
实验2 多个逻辑段的汇编源程序编写与调试
实验任务1
任务1-1:
(1)task1_1.asm源码
assume ds:data, cs:code, ss:stack data segment db 16 dup(0) data ends stack segment db 16 dup(0) stack ends code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 16 mov ah, 4ch int 21h code ends end start
(2)task1_1调试到line17结束、line19之前截图:
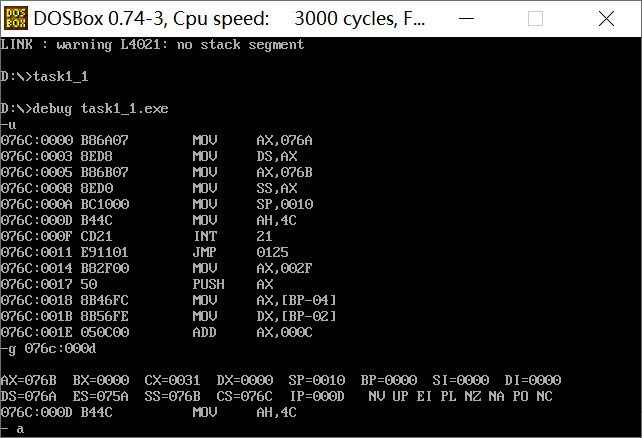
答:① 此时寄存器DS=076A,SS=076B,CS=076C;
② 假设程序加载后,code段的段地址是X,则data段的段地址是X-2h, stack的段地址是X-1h。
原因:数据段和栈段都预留了16B内存,又内存地址=段地址*16+偏移地址,所以相邻段地址相差1h.
任务1-2
任务task1_2.asm源码:
assume ds:data, cs:code, ss:stack data segment db 4 dup(0) data ends stack segment db 8 dup(0) stack ends code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 8 mov ah, 4ch int 21h code ends end start
task1_2调试到line17结束、line19之前观察寄存器DS, CS, SS值的截图:

答:
① 此时寄存器DS=076A,SS=076B,CS=076C;
② 假设程序加载后,code段的段地址是X,则data段的段地址是X-2h, stack的段地址是X-1h。
原因:系统分配段内存以16B为单位,分配的内存为16倍数,不足的会补上,所以此程序数据段和栈段还是预留16B空间;相邻段地址之间相差1h。
任务1-3:
任务task1_3.asm源码:
assume ds:data, cs:code, ss:stack data segment db 20 dup(0) data ends stack segment db 20 dup(0) stack ends code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 20 mov ah, 4ch int 21h code ends end start
task1_3调试到line17结束、line19之前观察寄存器DS, CS, SS值的截图:

答:
① 此时寄存器DS=076A,SS=076C,CS=076E;
② 假设程序加载后,code段的段地址是X,则data段的段地址是X-4h, stack的段地址是X-2h。
原因:分配段内存为16倍数,所以此程序数据段和栈段都预留32B空间;相邻段地址之间相差2h。
任务1-4:
任务task1_4.asm源码:
assume ds:data, cs:code, ss:stack code segment start: mov ax, data mov ds, ax mov ax, stack mov ss, ax mov sp, 20 mov ah, 4ch int 21h code ends data segment db 20 dup(0) data ends stack segment db 20 dup(0) stack ends end start
task1_4调试到line17结束、line19之前观察寄存器DS, CS, SS值的截图:

