编译器设计文档
一、参考编译器介绍
我并没有过多的参考往届学长的编译作品,主要有如下原因:
- 课程组发的资料已经比较完备
- 自己的设计思路比较清晰,没有很多的困惑
- 由于我想要先通过生成llvm ir,再生成mips代码,而往届学长中,基本上都是自行设计的中间代码格式。参考的意义较小
我个人主要参考的资料有:
- 课程组的编译实验参考手册
- 课程组提供的往届北航软院的生成llvm ir的相关资料
- 南京大学编译课的相关资料
二、编译器总体设计
编译器使用Java语言实现。集中实现了词法分析、语法分析、错误处理、中间代码生成、目标代码生成。
控制流图

注:这里暂不涉及有关优化的部分。关于优化,详见七. 代码优化设计。
文件结构
src
├── Compiler.java 程序入口
├── main
│ ├── exceptions 错误处理的各个异常类型
│ │ ├── ErrorReporter.java
│ │ ├── ExceptionNeededReport.java
│ │ ├── FuncMissingRetStmt_G.java
│ │ ├── FuncParamsNumNotMatch_D.java
│ │ ├── FuncParamsTypeNotMatch_E.java
│ │ ├── IdentRedifinition_B.java
│ │ ├── MissingRBracket_K.java
│ │ ├── MissingRParenthesis_J.java
│ │ ├── MissingSemicolon_I.java
│ │ ├── PrintfArgNumNotMatch_L.java
│ │ ├── SettingConstLVal_H.java
│ │ ├── UndefinedIdent_C.java
│ │ ├── UsingLoopTermInNonLoopBlock_M.java
│ │ ├── VoidFuncWithWrongRetType_F.java
│ │ └── WrongChar_A.java
│ ├── IdentObject.java
│ ├── LabelAllocator.java
│ ├── Llvm_Instr.java
│ ├── LoopLabels.java
│ ├── mips 由已经生成的llvm ir生成mips代码的处理模块
│ │ ├── FuncDefs.java
│ │ ├── MipsCode.java
│ │ └── MipsUnit.java
│ ├── MyException.java
│ ├── output 对于输出的包装
│ │ ├── LexicalOutput.java
│ │ ├── LlvmOutput.java
│ │ ├── MyOutput.java
│ │ ├── MyOutputManager.java
│ │ └── SyntaxOutput.java
│ ├── Parsable.java
│ ├── Parser.java
│ ├── RetObject.java
│ ├── RetObjType.java
│ ├── State.java
│ ├── SymTable.java
│ └── VarAllocator.java
└── parsable 递归下降分析的各个子成分(非终结符)。其中每个实体类都继承自Parsable
├── others
│ ├── Char.java
│ ├── FormatChar.java
│ ├── FormatString.java
│ ├── Ident.java
│ └── NormalChar.java
└── syntax_content 在语法分析时,需要进行输出的各个成分。
├── BlockItem.java
├── Block.java
├── BType.java
├── CompUnit.java
├── Cond.java
├── ConstDecl.java
├── ConstDef.java
├── ConstExp.java
├── ConstInitVal.java
├── Decl.java
├── EqExp.java
├── exps 进行常量传播时的涉及到的类。其中每个实体类都继承自AbstractExp
│ ├── AbstractExp.java
│ ├── AddExp.java
│ ├── Exp.java
│ ├── MulExp.java
│ ├── PrimaryExp.java
│ └── UnaryExp.java
├── FuncDef.java
├── FuncFParam.java
├── FuncFParams.java
├── FuncRParams.java
├── FuncType.java
├── InitVal.java
├── LAndExp.java
├── LOrExp.java
├── LVal.java
├── MainFuncDef.java
├── Number.java
├── RelExp.java
├── Stmt.java
├── UnaryOp.java
├── VarDecl.java
└── VarDef.java
三、词法分析设计
注:
报告要求书写编码前的设计和编码完成之后对设计的修改情况,但实际上:
