,y64000
那么它们夹角的余弦等于:

当两个文本向量夹角的余弦等于1时,这两个文本完全重复;当夹角的余弦接近于一时,两条新闻相似;夹角的余弦越小,两条文本越不相关。
这是计算余弦相似度的函数,用于返回最后的结果
def similar(self):
self.vector()
self.mix()
sum = 0
for key in self.vdict1:
sum += self.vdict1[key] * self.vdict2[key]
A = sqrt(reduce(lambda x, y: x + y, map(lambda x: x * x, self.vdict1.values())))
B = sqrt(reduce(lambda x, y: x + y, map(lambda x: x * x, self.vdict2.values())))
if A * B != 0:
return sum / (A * B)
else:
return 0.0
用流程图来描述一下这些函数的关系

二、计算模块接口部分的性能改进
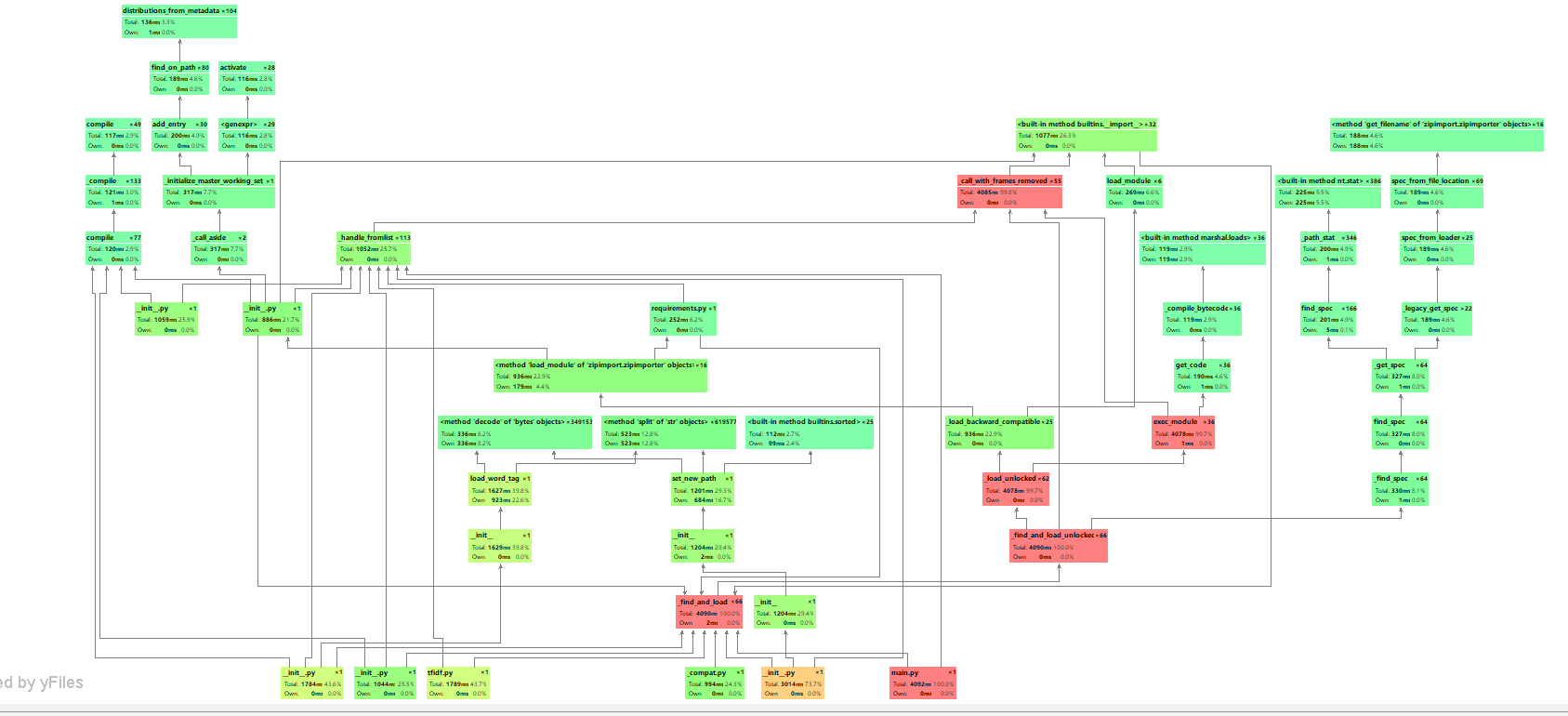
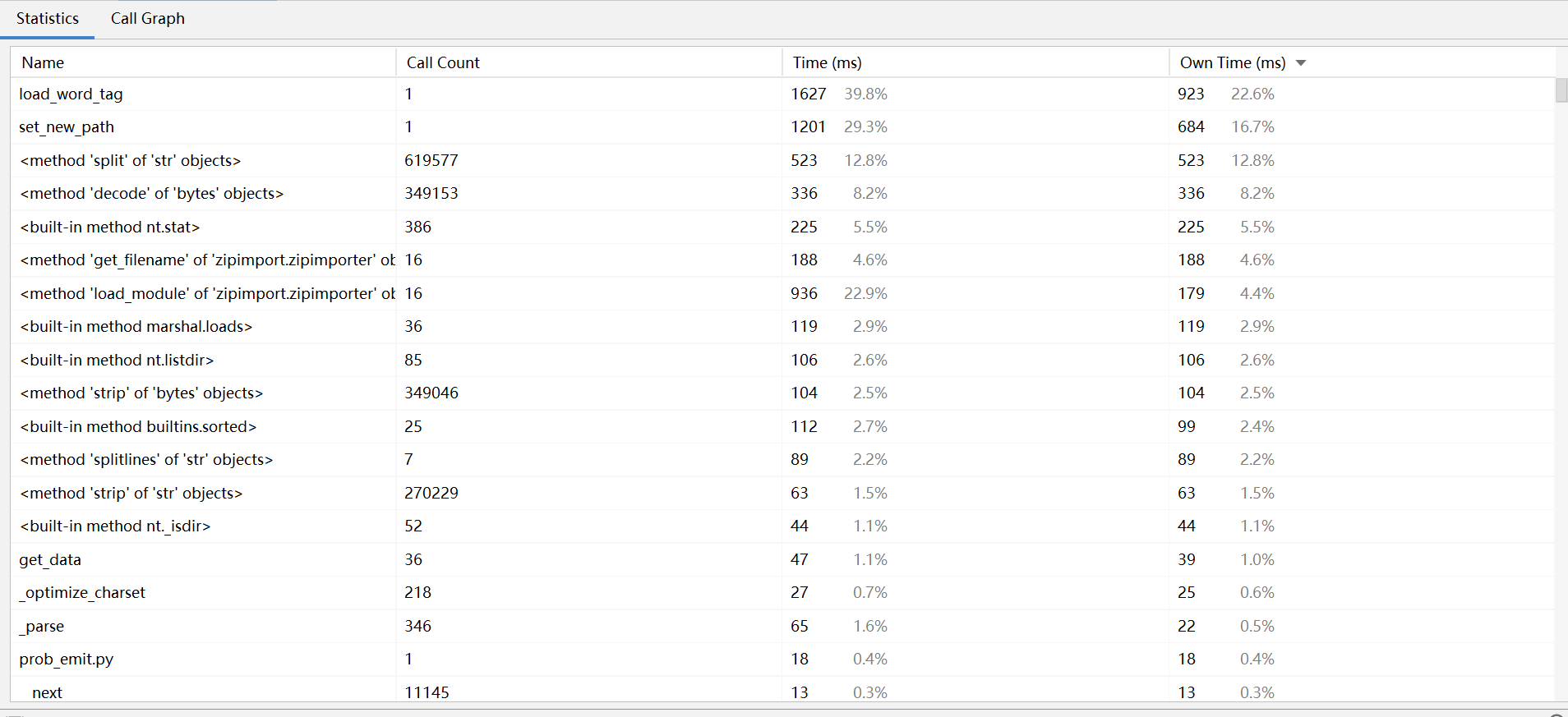
性能分析图:
程序中消耗最大的是是jieba库的方法
整个程序用时4s多:

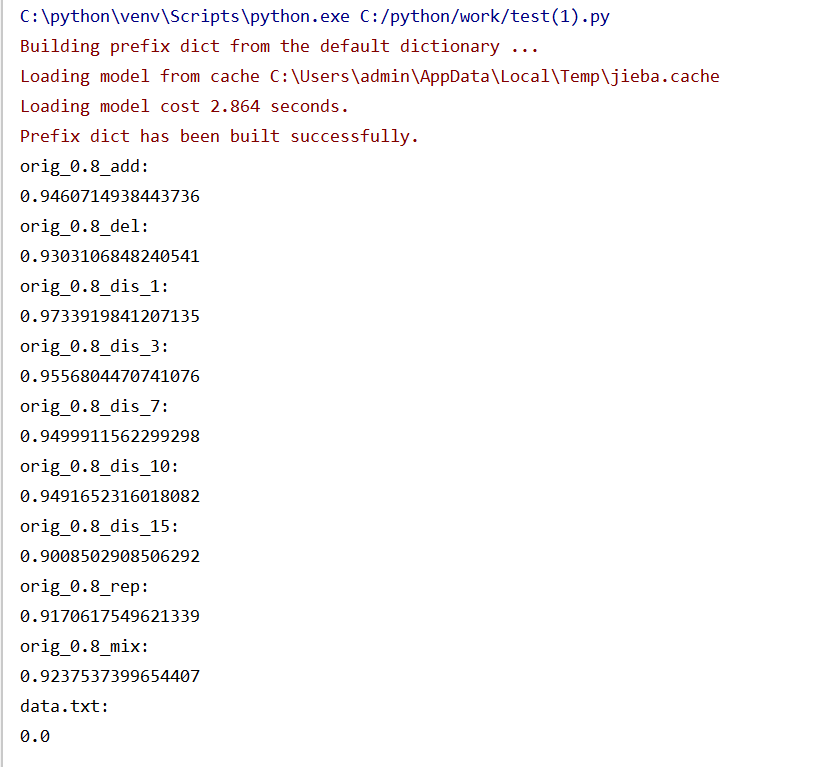
三、计算模块部分单元测试展示
我测试了10个文本,前9个文本是老师给的,最后1个文本data.txt是我自己建立的空文本,当对比文本为空文本时,返回值为0.0,测试结果如下:
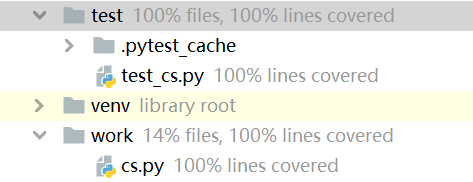
测试覆盖率图:
我创建了cs.py用于单元测试的调用,放在文件夹work下,单元测试代码是test_cs.py,放在文件夹test下
