

TCP三次握手Linux源码解析
TCP是面向连接的协议。面向连接的传输层协议在原点和重点之间建立了一条虚拟路径,同属于一个报文的所有报文段都沿着这条虚拟路径发送,为整个报文使用一条虚拟路径能够更容易地实施确认过程以及对损伤或者丢失报文的重传。TCP比IP工作在更高的层次上。TCP使用IP的服务,把一个个保温段交付给接受方,但是连接本身是由TCP所控制的。如果一个报文段丢失或者受到损伤,那么这个报文段就被重传。与TCP不同,IP不知道TCP的重传行为。如果一个报文段没有按序到达,那么TCP会保留它,直至丢失的报文段到达为止,但IP并不知道这个重新排序的过程。
在TCP中,面向连接的传输需要经过三个阶段:连接建立,数据传输和连接终止。
首先,简述TCP传输控制协议的连接建立过程,也就是三次握手(three-way handshaking)过程:
一个称为客户的应用程序希望使用TCP作为传输层协议来和另一个称为服务器的应用程序建立连接。这个过程从服务器开始。服务器程序告诉它的TCP自己已经准备好接受连接。这个请求被称为被动打开请求。虽然服务器的TCP已经准备好接受来自世界上任何一个机器的连接,但是它自己并不能完成这个连接。
客户程序发出的请求成为主动打开。打开与某个开放的服务器进行连接的客户告诉它的TCP,自己需要连接到某个特定的服务器上。TCP现在可以开始进行三次握手过程。
如下图所示:
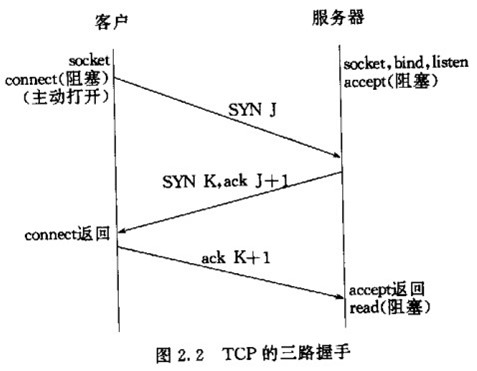
客户发送第一个报文段——SYN报文段,在这个报文段中只有SYN标志被置为1。这个报文段的作用是同步序号。客户选择一个随机数,作为第一个序号,并且把这个序号发送给服务器。这个序号称为初始序号ISN。这个报文段并不包括确认号,也没有定义窗口大小。只有当一个报文段中包含了确认时,定义窗口大小才有意义。这个报文段还可以包含一些选项。SYN报文段是一个控制报文段,它不懈怠任何数据,但是它消耗了一个序号。当数据传送开始时,序号就应该加1。也就是说,SYN报文段并不包含真正的数据,但是它要消耗一个序号。
服务器发送第二个报文段——SYN+ACK报文段,其中的两个标志SYN和ACK,置为1。这个报文段有两个目的。首先,他是另一个方向上通信的SYN报文段,服务器使用这个报文段来同步他的出使序号,以便从服务器向客户发送字节,其次,服务器还通过ACK标志来确认已经和搜到来自客户端的SYN报文段,同时给出期望从客户端受到的下一个序号。因为这个报文段包含了确认,所以他还需要定义接收窗口大小——rwnd。SYN+ACK报文段若携带数据,则消耗一个序号,否则不消耗。
客户端发送第三个报文段,这仅仅是一个ACK报文段。它使用ACK标志和确认号自断来确认受到了第二个报文段。这个报文段如果携带数据,则消耗一个序号,否则不消耗序号。
下面我们进入内核源码,分析这个过程在内核中的实现。
首先客户端调用connect主动发起连接:
1 /* 2 * Attempt to connect to a socket with the server address. The address 3 * is in user space so we verify it is OK and move it to kernel space. 4 * 5 * For 1003.1g we need to add clean support for a bind to AF_UNSPEC to 6 * break bindings 7 * 8 * NOTE: 1003.1g draft 6.3 is broken with respect to AX.25/NetROM and 9 * other SEQPACKET protocols that take time to connect() as it doesn't 10 * include the -EINPROGRESS status for such sockets. 11 * 尝试使用服务器地址连接到套接字。 12 * 地址在用户空间,所以我们验证它是OK的,并将它移动到内核空间。 13 */ 14 15 int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen) 16 { 17 struct socket *sock; 18 struct sockaddr_storage address; 19 int err, fput_needed; 20 21 //得到socket对象 22 sock = sockfd_lookup_light(fd, &err, &fput_needed); 23 if (!sock) 24 goto out; 25 //将地址对象从用户空间拷贝到内核空间 26 err = move_addr_to_kernel(uservaddr, addrlen, &address); 27 if (err < 0) 28 goto out_put; 29 //内核相关,不需要管他 30 err = 31 security_socket_connect(sock, (struct sockaddr *)&address, addrlen); 32 if (err) 33 goto out_put; 34 35 //对于流式套接字,sock->ops为 inet_stream_ops --> inet_stream_connect 36 //对于数据报套接字,sock->ops为 inet_dgram_ops --> inet_dgram_connect 37 err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, 38 sock->file->f_flags); 39 out_put: 40 fput_light(sock->file, fput_needed); 41 out: 42 return err; 43 } 44 45 SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr, 46 int, addrlen) 47 { 48 return __sys_connect(fd, uservaddr, addrlen); 49 }
该函数一共做了三件事:
第一,根据文件描述符找到指定的socket对象;
第二,将地址信息从用户空间拷贝到内核空间;
第三,调用指定类型套接字的connect函数。
对应流式套接字的connect函数是inet_stream_connect,接着我们分析该函数:
int inet_stream_connect(struct socket *sock, struct sockaddr *uaddr, int addr_len, int flags) { int err; lock_sock(sock->sk); err = __inet_stream_connect(sock, uaddr, addr_len, flags); release_sock(sock->sk); return err; } /* * Connect to a remote host. There is regrettably still a little * TCP 'magic' in here. */ //1. 检查socket地址长度和使用的协议族。 //2. 检查socket的状态,必须是SS_UNCONNECTED或SS_CONNECTING。 //3. 调用tcp_v4_connect()来发送SYN包。 //4. 等待后续握手的完成: int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr, int addr_len, int flags) { struct sock *sk = sock->sk; int err; long timeo; if (addr_len < sizeof(uaddr->sa_family)) return -EINVAL; //检查协议族 if (uaddr->sa_family == AF_UNSPEC) { err = sk->sk_prot->disconnect(sk, flags); sock->state = err ? SS_DISCONNECTING : SS_UNCONNECTED; goto out; } switch (sock->state) { default: err = -EINVAL; goto out; case SS_CONNECTED: //已经是连接状态 err = -EISCONN; goto out; case SS_CONNECTING: //正在连接 err = -EALREADY; /* Fall out of switch with err, set for this state */ break; case SS_UNCONNECTED: err = -EISCONN; if (sk->sk_state != TCP_CLOSE) goto out; //对于流式套接字,sock->ops为 inet_stream_ops --> inet_stream_connect --> tcp_prot --> tcp_v4_connect //对于数据报套接字,sock->ops为 inet_dgram_ops --> inet_dgram_connect --> udp_prot --> ip4_datagram_connect err = sk->sk_prot->connect(sk, uaddr, addr_len); if (err < 0) goto out; //协议方面的工作已经处理完成了,但是自己的一切工作还没有完成,所以切换至正在连接中 sock->state = SS_CONNECTING; /* Just entered SS_CONNECTING state; the only * difference is that return value in non-blocking * case is EINPROGRESS, rather than EALREADY. */ err = -EINPROGRESS; break; } //获取阻塞时间timeo。如果socket是非阻塞的,则timeo是0 //connect()的超时时间为sk->sk_sndtimeo,在sock_init_data()中初始化为MAX_SCHEDULE_TIMEOUT,表示无限等待,可以通过SO_SNDTIMEO选项来修改 timeo = sock_sndtimeo(sk, flags & O_NONBLOCK); if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) { int writebias = (sk->sk_protocol == IPPROTO_TCP) && tcp_sk(sk)->fastopen_req && tcp_sk(sk)->fastopen_req->data ? 1 : 0; /* Error code is set above */ //如果socket是非阻塞的,那么就直接返回错误码-EINPROGRESS。 //如果socket为阻塞的,就调用inet_wait_for_connect(),通过睡眠来等待。在以下三种情况下会被唤醒: //(1) 使用SO_SNDTIMEO选项时,睡眠时间超过设定值,返回0。connect()返回错误码-EINPROGRESS。 //(2) 收到信号,返回剩余的等待时间。connect()返回错误码-ERESTARTSYS或-EINTR。 //(3) 三次握手成功,sock的状态从TCP_SYN_SENT或TCP_SYN_RECV变为TCP_ESTABLISHED, if (!timeo || !inet_wait_for_connect(sk, timeo, writebias)) goto out; err = sock_intr_errno(timeo); //进程收到信号,如果err为-ERESTARTSYS,接下来库函数会重新调用connect() if (signal_pending(current)) goto out; } /* Connection was closed by RST, timeout, ICMP error * or another process disconnected us. */ if (sk->sk_state == TCP_CLOSE) goto sock_error; /* sk->sk_err may be not zero now, if RECVERR was ordered by user * and error was received after socket entered established state. * Hence, it is handled normally after connect() return successfully. */ //更新socket状态为连接已建立 sock->state = SS_CONNECTED; //清除错误码 err = 0; out: return err; sock_error: err = sock_error(sk) ? : -ECONNABORTED; sock->state = SS_UNCONNECTED; //如果使用的是TCP,则sk_prot为tcp_prot,disconnect为tcp_disconnect() if (sk->sk_prot->disconnect(sk, flags)) //如果失败 sock->state = SS_DISCONNECTING; goto out; }