- 对于不太复杂的编译阶段,因为编码前的设计阶段比较完善周到,所以在编码过程中,并没有特别多的修改。
- 对于比较复杂的编译阶段,“先完成所有的设计、再完成所有的编码”这一策略也难度较大、不好实施,所以我基本上是设计和编码这两者同步进行、相辅相成、相互促进的。因此,也不太好描述“编码完成后对设计的修改”。
综合上述两点,下面直接给出设计思路和编码结果。后面的各个阶段,如无特殊说明,也是如此。
设计思路
源文件中的“token”可以分为以下几类:
- 数字。例:
123,3,233444422,03 - identifier。例:
arr1,__t,tmp,M_1 - 单字符构成的符号。例:
-,+,[,{ - 双字符构成的符号。例:
&&,>=
同时,在词法分析时,应该将单行注释、多行注释、空白符给过滤掉。
编码结果
通过以上分析,得到函数(这部分主要由Parser这一工具类中的getCurToken()方法实现)实现如下:
public static String getCurToken() throws Exception {
int tokenLen = 0;
// 过滤空白符和注释
if (filterBC()) {
throw new MyException("getCurToken时,已经读到了文件末尾");
}
// 读取数字:123,3,233444422,03
if (isDigit(input[pos])) {
while (pos + tokenLen < Parser.len && isDigit(input[pos + tokenLen])) {
tokenLen++;
}
return String.valueOf(input, pos, tokenLen);
}
// 读取类似 arr1,__t,tmp,M_1 这样的identifier(注意!identifier的第一位不是数字)
if (isIdentChar(input[pos])) {
while (pos + tokenLen < Parser.len && isIdentChar(input[pos + tokenLen])) {
tokenLen++;
}
return String.valueOf(input, pos, tokenLen);
}
// 考虑所有双字符构成的token
if (pos + 2 <= Parser.len && String.valueOf(input, pos, 2).matches("==|!=|>=|<=|&&|\\|\\|")) {
return String.valueOf(input, pos, 2);
}
return String.valueOf(input[pos]);
}
同时,针对编译实验中词法分析的评测题目,对于每一个“token”,将输出的格式封装,如下:
package main.output;
public abstract class LexicalOutput {
public static void AND() {
MyOutputManager.lex.sb.append("AND &&\n");
}
public static void OR() {
MyOutputManager.lex.sb.append("OR ||\n");
}
public static void PLUS() {
MyOutputManager.lex.sb.append("PLUS +\n");
}
public static void MINU() {
MyOutputManager.lex.sb.append("MINU -\n");
}
public static void VOIDTK() {
MyOutputManager.lex.sb.append("VOIDTK void\n");
}
public static void MULT() {
MyOutputManager.lex.sb.append("MULT *\n");
}
public static void DIV() {
MyOutputManager.lex.sb.append("DIV /\n");
}
public static void MOD() {
MyOutputManager.lex.sb.append("MOD %\n");
}
public static void LSS() {
MyOutputManager.lex.sb.append("LSS <\n");
}
public static void LEQ() {
MyOutputManager.lex.sb.append("LEQ <=\n");
}
public static void GRE() {
MyOutputManager.lex.sb.append("GRE >\n");
}
public static void GEQ() {
MyOutputManager.lex.sb.append("GEQ >=\n");
}
public static void EQL() {
MyOutputManager.lex.sb.append("EQL ==\n");
}
public static void NEQ() {