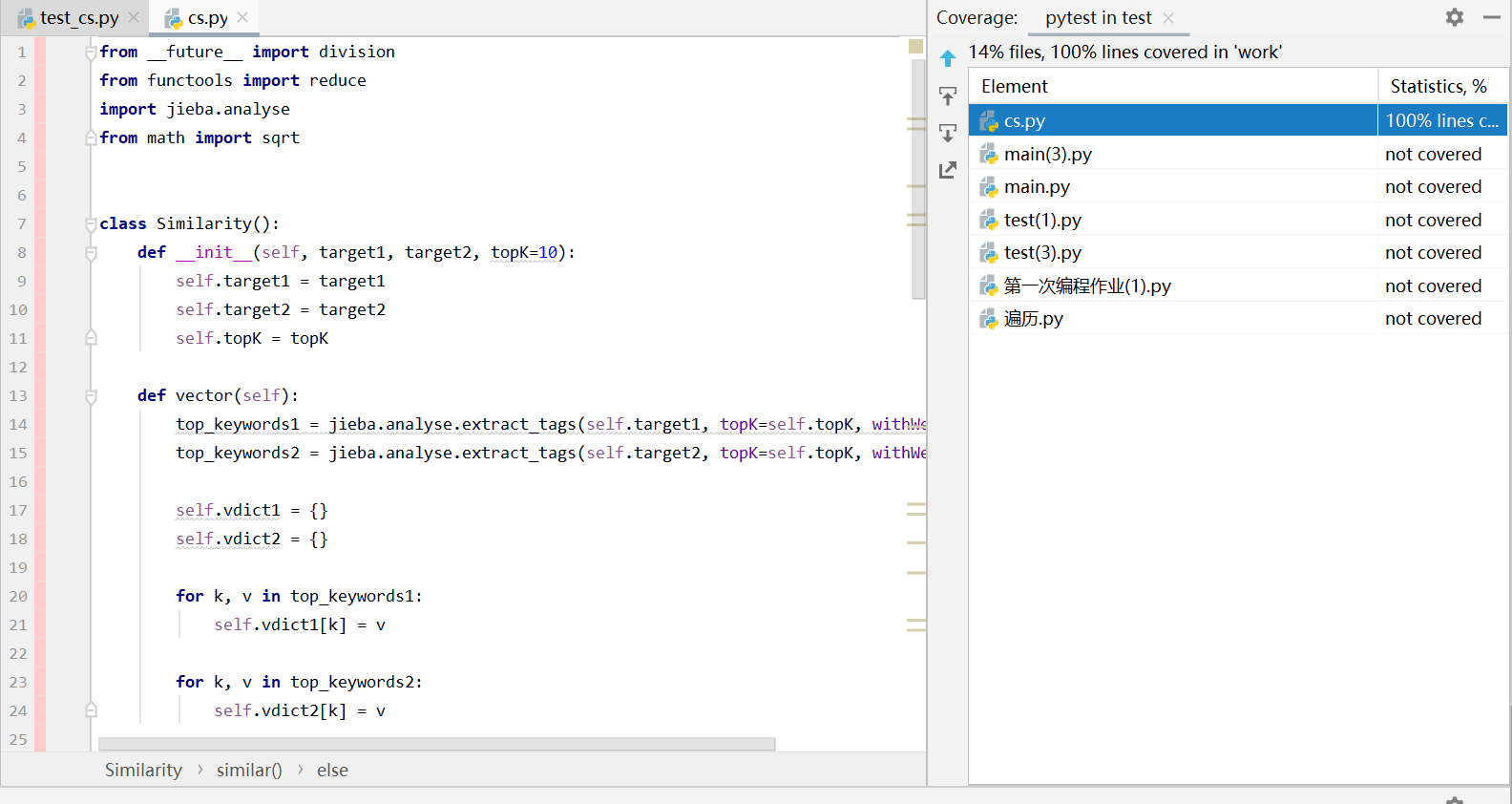
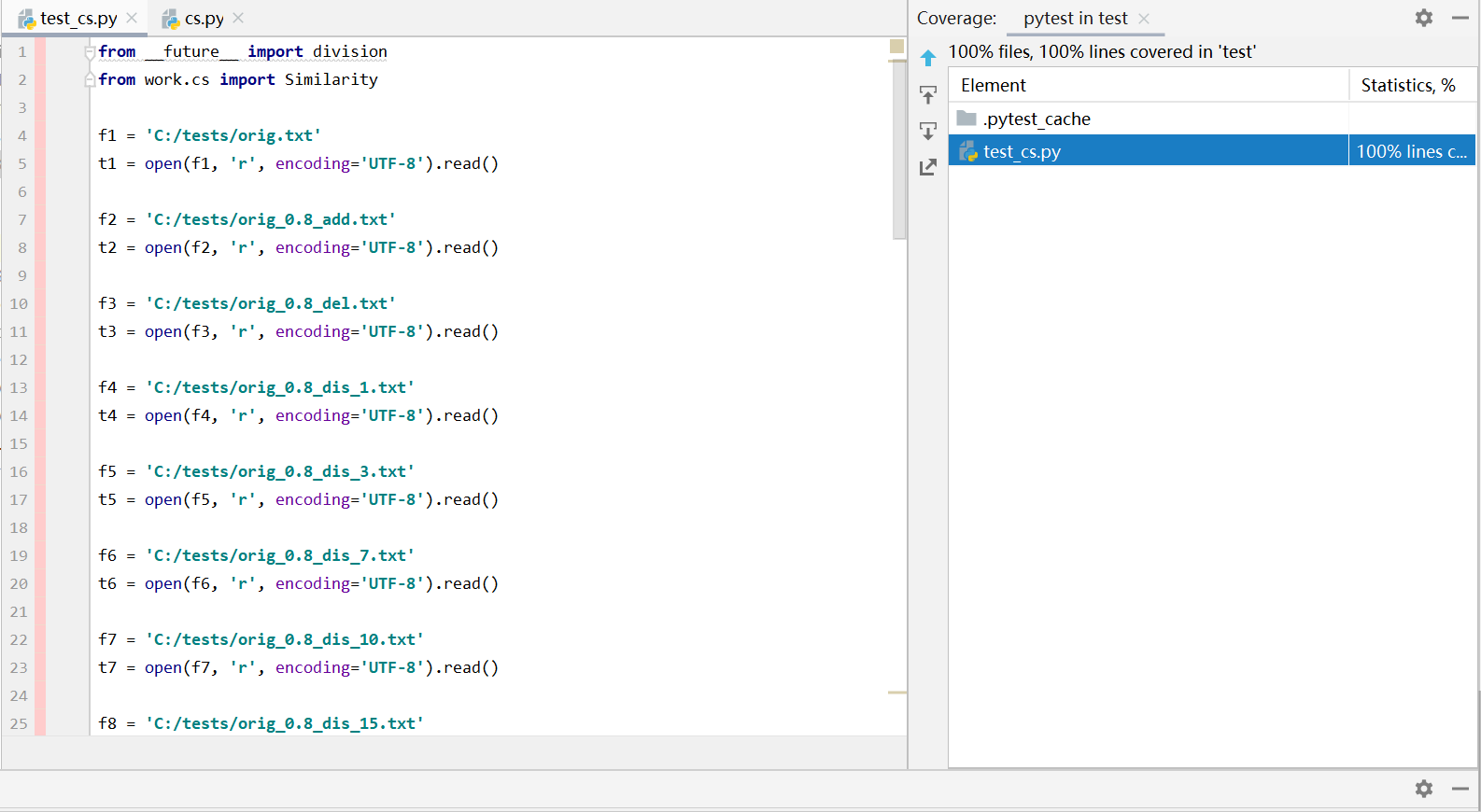
cs.py:
from __future__ import division
from functools import reduce
import jieba.analyse
from math import sqrt
class Similarity():
def __init__(self, target1, target2, topK=10):
self.target1 = target1
self.target2 = target2
self.topK = topK
def vector(self):
top_keywords1 = jieba.analyse.extract_tags(self.target1, topK=self.topK, withWeight=True)
top_keywords2 = jieba.analyse.extract_tags(self.target2, topK=self.topK, withWeight=True)
self.vdict1 = {}
self.vdict2 = {}
for k, v in top_keywords1:
self.vdict1[k] = v
for k, v in top_keywords2:
self.vdict2[k] = v
def mix(self):
for key in self.vdict1:
self.vdict2[key] = self.vdict2.get(key, 0)
for key in self.vdict2:
self.vdict1[key] = self.vdict1.get(key, 0)
def mapminmax(vdict):