该函数主要做了三件事:
1. 检查socket地址长度和使用的协议族;
2. 检查socket的状态,必须是SS_UNCONNECTED或SS_CONNECTING;
3. 调用实现协议的connect函数,对于流式套接字,实现协议是tcp,调用的是tcp_v4_connect();
4.对于阻塞调用,等待后续握手的完成;对于非阻塞调用,则直接返回 -EINPROGRESS。
TCP的三次握手一般由客户端通过connect发起,因此我们先来分析tcp_v4_connect的源代码:
/* This will initiate an outgoing connection. */ //对于TCP 协议来说,其连接实际上就是发送一个 SYN 报文,在服务器的应答到来时,回答它一个 ack 报文,也就是完成三次握手中的第一和第三次 int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) { struct sockaddr_in *usin = (struct sockaddr_in *)uaddr; struct inet_sock *inet = inet_sk(sk); struct tcp_sock *tp = tcp_sk(sk); __be16 orig_sport, orig_dport; __be32 daddr, nexthop; struct flowi4 *fl4; struct rtable *rt; int err; struct ip_options_rcu *inet_opt; if (addr_len < sizeof(struct sockaddr_in)) return -EINVAL; if (usin->sin_family != AF_INET) return -EAFNOSUPPORT; nexthop = daddr = usin->sin_addr.s_addr; inet_opt = rcu_dereference_protected(inet->inet_opt, lockdep_sock_is_held(sk)); //将下一跳地址和目的地址的临时变量都暂时设为用户提交的地址。 if (inet_opt && inet_opt->opt.srr) { if (!daddr) return -EINVAL; nexthop = inet_opt->opt.faddr; } //源端口 orig_sport = inet->inet_sport; //目的端口 orig_dport = usin->sin_port; fl4 = &inet->cork.fl.u.ip4; //如果使用了来源地址路由,选择一个合适的下一跳地址。 rt = ip_route_connect(fl4, nexthop, inet->inet_saddr, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if, IPPROTO_TCP, orig_sport, orig_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); if (err == -ENETUNREACH) IP_INC_STATS(sock_net(sk), IPSTATS_MIB_OUTNOROUTES); return err; } if (rt->rt_flags & (RTCF_MULTICAST | RTCF_BROADCAST)) { ip_rt_put(rt); return -ENETUNREACH; } //进行路由查找,并校验返回的路由的类型,TCP是不被允许使用多播和广播的 if (!inet_opt || !inet_opt->opt.srr) daddr = fl4->daddr; //更新目的地址临时变量——使用路由查找后返回的值 if (!inet->inet_saddr) inet->inet_saddr = fl4->saddr; sk_rcv_saddr_set(sk, inet->inet_saddr); //如果还没有设置源地址,和本地发送地址,则使用路由中返回的值 if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) { /* Reset inherited state */ tp->rx_opt.ts_recent = 0; tp->rx_opt.ts_recent_stamp = 0; if (likely(!tp->repair)) tp->write_seq = 0; } if (tcp_death_row.sysctl_tw_recycle && !tp->rx_opt.ts_recent_stamp && fl4->daddr == daddr) tcp_fetch_timewait_stamp(sk, &rt->dst); //保存目的地址及端口 inet->inet_dport = usin->sin_port; sk_daddr_set(sk, daddr); inet_csk(sk)->icsk_ext_hdr_len = 0; if (inet_opt) inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen; //设置最小允许的mss值 536 tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT; /* Socket identity is still unknown (sport may be zero). * However we set state to SYN-SENT and not releasing socket * lock select source port, enter ourselves into the hash tables and * complete initialization after this. */ //套接字状态被置为 TCP_SYN_SENT, tcp_set_state(sk, TCP_SYN_SENT); err = inet_hash_connect(&tcp_death_row, sk); if (err) goto failure; sk_set_txhash(sk); //动态选择一个本地端口,并加入 hash 表,与bind(2)选择端口类似 rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk); if (IS_ERR(rt)) { err = PTR_ERR(rt); rt = NULL; goto failure; } /* OK, now commit destination to socket. */ //设置下一跳地址,以及网卡分片相关 sk->sk_gso_type = SKB_GSO_TCPV4; sk_setup_caps(sk, &rt->dst); //还未计算初始序号 if (!tp->write_seq && likely(!tp->repair)) //根据双方地址、端口计算初始序号 tp->write_seq = secure_tcp_sequence_number(inet->inet_saddr, inet->inet_daddr, inet->inet_sport, usin->sin_port); //为 TCP报文计算一个 seq值(实际使用的值是 tp->write_seq+1) --> 根据初始序号和当前时间,随机算一个初始id inet->inet_id = tp->write_seq ^ jiffies; //函数用来根据 sk 中的信息,构建一个完成的 syn 报文,并将它发送出去。 err = tcp_connect(sk); rt = NULL; if (err) goto failure; return 0; failure: /* * This unhashes the socket and releases the local port, * if necessary. */ tcp_set_state(sk, TCP_CLOSE); ip_rt_put(rt); sk->sk_route_caps = 0; inet->inet_dport = 0; return err; }
在该函数主要完成:
1. 路由查找,得到下一跳地址,并更新socket对象的下一跳地址;
2. 将socket对象的状态设置为TCP_SYN_SENT;
3. 如果没设置序号初值,则选定一个随机初值;
4. 调用函数tcp_connect完成报文构建和发送。
继续看tcp_connect:
/* Build a SYN and send it off. */ //由tcp_v4_connect()->tcp_connect()->tcp_transmit_skb()发送,并置为TCP_SYN_SENT. int tcp_connect(struct sock *sk) { struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *buff; int err; //初始化传输控制块中与连接相关的成员 tcp_connect_init(sk); if (unlikely(tp->repair)) { tcp_finish_connect(sk, NULL); return 0; } //分配skbuff --> 为SYN段分配报文并进行初始化 buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true); if (unlikely(!buff)) return -ENOBUFS; //构建syn报文 //在函数tcp_v4_connect中write_seq已经被初始化随机值 tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN); tp->retrans_stamp = tcp_time_stamp; //将报文添加到发送队列上 tcp_connect_queue_skb(sk, buff); //显式拥塞通告 ---> //路由器在出现拥塞时通知TCP。当TCP段传递时,路由器使用IP首部中的2位来记录拥塞,当TCP段到达后, //接收方知道报文段是否在某个位置经历过拥塞。然而,需要了解拥塞发生情况的是发送方,而非接收方。因 //此,接收方使用下一个ACK通知发送方有拥塞发生,然后,发送方做出响应,缩小自己的拥塞窗口。 tcp_ecn_send_syn(sk, buff); /* Send off SYN; include data in Fast Open. */ err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) : //构造tcp头和ip头并发送 tcp_transmit_skb(sk, buff, 1, sk->sk_allocation); if (err == -ECONNREFUSED) return err; /* We change tp->snd_nxt after the tcp_transmit_skb() call * in order to make this packet get counted in tcpOutSegs. */ tp->snd_nxt = tp->write_seq; tp->pushed_seq = tp->write_seq; TCP_INC_STATS(sock_net(sk), TCP_MIB_ACTIVEOPENS); /* Timer for repeating the SYN until an answer. */ //启动重传定时器 inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS, inet_csk(sk)->icsk_rto, TCP_RTO_MAX); return 0; }