MyOutputManager.lex.sb.append("NEQ !=\n");
}
public static void ASSIGN() {
MyOutputManager.lex.sb.append("ASSIGN =\n");
}
public static void SEMICN() {
MyOutputManager.lex.sb.append("SEMICN ;\n");
}
public static void COMMA() {
MyOutputManager.lex.sb.append("COMMA ,\n");
}
public static void LPARENT() {
MyOutputManager.lex.sb.append("LPARENT (\n");
}
public static void RPARENT() {
MyOutputManager.lex.sb.append("RPARENT )\n");
}
public static void LBRACK() {
MyOutputManager.lex.sb.append("LBRACK [\n");
}
public static void RBRACK() {
MyOutputManager.lex.sb.append("RBRACK ]\n");
}
public static void LBRACE() {
MyOutputManager.lex.sb.append("LBRACE {\n");
}
public static void RBRACE() {
MyOutputManager.lex.sb.append("RBRACE }\n");
}
public static void IDENFR(String ident) {
MyOutputManager.lex.sb.append("IDENFR ").append(ident).append('\n');
}
public static void INTCON(String intcon) {
MyOutputManager.lex.sb.append("INTCON ").append(intcon).append('\n');
}
public static void STRCON(String formatStr) {
MyOutputManager.lex.sb.append("STRCON ").append(formatStr).append('\n');
}
public static void MAINTK() {
MyOutputManager.lex.sb.append("MAINTK main\n");
}
public static void CONSTTK() {
MyOutputManager.lex.sb.append("CONSTTK const\n");
}
public static void INTTK() {
MyOutputManager.lex.sb.append("INTTK int\n");
}
public static void BREAKTK() {
MyOutputManager.lex.sb.append("BREAKTK break\n");
}
public static void CONTINUETK() {
MyOutputManager.lex.sb.append("CONTINUETK continue\n");
}
public static void IFTK() {
MyOutputManager.lex.sb.append("IFTK if\n");
}
public static void ELSETK() {
MyOutputManager.lex.sb.append("ELSETK else\n");
}
public static void NOT() {
MyOutputManager.lex.sb.append("NOT !\n");
}
public static void WHILETK() {
MyOutputManager.lex.sb.append("WHILETK while\n");
}
public static void GETINTTK() {
MyOutputManager.lex.sb.append("GETINTTK getint\n");
}
public static void PRINTFTK() {
MyOutputManager.lex.sb.append("PRINTFTK printf\n");
}
public static void RETURNTK() {
MyOutputManager.lex.sb.append("RETURNTK return\n");
}
}
四、语法分析设计
设计思路
针对每一个非终结符,都是通过递归下降法来对其进行分析。因此,可以将每一个非终结符单独写成一个类,继承自Parsable接口(Parsable接口表示其是一个可以进行递归下降分析的非终结符)。
同时,针对分析时“不知道走拿一条路”的情况,我采用的是回溯的方式。
具体而言,对于一个较复杂的文法,例如:
FuncFParam → BType Ident ['[' ']' { '[' ConstExp ']' }]
其分析的流图如下:
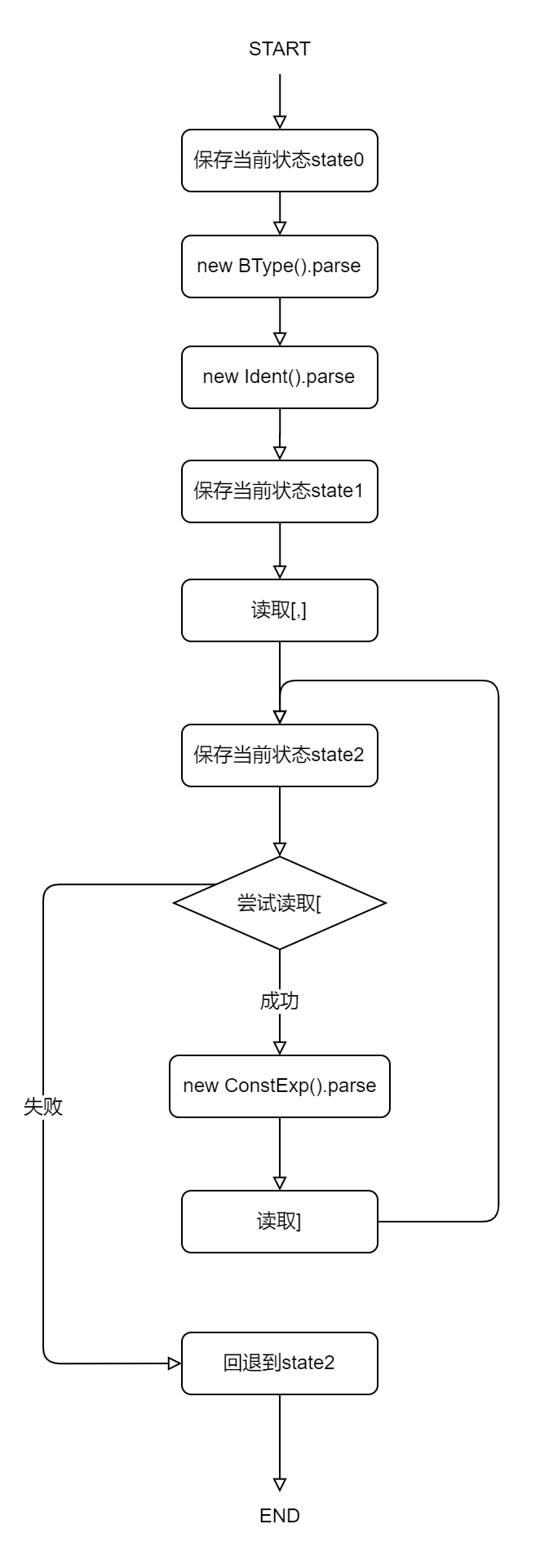
编码结果
Parsable接口中(注:只展示其中与语法分析相关的部分):
public abstract class Parsable {
// parse的过程中,需要保存的state
// state包括pos,line两个信息
private final State[] savedState = new State[5];
abstract public RetObject parse() throws Exception;
public void saveState(int i); // 保存此时状态为第i个状态
public void saveState() { // 参数缺省时表示i=0
saveState(0);
}
public void rollback(int i); // 回退到第i个状态
public void rollback() { // 参数缺省时表示i=0
rollback(0);
}
}
例如,对于函数形参的文法:
FuncFParam → BType Ident ['[' ']' { '[' ConstExp ']' }]
其代码如下:
package parsable.syntax_content;
import main.LexicalOutput;
import main.MyException;
import main.Parsable;
import main.Parser;
import main.SyntaxOutput;
import parsable.others.Ident;
public class FuncFParam extends Parsable {
@Override
public Object parse() throws Exception { //
// FuncFParam → BType Ident ['[' ']' { '[' ConstExp ']' }]
// 标记点: 1 2
saveState();
try {
new BType().parse();
new Ident().parse();
saveState(1); // 设置标记点1
try {
if (Parser.getCurToken().equals("[") && Parser.getNextToken(1).equals("]")) {
Parser.readCurToken("[");
Parser.readCurToken("]");
LexicalOutput.LBRACK();
LexicalOutput.RBRACK();
saveState(2);
try {
while (Parser.readCurToken("[")) {
LexicalOutput.LBRACK();
new ConstExp().parse();
if (!Parser.readCurToken("]")) {
throw new MyException("没读到]");
}
LexicalOutput.RBRACK();
saveState(2);
}
} catch (Exception e) {
rollback(2);
}
}
} catch (Exception e) {
rollback(1); // 回退到标记点1
}
} catch (Exception e) {
rollback();
throw e;
}
SyntaxOutput.out(this);
return null;
}
}
五、中间代码生成设计
注:
正如上图所示,代码生成设计和错误处理设计两者没有很强的前置、后置关系(当然,也有共同涉及的部分:都需要建立符号表并管理)。在我实际写编译器的过程中,是先完成的目标代码生成,后完成的错误处理。故在文档介绍中也沿用我实际编写的顺序,先介绍代码生成设计,后介绍错误处理设计。
设计思路
语法制导翻译
我们在进行词法分析、语法分析的过程中,实际上已经生成了语法树。
注:语法树的一个例子如下。
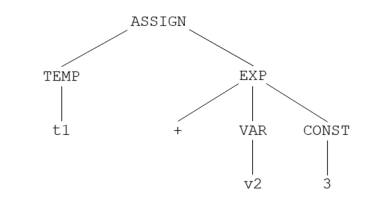
接下来,主要思路就是,遍历语法树中的每一个结点,当发现语法树中有特定的结构出现时,就产生出相应的中间代码。中间代码的生成的核心就是语法制导翻译。
具体到代码上,我们可以为每个主要的语法单元“X”都设计相应的翻译函数“translate_X”,这个函数的返回值里面装着这个X语法单元生成的中间代码,对语法树的遍历过程也就是这些函数之间互相调用的过程。
最终,我们只需要获取开始符号CompUnit的translate函数的返回值即可。
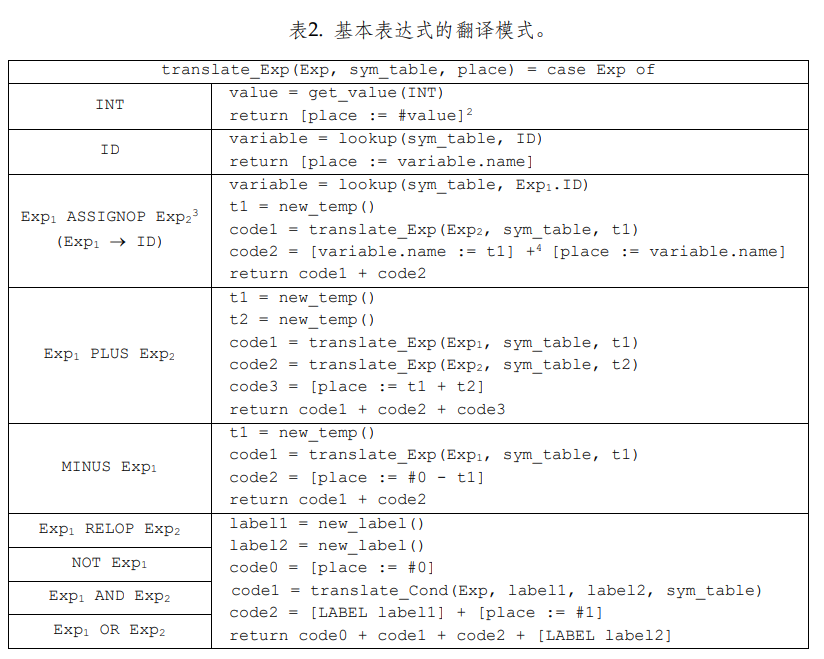



符号表SymTable
此外,还需要生成符号表SymTable,里面应该包含如下信息:
- 一个HashMap,存放每个标识符的名字和对应的标识符对象IdentObject。在进行分析的时候,从IdentObject里面获取这个identifier的相关信息。
- 这个符号表的父符号表对象。(通过这样,来实现不同作用域identifier的覆盖)