"""计算相对词频"""
_min = min(vdict.values())
_max = max(vdict.values())
_mid = _max - _min
for key in vdict:
if _mid != 0:
vdict[key] = (vdict[key] - _min) / _mid
else:
vdict[key] = 0
return vdict
self.vdict1 = mapminmax(self.vdict1)
self.vdict2 = mapminmax(self.vdict2)
def similar(self):
self.vector()
self.mix()
sum = 0
for key in self.vdict1:
sum += self.vdict1[key] * self.vdict2[key]
A = sqrt(reduce(lambda x, y: x + y, map(lambda x: x * x, self.vdict1.values())))
B = sqrt(reduce(lambda x, y: x + y, map(lambda x: x * x, self.vdict2.values())))
if A * B != 0:
return sum / (A * B)
else:
return 0.0
test_cs.py:
from __future__ import division
from work.cs import Similarity
f1 = 'C:/tests/orig.txt'
t1 = open(f1, 'r', encoding='UTF-8').read()
f2 = 'C:/tests/orig_0.8_add.txt'
t2 = open(f2, 'r', encoding='UTF-8').read()
f3 = 'C:/tests/orig_0.8_del.txt'
t3 = open(f3, 'r', encoding='UTF-8').read()
f4 = 'C:/tests/orig_0.8_dis_1.txt'
t4 = open(f4, 'r', encoding='UTF-8').read()
f5 = 'C:/tests/orig_0.8_dis_3.txt'
t5 = open(f5, 'r', encoding='UTF-8').read()
f6 = 'C:/tests/orig_0.8_dis_7.txt'
t6 = open(f6, 'r', encoding='UTF-8').read()
f7 = 'C:/tests/orig_0.8_dis_10.txt'
t7 = open(f7, 'r', encoding='UTF-8').read()
f8 = 'C:/tests/orig_0.8_dis_15.txt'
t8 = open(f8, 'r', encoding='UTF-8').read()
f9 = 'C:/tests/orig_0.8_rep.txt'
t9 = open(f9, 'r', encoding='UTF-8').read()
f10 = 'C:/tests/orig_0.8_mix.txt'
t10 = open(f10, 'r', encoding='UTF-8').read()
f11 = 'C:/tests/data.txt'
t11 = open(f11, 'r', encoding='UTF-8').read()
s1 = Similarity(t1, t2, 10)
s2 = Similarity(t1, t3, 10)
s3 = Similarity(t1, t4, 10)
s4 = Similarity(t1, t5, 10)
s5 = Similarity(t1, t6, 10)