该函数完成:
1 初始化套接字跟连接相关的字段
2 申请sk_buff空间
3 将sk_buff初始化为syn报文,实质是操作tcp_skb_cb,在初始化TCP头的时候会用到
4 调用tcp_connect_queue_skb()函数将报文sk_buff添加到发送队列sk->sk_write_queue
5 调用tcp_transmit_skb()函数构造tcp头,然后交给网络层。
6 初始化重传定时器
tcp_connect_queue_skb()函数的原理主要是移动sk_buff的data指针,然后填充TCP头。再然后将报文交给网络层,将报文发出。
这样,三次握手中的第一次握手在客户端的层面完成,报文到达服务端,由服务端处理完毕后,第一次握手完成,客户端socket状态变为TCP_SYN_SENT。
继续看第二次握手,当服务端接收到客户发送端发送的报文后的处理流程:
服务端处理第二次握手的时候,调用的是tcp_v4_rev()函数:
/* * From tcp_input.c */ //网卡驱动-->netif_receive_skb()--->ip_rcv()--->ip_local_deliver_finish()---> tcp_v4_rcv() int tcp_v4_rcv(struct sk_buff *skb) { struct net *net = dev_net(skb->dev); const struct iphdr *iph; const struct tcphdr *th; bool refcounted; struct sock *sk; int ret; //如果不是发往本地的数据包,则直接丢弃 if (skb->pkt_type != PACKET_HOST) goto discard_it; /* Count it even if it's bad */ __TCP_INC_STATS(net, TCP_MIB_INSEGS); ////包长是否大于TCP头的长度 if (!pskb_may_pull(skb, sizeof(struct tcphdr))) goto discard_it; //tcp头 --> 不是很懂为何老是获取tcp头 th = (const struct tcphdr *)skb->data; if (unlikely(th->doff < sizeof(struct tcphdr) / 4)) goto bad_packet; if (!pskb_may_pull(skb, th->doff * 4)) goto discard_it; /* An explanation is required here, I think. * Packet length and doff are validated by header prediction, * provided case of th->doff==0 is eliminated. * So, we defer the checks. */ if (skb_checksum_init(skb, IPPROTO_TCP, inet_compute_pseudo)) goto csum_error; //得到tcp的头 --> 不是很懂为何老是获取tcp头 th = (const struct tcphdr *)skb->data; //得到ip报文头 iph = ip_hdr(skb); /* This is tricky : We move IPCB at its correct location into TCP_SKB_CB() * barrier() makes sure compiler wont play fool^Waliasing games. */ memmove(&TCP_SKB_CB(skb)->header.h4, IPCB(skb), sizeof(struct inet_skb_parm)); barrier(); TCP_SKB_CB(skb)->seq = ntohl(th->seq); TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin + skb->len - th->doff * 4); TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq); TCP_SKB_CB(skb)->tcp_flags = tcp_flag_byte(th); TCP_SKB_CB(skb)->tcp_tw_isn = 0; TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph); TCP_SKB_CB(skb)->sacked = 0; lookup: //根据源端口号,目的端口号和接收的interface查找sock对象------>先在建立连接的哈希表中查找------>如果没找到就从监听哈希表中找 //对于建立过程来讲肯是监听哈希表中才能找到 sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source, th->dest, &refcounted); //如果找不到处理的socket对象,就把数据报丢掉 if (!sk) goto no_tcp_socket; process: //检查sock是否处于半关闭状态 if (sk->sk_state == TCP_TIME_WAIT) goto do_time_wait; if (sk->sk_state == TCP_NEW_SYN_RECV) { struct request_sock *req = inet_reqsk(sk); struct sock *nsk; sk = req->rsk_listener; if (unlikely(tcp_v4_inbound_md5_hash(sk, skb))) { sk_drops_add(sk, skb); reqsk_put(req); goto discard_it; } if (unlikely(sk->sk_state != TCP_LISTEN)) { inet_csk_reqsk_queue_drop_and_put(sk, req); goto lookup; } /* We own a reference on the listener, increase it again * as we might lose it too soon. */ sock_hold(sk); refcounted = true; nsk = tcp_check_req(sk, skb, req, false); if (!nsk) { reqsk_put(req); goto discard_and_relse; } if (nsk == sk) { reqsk_put(req); } else if (tcp_child_process(sk, nsk, skb)) { tcp_v4_send_reset(nsk, skb); goto discard_and_relse; } else { sock_put(sk); return 0; } } if (unlikely(iph->ttl < inet_sk(sk)->min_ttl)) { __NET_INC_STATS(net, LINUX_MIB_TCPMINTTLDROP); goto discard_and_relse; } if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb)) goto discard_and_relse; if (tcp_v4_inbound_md5_hash(sk, skb)) goto discard_and_relse; nf_reset(skb); if (tcp_filter(sk, skb)) goto discard_and_relse; //tcp头部 --> 不是很懂为何老是获取tcp头 th = (const struct tcphdr *)skb->data; iph = ip_hdr(skb); skb->dev = NULL; //如果socket处于监听状态 --> 我们重点关注这里 if (sk->sk_state == TCP_LISTEN) { ret = tcp_v4_do_rcv(sk, skb); goto put_and_return; } sk_incoming_cpu_update(sk); bh_lock_sock_nested(sk); tcp_segs_in(tcp_sk(sk), skb); ret = 0; //查看是否有用户态进程对该sock进行了锁定 //如果sock_owned_by_user为真,则sock的状态不能进行更改 if (!sock_owned_by_user(sk)) { if (!tcp_prequeue(sk, skb)) //--------------------------------------------------------> ret = tcp_v4_do_rcv(sk, skb); } else if (tcp_add_backlog(sk, skb)) { goto discard_and_relse; } bh_unlock_sock(sk); put_and_return: if (refcounted) sock_put(sk); return ret; no_tcp_socket: if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) goto discard_it; if (tcp_checksum_complete(skb)) { csum_error: __TCP_INC_STATS(net, TCP_MIB_CSUMERRORS); bad_packet: __TCP_INC_STATS(net, TCP_MIB_INERRS); } else { tcp_v4_send_reset(NULL, skb); } discard_it: /* Discard frame. */ kfree_skb(skb); return 0; discard_and_relse: sk_drops_add(sk, skb); if (refcounted) sock_put(sk); goto discard_it; do_time_wait: if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) { inet_twsk_put(inet_twsk(sk)); goto discard_it; } if (tcp_checksum_complete(skb)) { inet_twsk_put(inet_twsk(sk)); goto csum_error; } switch (tcp_timewait_state_process(inet_twsk(sk), skb, th)) { case TCP_TW_SYN: { struct sock *sk2 = inet_lookup_listener(dev_net(skb->dev), &tcp_hashinfo, skb, __tcp_hdrlen(th), iph->saddr, th->source, iph->daddr, th->dest, inet_iif(skb)); if (sk2) { inet_twsk_deschedule_put(inet_twsk(sk)); sk = sk2; refcounted = false; goto process; } /* Fall through to ACK */ } case TCP_TW_ACK: tcp_v4_timewait_ack(sk, skb); break; case TCP_TW_RST: tcp_v4_send_reset(sk, skb); inet_twsk_deschedule_put(inet_twsk(sk)); goto discard_it; case TCP_TW_SUCCESS:; } goto discard_it; }