标识符对象IdentObject
IdentObject中应该包含如下信息:
- 类型(int变量,数组,函数)
- 是否有const限定符
- 值(对于常量,有时需要直接获取其值)
- 分配到的var(在llvm ir中,var就是形如%4的这种变量)
函数传递参数时的处理
传递参数时,按照C语言的规范,在下面的例子中:
void f(int af[])
{
}
int main()
{
int ar[3] = {1,2,3};
f(ar);
return 0;
}
ar的类型是int [3],af的类型是int*。
在我的编译器中,也实现了类似的规范。在函数参数传递的过程中,需要将ObjType转换为VarType进行传递。
objType:
"void" "i32" 函数
"i32" 非数组
"i32[6]" 1维数组
"i32[7][9]" 2维数组
"i32*" 函数参数中的“一维数组”
"[%d x i32]*" 函数参数中的“二维数组”
valueType:
"void" "i32" 函数
"i32" 非数组
"i32*" 1维数组
"[%d x i32]*" 2维数组
"i32*" 函数参数中的“一维数组”
"[%d x i32]*" 函数参数中的“二维数组”
再举一个例子
int ag[5];
int mg[5][4];
void v(int i, int a[], int m[][4])
{
}
int main()
{
return 0;
}
其中各个变量对应的ObjType为:
i: i32
a: i32*
m: [4 x i32]*
ag: i32[5]
mg: i32[5][4]
编码结果
语法制导翻译
以FuncFParam → BType Ident ['[' ']' { '[' ConstExp ']' }]为例:
package parsable.syntax_content;
import main.IdentObject;
import main.RetObject;
import main.SymTable;
import main.output.LexicalOutput;
import main.MyException;
import main.Parsable;
import main.Parser;
import main.output.SyntaxOutput;
import parsable.others.Ident;
public class FuncFParam extends Parsable {
public FuncFParam(SymTable symTable) {
super(symTable);
}
@Override
public RetObject parse() throws Exception { //
// FuncFParam → BType Ident ['[' ']' { '[' ConstExp ']' }]
// 标记点: 1 2
saveState();
try {
new BType(symTable).parse();
RetObject ro2 = new Ident(symTable, true, false).parse();
IdentObject io = symTable.addIdent(ro2.getStr(),"int",false);
ro.getLlvm_ir().append(String.format("i32 %s", io.getVar()));
// ro.getLlvm_ir().append(String.format("i32"));
ro.setStr(ro2.getStr());
ro.setValueType("i32");
saveState(1); // 设置标记点1
try {
if (Parser.getCurToken().equals("[") && Parser.getNextToken(1).equals("]")) {
Parser.readCurToken("[");
Parser.readCurToken("]");
LexicalOutput.LBRACK();
LexicalOutput.RBRACK();
saveState(2);
try {
while (Parser.readCurToken("[")) {
LexicalOutput.LBRACK();
new ConstExp(symTable).parse();
if (!Parser.readCurToken("]")) {
throw new MyException("没读到]");
}
LexicalOutput.RBRACK();
saveState(2);
}
} catch (Exception e) {
rollback(2);
}
}
} catch (Exception e) {
rollback(1); // 回退到标记点1
}
} catch (Exception e) {
rollback();
throw e;
}
SyntaxOutput.out(this);
return ro;
}
}
符号表SymTable
package main;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