答:
① 此时寄存器DS=076C,SS=076E,CS=076A;
② 假设程序加载后,code段的段地址是X,则data段的段地址是X+2h, stack的段地址是X+4h。
原因:段之间的地址顺序按照编译顺序分配。
任务1-5:
① 实际分配给该段的内存空间大小是 (ceil)(N/16)*16 (ceil为向上取整)
② 只有task1_4.asm仍然可以正确执行。end start通知了编译器程序的入口在start处,去掉start,可能会导致CS段地址定位错误。task1_4中段顺序为CS,DS,SS,去掉start后CS:IP指向的程序区开头也是代码段,所以程序能正确执行。
汇编程序运行方法:
1、找到一段起始地址为SA:0000(即起始地址的偏移地址为0)的容量足够的空闲内存区。
2、在这段内存区的前256个字节中,创建一个称为程序段前缀(PSP)的数据区,DOS利用PSP来和被加载程序进行通信。
3、从这段内存区的256字节处开始(在PSP的后面),将程序装入,程序的地址被设为SA+10H:0;空闲内存区从SA:0开始,0~255字节为PSP,从256字节处开始存放程序,为更好地区分PSP和程序,DOS将划分到不同的段中,如下这样的地址安排:
空闲内存区:SA:0
PSP区:SA:0
程序区:SA+10H:0
注意:PSP区和程序区虽然物理地址连续,却有不同的段地址。
4、将该内存区的段地址(SA)存入DS中,初始化其它相关寄存器后,设置CS:IP指向程序的入口(SA+10H:0)。
程序装入时ds和cs地址的确定:
1.对于ds,程序装入时ds段地址指向PSP地址,要指向data段,需要在程序中自己赋值;
2.对于cs,cs由end start指定的start来确定段地址;如果没有start,cs:ip指向(SA+10H:0)。
实验任务2:
汇编源代码:
assume cs:code code segment start:mov ax,0b800h mov ds,ax mov bx,0f00h mov cx,80 mov dx,0403h s:mov ds:[bx],dx add bx,2 loop s mov ah,4ch int 21h code ends end start
程序运行后

实验任务3:
源码:
assume cs:code data1 segment db 50, 48, 50, 50, 0, 48, 49, 0, 48, 49 ; ten numbers data1 ends data2 segment db 0, 0, 0, 0, 47, 0, 0, 47, 0, 0 ; ten numbers data2 ends data3 segment db 16 dup(0) data3 ends code segment start: mov bx, 0 ;对应位置的偏移地址 mov ax, data1 mov ds, ax mov cx, 0ah s: mov ax, [bx] add ax, [bx+10h] ;data1和data2的数据相加 mov [bx+20h], ax ;放到data3段中 inc bx loop s mov ah, 4ch int 21h code ends end start
反汇编:

运行前:

运行后:

三行分别为data1、data2、data3段,可以看出对应位置的data1和data2相加并存入了data3中。
实验任务4:
源码:
assume cs:code data1 segment dw 2, 0, 4, 9, 2, 0, 1, 9 data1 ends data2 segment dw 8 dup(?) data2 ends code segment start: mov ax, data1 mov ds, ax mov ax, data1+02h mov ss, ax ;将data2用作栈段 mov sp, 20h ;栈顶指向高地址 mov cx, 8 mov bx, 0 s: push [bx] add bx,2 loop s mov ah, 4ch int 21h code ends end start
反汇编:

运行前:

运行后:

两行分别为段data1和data2,可以看到已经将data1的内容逆序存储到了data2中;同时注意到data1中076A:0b~076A:0f处的值发生了变化,原因是程序中断,将此时的FALG、CS、IP存放在了栈空间
实验任务5:
源码:
assume cs:code, ds:data data segment db 'Nuist' db 2, 3, 4, 5, 6 data ends code segment start: mov ax, data mov ds, ax mov ax, 0b800H mov es, ax mov cx, 5 mov si, 0 mov di, 0f00h s: mov al, [si] and al, 0dfh mov es:[di], al mov al, [5+si] mov es:[di+1], al inc si
add di, 2 loop s mov ah, 4ch int 21h code ends end start
运行结果:

可以看出,底部出现了彩色的NUIST字样;同时data段预留的Nuist被转换成大写与预留的数字(2,3,4,5,6)交替存放在了目标地址。
line19的作用:将0dfh转换成二进制为1101 1111,和其按位与之后第三位变为0,其他位不变;通过ASCII码表可知大小写字母的区别就在于第三位,所以将第三位变为0就是把小写字母转换成大写字母(大写字母不变)。
将line4修改为db 5 dup(2)后的运行结果:

修改为db 5 dup(5)后的结果:
![]()
实验任务6:
源码:
assume cs:code, ds:data data segment db 'Pink Floyd ' db 'JOAN Baez ' db 'NEIL Young ' db 'Joan Lennon ' data ends code segment start: mov ax, data mov ds, ax mov bx, 0 ;行偏移地址 mov cx, 4 ;四行 mov si, 0 ;单词内的字母指针 s1: ;进入外层循环 mov di, cx ;保存外层循环进行次数 mov cx, 4 ;每行首个单词都是4个字母,所以内存循环次数为4次 s2: ;进入内层循环 mov al, [bx+si] ;逐个取出字母 or al, 20h ;和20h按位或转换成小写 mov [bx+si], al ;放回原位置 inc si ;下个字母 loop s2 ;内层循环结束 add bx, 10h ;进入下一行 mov si, 0 ;字母指针清零 mov cx, di ;恢复外层循环测次数 loop s1 ;外层循环结束 mov ah, 4ch int 21h code ends end start
反汇编:
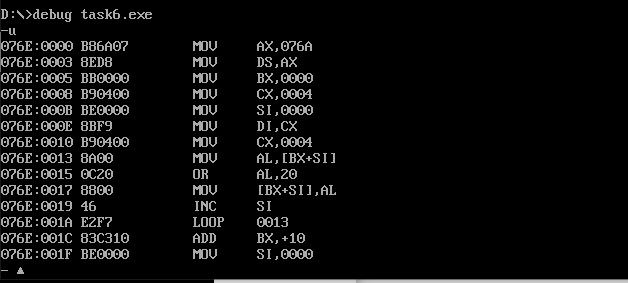
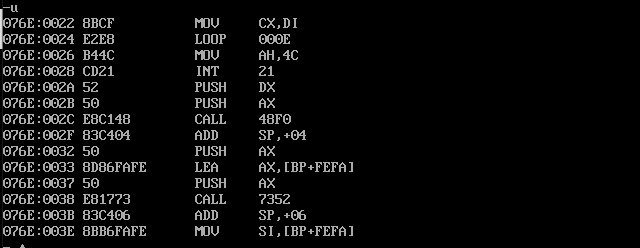
运行结果:

可以看出数据段中每行的首个单词都转换为小写了。
实验任务7:
源码:
assume cs:code, ds:data, es:table data segment db '1975', '1976', '1977', '1978', '1979' dd 16, 22, 382, 1356, 2390 dw 3, 7, 9, 13, 28 data ends table segment db 5 dup( 16 dup(' ') ) ; table ends code segment start: mov ax, data mov ds, ax mov ax, table mov es, ax ;目标table地址 mov bx, 0 ;table的行地址 mov si, 0 ;data段中的数据指针 mov cx, 5 ;每次写5行 mov di, 0 ;table中每行中的指针 ;写入年份 year: ;外循环,每次写一行 mov ax, cx ;保存循环次数 mov cx, 4 ;每行的年份占4字节,按字节写入需4次 year1: ;内循环,每次写一个字节即一个数字 mov dl, ds:[si] ;内存单元间不能直接移动,借dl按字取 mov es:[bx+di], dl inc si ;data中的数据连续,按字取所以+1 inc di ;年份在table中每行的偏移地址为0~3 loop year1 add bx, 10h ;进入下一行 mov di, 0 ;di回到初位置 mov cx, ax ;恢复循环次数 loop year ;写入收入 mov cx, 5 mov bx, 0 mov di, 5 income: mov ax, cx mov cx, 2 ;收入按双字存储,但每次只能取单字,每行需要2次循环 income1: mov dx, ds:[si] ;按字取 mov es:[bx+di], dx add si, 2 ;按字取每次移动2字节 add di, 2 loop income1 add bx, 10h ;下一行 mov di, 5 ;回到每行写入的初位置 mov cx, ax loop income ;写入雇员 mov cx, 5 mov bx, 0 mov di, 0ah employee: mov dx, ds:[si] ;按字取 mov es:[bx+di], dx add si, 2 add bx, 10h loop employee ;写入人均收入 mov cx, 5 mov bx, 0 mov di, 0dh avgincome: mov dx, es:[bx+7] ;被除数为双字即32位,用dx存高16位,ax存低16位 mov ax, es:[bx+5] div word ptr es:[bx+0ah] ;除数为16位,商存在ax中,余数存在dx中 mov es:[bx+di], ax add bx, 10h loop avgincome mov ah, 4ch int 21h code ends end start
查看table段原始数据信息截图:
运行后截图:
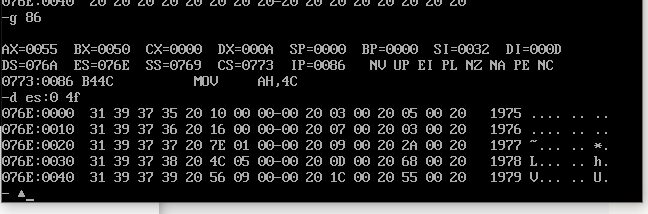
可以看到数据段中的数据已经按结构存到table段中了,且人均收入的计算结果正确。