该函数主要工作就是根据tcp头部信息查到处理报文的socket对象,然后检查socket状态做不同处理,我们这里是监听状态TCP_LISTEN,直接调用函数tcp_v4_do_rcv(),不过该函数主要作用是防止洪泛和拥塞控制,和三次握手无关。接着是调用tcp_rcv_state_process():
/* * This function implements the receiving procedure of RFC 793 for * all states except ESTABLISHED and TIME_WAIT. * It's called from both tcp_v4_rcv and tcp_v6_rcv and should be * address independent. */ //除了ESTABLISHED和TIME_WAIT状态外,其他状态下的TCP段处理都由本函数实现 // tcp_v4_do_rcv() -> tcp_rcv_state_process() -> tcp_v4_conn_request() -> tcp_v4_send_synack(). int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); const struct tcphdr *th = tcp_hdr(skb); struct request_sock *req; int queued = 0; bool acceptable; switch (sk->sk_state) { //SYN_RECV状态的处理 case TCP_CLOSE: goto discard; //服务端第一次握手处理 case TCP_LISTEN: if (th->ack) return 1; if (th->rst) goto discard; if (th->syn) { if (th->fin) goto discard; // tcp_v4_do_rcv() -> tcp_rcv_state_process() -> tcp_v4_conn_request() -> tcp_v4_send_synack(). if (icsk->icsk_af_ops->conn_request(sk, skb) < 0) return 1; consume_skb(skb); return 0; } goto discard; //客户端第二次握手处理 case TCP_SYN_SENT: tp->rx_opt.saw_tstamp = 0; //处理SYN_SENT状态下接收到的TCP段 queued = tcp_rcv_synsent_state_process(sk, skb, th); if (queued >= 0) return queued; /* Do step6 onward by hand. */ //处理完第二次握手后,还需要处理带外数据 tcp_urg(sk, skb, th); __kfree_skb(skb); //检测是否有数据需要发送 tcp_data_snd_check(sk); return 0; } tp->rx_opt.saw_tstamp = 0; req = tp->fastopen_rsk; if (req) { WARN_ON_ONCE(sk->sk_state != TCP_SYN_RECV && sk->sk_state != TCP_FIN_WAIT1); if (!tcp_check_req(sk, skb, req, true)) goto discard; } if (!th->ack && !th->rst && !th->syn) goto discard; if (!tcp_validate_incoming(sk, skb, th, 0)) return 0; /* step 5: check the ACK field */ acceptable = tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT) > 0; switch (sk->sk_state) { //服务端第三次握手处理 case TCP_SYN_RECV: if (!acceptable) return 1; if (!tp->srtt_us) tcp_synack_rtt_meas(sk, req); /* Once we leave TCP_SYN_RECV, we no longer need req * so release it. */ if (req) { inet_csk(sk)->icsk_retransmits = 0; reqsk_fastopen_remove(sk, req, false); } else { /* Make sure socket is routed, for correct metrics. */ //建立路由,初始化拥塞控制模块 icsk->icsk_af_ops->rebuild_header(sk); tcp_init_congestion_control(sk); tcp_mtup_init(sk); tp->copied_seq = tp->rcv_nxt; tcp_init_buffer_space(sk); } smp_mb(); //正常的第三次握手,设置连接状态为TCP_ESTABLISHED tcp_set_state(sk, TCP_ESTABLISHED); sk->sk_state_change(sk); /* Note, that this wakeup is only for marginal crossed SYN case. * Passively open sockets are not waked up, because * sk->sk_sleep == NULL and sk->sk_socket == NULL. */ //状态已经正常,唤醒那些等待的线程 if (sk->sk_socket) sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT); tp->snd_una = TCP_SKB_CB(skb)->ack_seq; tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale; tcp_init_wl(tp, TCP_SKB_CB(skb)->seq); if (tp->rx_opt.tstamp_ok) tp->advmss -= TCPOLEN_TSTAMP_ALIGNED; if (req) { /* Re-arm the timer because data may have been sent out. * This is similar to the regular data transmission case * when new data has just been ack'ed. * * (TFO) - we could try to be more aggressive and * retransmitting any data sooner based on when they * are sent out. */ tcp_rearm_rto(sk); } else tcp_init_metrics(sk); if (!inet_csk(sk)->icsk_ca_ops->cong_control) tcp_update_pacing_rate(sk); /* Prevent spurious tcp_cwnd_restart() on first data packet */ //更新最近一次发送数据包的时间 tp->lsndtime = tcp_time_stamp; tcp_initialize_rcv_mss(sk); //计算有关TCP首部预测的标志 tcp_fast_path_on(tp); break; case TCP_FIN_WAIT1: { struct dst_entry *dst; int tmo; /* If we enter the TCP_FIN_WAIT1 state and we are a * Fast Open socket and this is the first acceptable * ACK we have received, this would have acknowledged * our SYNACK so stop the SYNACK timer. */ if (req) { /* Return RST if ack_seq is invalid. * Note that RFC793 only says to generate a * DUPACK for it but for TCP Fast Open it seems * better to treat this case like TCP_SYN_RECV * above. */ if (!acceptable) return 1; /* We no longer need the request sock. */ reqsk_fastopen_remove(sk, req, false); tcp_rearm_rto(sk); } if (tp->snd_una != tp->write_seq) break; tcp_set_state(sk, TCP_FIN_WAIT2); sk->sk_shutdown |= SEND_SHUTDOWN; dst = __sk_dst_get(sk); if (dst) dst_confirm(dst); if (!sock_flag(sk, SOCK_DEAD)) { /* Wake up lingering close() */ sk->sk_state_change(sk); break; } if (tp->linger2 < 0 || (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq && after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt))) { tcp_done(sk); NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA); return 1; } tmo = tcp_fin_time(sk); if (tmo > TCP_TIMEWAIT_LEN) { inet_csk_reset_keepalive_timer(sk, tmo - TCP_TIMEWAIT_LEN); } else if (th->fin || sock_owned_by_user(sk)) { /* Bad case. We could lose such FIN otherwise. * It is not a big problem, but it looks confusing * and not so rare event. We still can lose it now, * if it spins in bh_lock_sock(), but it is really * marginal case. */ inet_csk_reset_keepalive_timer(sk, tmo); } else { tcp_time_wait(sk, TCP_FIN_WAIT2, tmo); goto discard; } break; } case TCP_CLOSING: if (tp->snd_una == tp->write_seq) { tcp_time_wait(sk, TCP_TIME_WAIT, 0); goto discard; } break; case TCP_LAST_ACK: if (tp->snd_una == tp->write_seq) { tcp_update_metrics(sk); tcp_done(sk); goto discard; } break; } /* step 6: check the URG bit */ tcp_urg(sk, skb, th); /* step 7: process the segment text */ switch (sk->sk_state) { case TCP_CLOSE_WAIT: case TCP_CLOSING: case TCP_LAST_ACK: if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) break; case TCP_FIN_WAIT1: case TCP_FIN_WAIT2: /* RFC 793 says to queue data in these states, * RFC 1122 says we MUST send a reset. * BSD 4.4 also does reset. */ if (sk->sk_shutdown & RCV_SHUTDOWN) { if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq && after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) { NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPABORTONDATA); tcp_reset(sk); return 1; } } /* Fall through */ case TCP_ESTABLISHED: tcp_data_queue(sk, skb); queued = 1; break; } /* tcp_data could move socket to TIME-WAIT */ if (sk->sk_state != TCP_CLOSE) { tcp_data_snd_check(sk); tcp_ack_snd_check(sk); } if (!queued) { discard: tcp_drop(sk, skb); } return 0; }
这是TCP建立连接的核心所在,几乎所有状态的套接字,在收到数据报时都在这里完成处理。对于服务端来说,收到第一次握手报文时的状态为TCP_LISTEN,接下将由tcp_v4_conn_request函数处理:
// tcp_v4_do_rcv() -> tcp_rcv_state_process() -> tcp_v4_conn_request() -> tcp_v4_send_synack(). int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb) { /* Never answer to SYNs send to broadcast or multicast */ if (skb_rtable(skb)->rt_flags & (RTCF_BROADCAST | RTCF_MULTICAST)) goto drop; //tcp_request_sock_ops 定义在 tcp_ipv4.c 1256行 //inet_init --> proto_register --> req_prot_init -->初始化cache名 return tcp_conn_request(&tcp_request_sock_ops, &tcp_request_sock_ipv4_ops, sk, skb); drop: tcp_listendrop(sk); return 0; } int tcp_conn_request(struct request_sock_ops *rsk_ops, const struct tcp_request_sock_ops *af_ops, struct sock *sk, struct sk_buff *skb) { struct tcp_fastopen_cookie foc = { .len = -1 }; __u32 isn = TCP_SKB_CB(skb)->tcp_tw_isn; struct tcp_options_received tmp_opt; struct tcp_sock *tp = tcp_sk(sk); struct net *net = sock_net(sk); struct sock *fastopen_sk = NULL; struct dst_entry *dst = NULL; struct request_sock *req; bool want_cookie = false; struct flowi fl; /* TW buckets are converted to open requests without * limitations, they conserve resources and peer is * evidently real one. */ //处理TCP SYN FLOOD攻击相关的东西 //Client发送SYN包给Server后挂了,Server回给Client的SYN-ACK一直没收到Client的ACK确认,这个时候这个连接既没建立起来, //也不能算失败。这就需要一个超时时间让Server将这个连接断开,否则这个连接就会一直占用Server的SYN连接队列中的一个位置, //大量这样的连接就会将Server的SYN连接队列耗尽,让正常的连接无法得到处理。 //目前,Linux下默认会进行5次重发SYN-ACK包,重试的间隔时间从1s开始,下次的重试间隔时间是前一次的双倍,5次的重试时间间隔 //为1s, 2s, 4s, 8s, 16s,总共31s,第5次发出后还要等32s都知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 63s, //TCP才会把断开这个连接。由于,SYN超时需要63秒,那么就给攻击者一个攻击服务器的机会,攻击者在短时间内发送大量的SYN包给Server(俗称 SYN flood 攻击), //用于耗尽Server的SYN队列。对于应对SYN 过多的问题,linux提供了几个TCP参数:tcp_syncookies、tcp_synack_retries、tcp_max_syn_backlog、tcp_abort_on_overflow 来调整应对。 if ((net->ipv4.sysctl_tcp_syncookies == 2 || inet_csk_reqsk_queue_is_full(sk)) && !isn) { want_cookie = tcp_syn_flood_action(sk, skb, rsk_ops->slab_name); if (!want_cookie) goto drop; } /* Accept backlog is full. If we have already queued enough * of warm entries in syn queue, drop request. It is better than * clogging syn queue with openreqs with exponentially increasing * timeout. */ if (sk_acceptq_is_full(sk) && inet_csk_reqsk_queue_young(sk) > 1) { NET_INC_STATS(sock_net(sk), LINUX_MIB_LISTENOVERFLOWS); goto drop; } //分配一个request_sock对象来代表这个半连接 //在三次握手协议中,服务器维护一个半连接队列,该队列为每个客户端的SYN包开设一个条目(服务端在接收到SYN包的时候, //就已经创建了request_sock结构,存储在半连接队列中),该条目表明服务器已收到SYN包,并向客户发出确认,正在等待客 //户的确认包(会进行第二次握手发送SYN+ACK 的包加以确认)。这些条目所标识的连接在服务器处于Syn_RECV状态,当服 //务器收到客户的确认包时,删除该条目,服务器进入ESTABLISHED状态。该队列为SYN 队列,长度为 max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog) , //在机器的tcp_max_syn_backlog值在/proc/sys/net/ipv4/tcp_max_syn_backlog下配置。 // tcp_request_sock_ops //inet_init --> proto_register --> req_prot_init -->初始化cache名 req = inet_reqsk_alloc(rsk_ops, sk, !want_cookie); if (!req) goto drop; //特定协议的request_sock的特殊操作函数集 tcp_rsk(req)->af_specific = af_ops; tcp_clear_options(&tmp_opt); tmp_opt.mss_clamp = af_ops->mss_clamp; tmp_opt.user_mss = tp->rx_opt.user_mss; tcp_parse_options(skb, &tmp_opt, 0, want_cookie ? NULL : &foc); if (want_cookie && !tmp_opt.saw_tstamp) tcp_clear_options(&tmp_opt); tmp_opt.tstamp_ok = tmp_opt.saw_tstamp; //初始化连接请求块,包括request_sock、inet_request_sock、tcp_request_sock tcp_openreq_init(req, &tmp_opt, skb, sk); inet_rsk(req)->no_srccheck = inet_sk(sk)->transparent; /* Note: tcp_v6_init_req() might override ir_iif for link locals */ inet_rsk(req)->ir_iif = inet_request_bound_dev_if(sk, skb); //tcp_request_sock_ipv4_ops --> tcp_v4_init_req af_ops->init_req(req, sk, skb); if (security_inet_conn_request(sk, skb, req)) goto drop_and_free; if (!want_cookie && !isn) { /* VJ's idea. We save last timestamp seen * from the destination in peer table, when entering * state TIME-WAIT, and check against it before * accepting new connection request. * * If "isn" is not zero, this request hit alive * timewait bucket, so that all the necessary checks * are made in the function processing timewait state. */ if (tcp_death_row.sysctl_tw_recycle) { bool strict; dst = af_ops->route_req(sk, &fl, req, &strict); if (dst && strict && !tcp_peer_is_proven(req, dst, true, tmp_opt.saw_tstamp)) { NET_INC_STATS(sock_net(sk), LINUX_MIB_PAWSPASSIVEREJECTED); goto drop_and_release; } } /* Kill the following clause, if you dislike this way. */ else if (!net->ipv4.sysctl_tcp_syncookies && (sysctl_max_syn_backlog - inet_csk_reqsk_queue_len(sk) < (sysctl_max_syn_backlog >> 2)) && !tcp_peer_is_proven(req, dst, false, tmp_opt.saw_tstamp)) { /* Without syncookies last quarter of * backlog is filled with destinations, * proven to be alive. * It means that we continue to communicate * to destinations, already remembered * to the moment of synflood. */ pr_drop_req(req, ntohs(tcp_hdr(skb)->source), rsk_ops->family); goto drop_and_release; } isn = af_ops->init_seq(skb); } if (!dst) { dst = af_ops->route_req(sk, &fl, req, NULL); if (!dst) goto drop_and_free; } //拥塞显式通告的东西 tcp_ecn_create_request(req, skb, sk, dst); if (want_cookie) { isn = cookie_init_sequence(af_ops, sk, skb, &req->mss); req->cookie_ts = tmp_opt.tstamp_ok; if (!tmp_opt.tstamp_ok) inet_rsk(req)->ecn_ok = 0; } tcp_rsk(req)->snt_isn = isn; tcp_rsk(req)->txhash = net_tx_rndhash(); //接收窗口初始化 tcp_openreq_init_rwin(req, sk, dst); if (!want_cookie) { tcp_reqsk_record_syn(sk, req, skb); fastopen_sk = tcp_try_fastopen(sk, skb, req, &foc, dst); } //握手过程传输数据相关的东西 if (fastopen_sk) { af_ops->send_synack(fastopen_sk, dst, &fl, req, &foc, TCP_SYNACK_FASTOPEN); /* Add the child socket directly into the accept queue */ inet_csk_reqsk_queue_add(sk, req, fastopen_sk); sk->sk_data_ready(sk); bh_unlock_sock(fastopen_sk); sock_put(fastopen_sk); } else { //设置TFO选项为false tcp_rsk(req)->tfo_listener = false; if (!want_cookie) inet_csk_reqsk_queue_hash_add(sk, req, TCP_TIMEOUT_INIT); // tcp_v4_do_rcv() -> tcp_rcv_state_process() -> tcp_v4_conn_request() -> tcp_v4_send_synack(). // tcp_request_sock_ipv4_ops --> tcp_v4_send_synack af_ops->send_synack(sk, dst, &fl, req, &foc, !want_cookie ? TCP_SYNACK_NORMAL : TCP_SYNACK_COOKIE); if (want_cookie) { reqsk_free(req); return 0; } } reqsk_put(req); return 0; drop_and_release: dst_release(dst); drop_and_free: reqsk_free(req); drop: tcp_listendrop(sk); return 0; }
在该函数中做了不少的事情,但是我们这里重点了解两点:
1 分配一个request_sock对象来代表这次连接请求(状态为TCP_NEW_SYN_RECV),如果没有设置防范syn flood相关的选项,则将该request_sock添加到established状态的tcp_sock散列表(如果设置了防范选项,则request_sock对象都没有,只有建立完成时才会分配)
2 调用tcp_v4_send_synack回复客户端ack,开启第二次握手
我们看下该函数:
//向客户端发送SYN+ACK报文 static int tcp_v4_send_synack(const struct sock *sk, struct dst_entry *dst, struct flowi *fl, struct request_sock *req, struct tcp_fastopen_cookie *foc, enum tcp_synack_type synack_type) { const struct inet_request_sock *ireq = inet_rsk(req); struct flowi4 fl4; int err = -1; struct sk_buff *skb; /* First, grab a route. */ //查找到客户端的路由 if (!dst && (dst = inet_csk_route_req(sk, &fl4, req)) == NULL) return -1; //根据路由、传输控制块、连接请求块中的构建SYN+ACK段 skb = tcp_make_synack(sk, dst, req, foc, synack_type); //生成SYN+ACK段成功 if (skb) { //生成校验码 __tcp_v4_send_check(skb, ireq->ir_loc_addr, ireq->ir_rmt_addr); //生成IP数据报并发送出去 err = ip_build_and_send_pkt(skb, sk, ireq->ir_loc_addr, ireq->ir_rmt_addr, ireq->opt); err = net_xmit_eval(err); } return err; }
查找客户端路由,构造syn包,然后调用ip_build_and_send_pkt,依靠网络层将数据报发出去。至此,第二次握手完成。客户端socket状态变为TCP_ESTABLISHED,此时服务端socket的状态为TCP_NEW_SYN_RECV,接下来调用如下函数进行第三次握手:
int tcp_v4_rcv(struct sk_buff *skb) { ............. //收到握手最后一个ack后,会找到TCP_NEW_SYN_RECV状态的req,然后创建一个新的sock进入TCP_SYN_RECV状态,最终进入TCP_ESTABLISHED状态. 并放入accept队列通知select/epoll if (sk->sk_state == TCP_NEW_SYN_RECV) { struct request_sock *req = inet_reqsk(sk); struct sock *nsk; sk = req->rsk_listener; if (unlikely(tcp_v4_inbound_md5_hash(sk, skb))) { sk_drops_add(sk, skb); reqsk_put(req); goto discard_it; } if (unlikely(sk->sk_state != TCP_LISTEN)) { inet_csk_reqsk_queue_drop_and_put(sk, req); goto lookup; } /* We own a reference on the listener, increase it again * as we might lose it too soon. */ sock_hold(sk); refcounted = true; //创建新的sock进入TCP_SYN_RECV state nsk = tcp_check_req(sk, skb, req, false); if (!nsk) { reqsk_put(req); goto discard_and_relse; } if (nsk == sk) { reqsk_put(req); //调用 tcp_rcv_state_process } else if (tcp_child_process(sk, nsk, skb)) { tcp_v4_send_reset(nsk, skb); goto discard_and_relse; } else {//成功后直接返回 sock_put(sk); return 0; } } }
进入tcp_check_req()查看在第三次握手中如何创建新的socket:
/* * Process an incoming packet for SYN_RECV sockets represented as a * request_sock. Normally sk is the listener socket but for TFO it * points to the child socket. * * XXX (TFO) - The current impl contains a special check for ack * validation and inside tcp_v4_reqsk_send_ack(). Can we do better? * * We don't need to initialize tmp_opt.sack_ok as we don't use the results */ struct sock *tcp_check_req(struct sock *sk, struct sk_buff *skb, struct request_sock *req, bool fastopen) { struct tcp_options_received tmp_opt; struct sock *child; const struct tcphdr *th = tcp_hdr(skb); __be32 flg = tcp_flag_word(th) & (TCP_FLAG_RST|TCP_FLAG_SYN|TCP_FLAG_ACK); bool paws_reject = false; bool own_req; tmp_opt.saw_tstamp = 0; if (th->doff > (sizeof(struct tcphdr)>>2)) { tcp_parse_options(skb, &tmp_opt, 0, NULL); if (tmp_opt.saw_tstamp) { tmp_opt.ts_recent = req->ts_recent; /* We do not store true stamp, but it is not required, * it can be estimated (approximately) * from another data. */ tmp_opt.ts_recent_stamp = get_seconds() - ((TCP_TIMEOUT_INIT/HZ)<<req->num_timeout); paws_reject = tcp_paws_reject(&tmp_opt, th->rst); } } /* Check for pure retransmitted SYN. */ if (TCP_SKB_CB(skb)->seq == tcp_rsk(req)->rcv_isn && flg == TCP_FLAG_SYN && !paws_reject) { /* * RFC793 draws (Incorrectly! It was fixed in RFC1122) * this case on figure 6 and figure 8, but formal * protocol description says NOTHING. * To be more exact, it says that we should send ACK, * because this segment (at least, if it has no data) * is out of window. * * CONCLUSION: RFC793 (even with RFC1122) DOES NOT * describe SYN-RECV state. All the description * is wrong, we cannot believe to it and should * rely only on common sense and implementation * experience. * * Enforce "SYN-ACK" according to figure 8, figure 6 * of RFC793, fixed by RFC1122. * * Note that even if there is new data in the SYN packet * they will be thrown away too. * * Reset timer after retransmitting SYNACK, similar to * the idea of fast retransmit in recovery. */ if (!tcp_oow_rate_limited(sock_net(sk), skb, LINUX_MIB_TCPACKSKIPPEDSYNRECV, &tcp_rsk(req)->last_oow_ack_time) && !inet_rtx_syn_ack(sk, req)) { unsigned long expires = jiffies; expires += min(TCP_TIMEOUT_INIT << req->num_timeout, TCP_RTO_MAX); if (!fastopen) mod_timer_pending(&req->rsk_timer, expires); else req->rsk_timer.expires = expires; } return NULL; } /* Further reproduces section "SEGMENT ARRIVES" for state SYN-RECEIVED of RFC793. It is broken, however, it does not work only when SYNs are crossed. You would think that SYN crossing is impossible here, since we should have a SYN_SENT socket (from connect()) on our end, but this is not true if the crossed SYNs were sent to both ends by a malicious third party. We must defend against this, and to do that we first verify the ACK (as per RFC793, page 36) and reset if it is invalid. Is this a true full defense? To convince ourselves, let us consider a way in which the ACK test can still pass in this 'malicious crossed SYNs' case. Malicious sender sends identical SYNs (and thus identical sequence numbers) to both A and B: A: gets SYN, seq=7 B: gets SYN, seq=7 By our good fortune, both A and B select the same initial send sequence number of seven :-) A: sends SYN|ACK, seq=7, ack_seq=8 B: sends SYN|ACK, seq=7, ack_seq=8 So we are now A eating this SYN|ACK, ACK test passes. So does sequence test, SYN is truncated, and thus we consider it a bare ACK. If icsk->icsk_accept_queue.rskq_defer_accept, we silently drop this bare ACK. Otherwise, we create an established connection. Both ends (listening sockets) accept the new incoming connection and try to talk to each other. 8-) Note: This case is both harmless, and rare. Possibility is about the same as us discovering intelligent life on another plant tomorrow. But generally, we should (RFC lies!) to accept ACK from SYNACK both here and in tcp_rcv_state_process(). tcp_rcv_state_process() does not, hence, we do not too. Note that the case is absolutely generic: we cannot optimize anything here without violating protocol. All the checks must be made before attempt to create socket. */ /* RFC793 page 36: "If the connection is in any non-synchronized state ... * and the incoming segment acknowledges something not yet * sent (the segment carries an unacceptable ACK) ... * a reset is sent." * * Invalid ACK: reset will be sent by listening socket. * Note that the ACK validity check for a Fast Open socket is done * elsewhere and is checked directly against the child socket rather * than req because user data may have been sent out. */ if ((flg & TCP_FLAG_ACK) && !fastopen && (TCP_SKB_CB(skb)->ack_seq != tcp_rsk(req)->snt_isn + 1)) return sk; /* Also, it would be not so bad idea to check rcv_tsecr, which * is essentially ACK extension and too early or too late values * should cause reset in unsynchronized states. */ /* RFC793: "first check sequence number". */ if (paws_reject || !tcp_in_window(TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq, tcp_rsk(req)->rcv_nxt, tcp_rsk(req)->rcv_nxt + req->rsk_rcv_wnd)) { /* Out of window: send ACK and drop. */ if (!(flg & TCP_FLAG_RST) && !tcp_oow_rate_limited(sock_net(sk), skb, LINUX_MIB_TCPACKSKIPPEDSYNRECV, &tcp_rsk(req)->last_oow_ack_time)) req->rsk_ops->send_ack(sk, skb, req); if (paws_reject) __NET_INC_STATS(sock_net(sk), LINUX_MIB_PAWSESTABREJECTED); return NULL; } /* In sequence, PAWS is OK. */ if (tmp_opt.saw_tstamp && !after(TCP_SKB_CB(skb)->seq, tcp_rsk(req)->rcv_nxt)) req->ts_recent = tmp_opt.rcv_tsval; if (TCP_SKB_CB(skb)->seq == tcp_rsk(req)->rcv_isn) { /* Truncate SYN, it is out of window starting at tcp_rsk(req)->rcv_isn + 1. */ flg &= ~TCP_FLAG_SYN; } /* RFC793: "second check the RST bit" and * "fourth, check the SYN bit" */ if (flg & (TCP_FLAG_RST|TCP_FLAG_SYN)) { __TCP_INC_STATS(sock_net(sk), TCP_MIB_ATTEMPTFAILS); goto embryonic_reset; } /* ACK sequence verified above, just make sure ACK is * set. If ACK not set, just silently drop the packet. * * XXX (TFO) - if we ever allow "data after SYN", the * following check needs to be removed. */ if (!