public class SymTable {
private final HashMap<String, IdentObject> name2IdentObj = new HashMap<>(); // 存放标识符的<名字,标识符对象>
private final ArrayList<String> names = new ArrayList<>();
private final SymTable upperSymTable; // 上一级的符号表
public SymTable(SymTable upperSymTable) {
this.upperSymTable = upperSymTable;
}
public IdentObject addIdent(String name, String type, boolean isConst, boolean isFunc) {
String var = (isGlobal() || isFunc) ? "@" + name : VarAllocator.allocateAVar();
IdentObject newIdent = new IdentObject(name, var, type, isConst, isFunc);
if (name2IdentObj.containsKey(name)) {
name2IdentObj.remove(name);
names.remove(name);
}
name2IdentObj.put(name, newIdent);
names.add(name);
return newIdent;
}
public IdentObject addIdent(String name, String type, boolean isConst, boolean isFunc, Object value) {
IdentObject newIdent = addIdent(name, type, isConst, isFunc);
if (value instanceof Integer) {
newIdent.setValue((Integer) value);
} else {
// 说明是数组
newIdent.setVals(value);
}
return newIdent;
}
public IdentObject addIdent(String name, String type, boolean isConst, boolean isFunc, List<String> fParamsType) {
IdentObject newIdent = addIdent(name, type, isConst, isFunc);
newIdent.setFuncParamsType(fParamsType);
return newIdent;
}
public void recover(int oldsize) {
// 只在本级的符号表中删除到只剩oldsize个(不涉及删除父亲符号表)
String s;
while (names.size() > oldsize) {
s = names.remove(names.size() - 1);
name2IdentObj.remove(s);
}
}
/**
* 在该符号表(及其逐层父符号表)中,寻找名为 name 的符号的类型。
*
* @param name
* @param isRecursive false表示仅查找当前层的符号表,true表示除了当前符号表要查,还要递归查找所有父符号表
* @return 名为 name 的符号的IdentObject(如果不存在,则返回null)
*/
public IdentObject getIdent(String name, boolean isRecursive) {
IdentObject io = name2IdentObj.getOrDefault(name, null);
if (io == null && isRecursive && upperSymTable != null) {
io = upperSymTable.getIdent(name, true);
}
return io;
}
public int size() {
return names.size();
}
public SymTable getUpperSymTable() {
return upperSymTable;
}
/**
* @return 是否为全局变量的符号表
*/
public boolean isGlobal() {
return upperSymTable == null;
}
}
标识符对象IdentObject
package main;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class IdentObject {
private final String name; // 标识符的名字,例如a
private final String var; // 分配到的变量的符号或者number,例如3,%1