s6 = Similarity(t1, t7, 10)
s7 = Similarity(t1, t8, 10)
s8 = Similarity(t1, t9, 10)
s9 = Similarity(t1, t10, 10)
s10 = Similarity(t1, t11, 10)
result1 = s1.similar()
result2 = s2.similar()
result3 = s3.similar()
result4 = s4.similar()
result5 = s5.similar()
result6 = s6.similar()
result7 = s7.similar()
result8 = s8.similar()
result9 = s9.similar()
result10 = s10.similar()
print("orig_0.8_add:")
print(result1)
print("orig_0.8_del:")
print(result2)
print("orig_0.8_dis_1:")
print(result3)
print("orig_0.8_dis_3:")
print(result4)
print("orig_0.8_dis_7:")
print(result5)
print("orig_0.8_dis_10:")
print(result6)
print("orig_0.8_dis_15:")
print(result7)
print("orig_0.8_rep:")
print(result8)
print("orig_0.8_mix:")
print(result9)
print("data.txt:")
print(result10)
四、计算模块部分异常处理说明
我想到的异常处理就是对空文本的异常处理,当文件为空时,相似度为0,测试结果如下(data.txt是空文本):

五、总结
在这次作业中,我认识到了自己在编程方面还有很大的不足;实现程序的过程中,在网上查找了许多资料,自己也学习到了很多新的知识。同时,编写博客也是对我自己语言组织和管理能力的锻炼;性能评测是我在以前编写程序的时候没有使用过的工具,通过这次作业,我知道了今后怎样改进自己的代码,让程序的性能更好。
六、PSP表格
| **PSP2.1 ** | **Personal Software Process Stages ** | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 70 | 60 |
| Estimate | 估计这个任务需要多少时间 | 60 | 70 |
| Development | 开发 | 120 | 240 |
| Analysis | 需求分析 (包括学习新技术) | 500 | 680 |
| Design Spec | 生成设计文档 | 40 | 30 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | 具体设计 | 240 | 300 |
| Coding | 具体编码 | 120 | 120 |
| Code Review | 代码复审 | 60 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 50 | 60 |
| Reporting | 报告 | 50 | 60 |
| Test Report | 测试报告 | 40 | 30 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 15 |
| 合计 | 1460 | 1785 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号