(flg & TCP_FLAG_ACK)) return NULL; /* For Fast Open no more processing is needed (sk is the * child socket). */ if (fastopen) return sk; /* While TCP_DEFER_ACCEPT is active, drop bare ACK. */ if (req->num_timeout < inet_csk(sk)->icsk_accept_queue.rskq_defer_accept && TCP_SKB_CB(skb)->end_seq == tcp_rsk(req)->rcv_isn + 1) { inet_rsk(req)->acked = 1; __NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPDEFERACCEPTDROP); return NULL; } /* OK, ACK is valid, create big socket and * feed this segment to it. It will repeat all * the tests. THIS SEGMENT MUST MOVE SOCKET TO * ESTABLISHED STATE. If it will be dropped after * socket is created, wait for troubles. */ // 生成child sk, 从ehash中删除req sock ipv4_specific --> tcp_v4_syn_recv_sock child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL, req, &own_req); if (!child) goto listen_overflow; //sk->sk_rxhash = skb->hash; sock_rps_save_rxhash(child, skb); //更新rtt_min,srtt,rto tcp_synack_rtt_meas(child, req); //插入accept队列 return inet_csk_complete_hashdance(sk, child, req, own_req); listen_overflow: if (!sysctl_tcp_abort_on_overflow) { inet_rsk(req)->acked = 1; return NULL; } embryonic_reset: if (!(flg & TCP_FLAG_RST)) { /* Received a bad SYN pkt - for TFO We try not to reset * the local connection unless it's really necessary to * avoid becoming vulnerable to outside attack aiming at * resetting legit local connections. */ req->rsk_ops->send_reset(sk, skb); } else if (fastopen) { /* received a valid RST pkt */ reqsk_fastopen_remove(sk, req, true); tcp_reset(sk); } if (!fastopen) { inet_csk_reqsk_queue_drop(sk, req); __NET_INC_STATS(sock_net(sk), LINUX_MIB_EMBRYONICRSTS); } return NULL; }
重点关注两点:
1 通调用链过tcp_v4_syn_recv_sock --> tcp_create_openreq_child --> inet_csk_clone_lock 生成新sock,状态设置为TCP_SYN_RECV;且tcp_v4_syn_recv_sock通过调用inet_ehash_nolisten将新sock加入ESTABLISHED状态的哈希表中;
2 通过调用inet_csk_complete_hashdance,将新sock插入accept队列.
至此我们得到一个代表本次连接的新sock,状态为TCP_SYN_RECV,接着调用tcp_child_process,进而调用tcp_rcv_state_process:
/* * Queue segment on the new socket if the new socket is active, * otherwise we just shortcircuit this and continue with * the new socket. * * For the vast majority of cases child->sk_state will be TCP_SYN_RECV * when entering. But other states are possible due to a race condition * where after __inet_lookup_established() fails but before the listener * locked is obtained, other packets cause the same connection to * be created. */ int tcp_child_process(struct sock *parent, struct sock *child, struct sk_buff *skb) { int ret = 0; int state = child->sk_state; tcp_segs_in(tcp_sk(child), skb); if (!sock_owned_by_user(child)) { ret = tcp_rcv_state_process(child, skb); /* Wakeup parent, send SIGIO */ if (state == TCP_SYN_RECV && child->sk_state != state) parent->sk_data_ready(parent); } else { /* Alas, it is possible again, because we do lookup * in main socket hash table and lock on listening * socket does not protect us more. */ __sk_add_backlog(child, skb); } bh_unlock_sock(child); sock_put(child); return ret; }
又回到了函数tcp_rcv_state_process,TCP_SYN_RECV状态的套接字将由一下代码处理(只考虑TCP_SYN_RECV部分):
//服务端第三次握手处理 case TCP_SYN_RECV: if (!acceptable) return 1; if (!tp->srtt_us) tcp_synack_rtt_meas(sk, req); /* Once we leave TCP_SYN_RECV, we no longer need req * so release it. */ if (req) { inet_csk(sk)->icsk_retransmits = 0; reqsk_fastopen_remove(sk, req, false); } else { /* Make sure socket is routed, for correct metrics. */ //建立路由,初始化拥塞控制模块 icsk->icsk_af_ops->rebuild_header(sk); tcp_init_congestion_control(sk); tcp_mtup_init(sk); tp->copied_seq = tp->rcv_nxt; tcp_init_buffer_space(sk); } smp_mb(); //正常的第三次握手,设置连接状态为TCP_ESTABLISHED tcp_set_state(sk, TCP_ESTABLISHED); sk->sk_state_change(sk); /* Note, that this wakeup is only for marginal crossed SYN case. * Passively open sockets are not waked up, because * sk->sk_sleep == NULL and sk->sk_socket == NULL. */ //状态已经正常,唤醒那些等待的线程 if (sk->sk_socket) sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT); tp->snd_una = TCP_SKB_CB(skb)->ack_seq; tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale; tcp_init_wl(tp, TCP_SKB_CB(skb)->seq); if (tp->rx_opt.tstamp_ok) tp->advmss -= TCPOLEN_TSTAMP_ALIGNED; if (req) { /* Re-arm the timer because data may have been sent out. * This is similar to the regular data transmission case * when new data has just been ack'ed. * * (TFO) - we could try to be more aggressive and * retransmitting any data sooner based on when they * are sent out. */ tcp_rearm_rto(sk); } else tcp_init_metrics(sk); if (!inet_csk(sk)->icsk_ca_ops->cong_control) tcp_update_pacing_rate(sk); /* Prevent spurious tcp_cwnd_restart() on first data packet */ //更新最近一次发送数据包的时间 tp->lsndtime = tcp_time_stamp; tcp_initialize_rcv_mss(sk); //计算有关TCP首部预测的标志 tcp_fast_path_on(tp); break;
可以看到到代码对socket的窗口,mss等进行设置,以及最后将sock的状态设置为TCP_ESTABLISHED,至此三次握手完成。等待用户调用accept调用,取出套接字使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号