private final boolean isFunc; // 是否是函数
private final String objType; // 该变量的类型(和RetObject的ValueType的字段的格式是不一致的)
// 若为函数,则type为函数的返回值。eg:"i32" "void",函数的形参的信息存放在funcParams字段中
// 若不是函数,则type的例子:
// "i32" 非数组
// "i32[6]" 1维数组
// "i32[7][9]" 2维数组
private final boolean isConst;
// private ArrayList<String> funcParams = new ArrayList<>(); // 函数参数列表。
private List<String> funcParamsType = new ArrayList<>(); // 函数参数的类型列表。
private Integer value = null; // 有时(ConstExp)需要直接获取该ident的值
private Object vals; // 数组。类型可能为String[], String[][],
public IdentObject(String name, String var, String type, boolean isConst, boolean isFunc) {
this.name = name;
this.var = var;
this.objType = type;
this.isConst = isConst;
this.isFunc = isFunc;
}
public List<String> getFuncParamsType() {
return funcParamsType;
}
public void setFuncParamsType(List<String> funcParamsType) {
this.funcParamsType = funcParamsType;
}
public Integer getValue() throws MyException{
return value;
}
public void setValue(Integer value) {
this.value = value;
}
public String getName() {
return name;
}
public String getVar() {
return var;
}
public String getObjType() {
return objType;
}
/**
* 如果是数组,则返回第一维度长度。否则返回-1
*
* @return
*/
public int getLen1() {
Pattern p2d = Pattern.compile("^i32\\[(\\d+)]\\[(\\d+)]$");
Pattern p1d = Pattern.compile("^i32\\[(\\d+)]$");
Matcher m1d = p1d.matcher(objType);
Matcher m2d = p2d.matcher(objType);
if (m1d.find()) {
return Integer.parseInt(m1d.group(1));
}
if (m2d.find()) {
return Integer.parseInt(m2d.group(1));
} else {
return -1;
}
}
/**
* 如果是二维数组,则返回第二维的长度。否则返回-1
*
* @return
*/
public int getLen2() {
Pattern p2d = Pattern.compile("^i32\\[(\\d+)]\\[(\\d+)]$");
Matcher m2d = p2d.matcher(objType);
if (m2d.find()) {
return Integer.parseInt(m2d.group(2));
} else {
return -1;
}
}
/**
* 如果是数组,则返回其维数,否则返回0。
* @return
*/
public int getDim() {
if (getLen2() > 0) {
return 2;
}
if (getLen1() > 0) {
return 1;
}
return 0;
}
public boolean isConst() {
return isConst;
}
public boolean isFunc() {
return isFunc;
}
public Object getVals() {
return vals;
}
public void setVals(Object vals) {
this.vals = vals;
}
}
六、目标代码生成设计
设计思路
在五、中间代码生成设计中,已经将输入程序翻译为llvm中间代码。这些中间代码,在很大程度上已经可以很容易地翻译成我们最终的mips机器代码,不过仍然存在以下问题:
- 中间代码与目标代码之间并不是严格一一对应的。有可能某条中间代码对应多条目标代码,也有可能多条中间代码对应一条目标代码。
- 中间代码中我们使用了数目不受限的变量和临时变量,但处理器所拥有的寄存器数量是有限的。RISC机器的一大特点就是运算指令的操作数总是从寄存器中获得。
- 中间代码中我们并没有处理有关函数调用的细节。函数调用在中间代码中被抽象为一条CALL语句,但在mips代码中,显然需要有“传参”的过程,其中必然涉及到有关栈帧的操作。
以上三个点分别对应三个问题:指令选择,寄存器分配,栈管理。
指令选择
综合llvm ir和mips的指令集,进行一些整体上的指令选择思考。对于不同的llvm ir,有:
- 算术类:
%v4 = add i32 %v3, 2345,可以直接与mips的add指令对应 - 访存类:
store i32 %v5, i32* %v3,则与mips的sw对应。- 还有一个访存中间代码,是形如
%v16 = getelementptr i32, i32* %v10, i32 5的这种getelementptr比较特殊,需要根据具体情况进行一些处理。
- 还有一个访存中间代码,是形如
- 跳转类:
br i1 %v5, label %l4, label %l3,则与mips的beq,b等指令对应。 - 比较类:
%v5 = icmp eq i32 %v4, 4,则与mips的seq指令对应。 - 调用函数:
%v6 = call i32 @f1(i32 %v13),这个在mips中,需要一系列对于栈的操作指令+jal指令。 - 其他:
zext, label等。需要各自针对其特点进行特殊处理。
寄存器分配
RISC机器的一个很显著的特点是,除了load/store型指令之外,其余指令的所有操作数都必须来自寄存器而不是内存。除了数组和结构体必须放到内存中之外,中间代码里的任何一个 非零变量或临时变量,只要它参与运算,其值必须被载入到某个寄存器中。在某个特定的程序 点上选择哪个寄存器来保存哪个变量的值,这就是寄存器分配所要研究的问题。
在最初完成的时候,先选用最简单的朴素寄存器分配算法。其思想是:将所有的变量或临时变量都放在内存里。 如此一来,每翻译一条中间代码之前我们都需要把要用到的变量先加载到寄存器中,得到该代码的计算结果之后又需要将结果写回内存。
栈管理
注:在过程式程序设计语言中,函数调用包括控制流转移和数据流转移两个部分。控制流转移指的是将程序计数器PC当前的值保存到$ra中然后跳转到目标函数的第一句处,这件事情已经由硬件帮我们做好,我们可以直接使用jal指令实现。因此,编译器编写者在目标代码生成时所 需要考虑的问题是如何在函数的调用者与被调用者之间进行数据流的转移。当一个函数被调用 时,调用者需要为这个函数传递参数,然后将控制流转移到被调用函数的第一行代码处;当被调用函数返回时,被调用者需要将返回值保存到某个位置,然后将控制流转移回调用者处。在 MIPS32中,函数调用使用jal指令,函数返回使用jr指令。参数传递采用寄存器与栈相结合的 方式:如果参数少于4个,则使用$a0至$a3这四个寄存器传递参数;如果参数多于4个,则前4 个参数保存在$a0至$a3中,剩下的参数依次压到栈里。返回值的处理方式则比较简单,由于我 们约定C−−中所有函数只能返回一个整数,因此直接将返回值放到$v0中即可,$v1可以挪作它用。
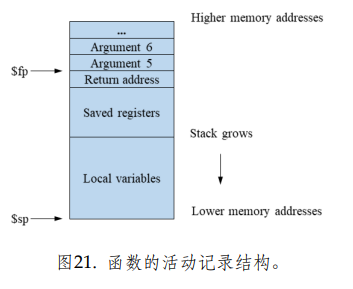
栈指针$sp指向栈的顶部,帧指针$fp指向当前活动记录的底部。假设图中栈顶为 上方而栈底为下方,则$fp之下是传给本函数的参数(只有多于4个参数时这里才会有内容), 而$fp之上是返回地址、被调用者保存的寄存器内容以及局部数组、变量或临时变量。这个活 动记录的布局并不是唯一可行的,不同的体系结构之间布局不尽相同,同一体系结构的在不同 的介绍中也可能不一样,这里并没有一个统一的标准。理论上来讲只要能将应该保存的内容都 存下来,并且能够正确地将它们都取出来就行。你的程序不必完全遵循上图中的布局方式。
在栈的管理中,有一个栈指针$sp其实已经足够了,$fp并不是必需的,前面也提到过某些 编译器甚至将$fp挪用作$s8。引入$fp主要是为了方便访问活动记录中的内容:在函数的运行 过程中,$sp是会经常发生变化的(例如,当压入新的临时变量、压入将要调用的另一个函数的参数、或者想在栈上保存动态大小的数组时),根据$sp来访问栈帧里保存的局部变量比较麻烦,因为这些局部变量相对于$sp的偏移量会经常改变。而在函数内部$fp一旦确定就不再变化,所以根据$fp访问局部变量时并不需要考虑偏移量的变化问题。
如果一个函数f调用了另一个函数g,我们称函数f为调用者(Caller),函数g为被调用者 (Callee)。mips约定$t0至$t9由调用者负责保存,而$s0-$s8由被调用者负责 保存。从调用关系的角度看,调用者负责保存的寄存器中的值在函数调用前后有可能会发生改 变,被调用者负责保存的寄存器中的值在函数调用的前后则一定不会发生改变。这也就启示我们,$t0至$t9应该尽量分配给那些短期使用的变量或临时变量,而$s0至$s9应当尽量分配给那些生存期比较长,尤其是生存期跨越了函数调用的变量或临时变量。(不过,对于朴素寄存器分配策略,其实完全不用考虑这一点,因为所有寄存器都不需要保存。)
总之,要明确两个跟栈有关的寄存器:
$sp。在生成目标代码的过程中,不同的变量需要存放在栈上不同位置。$fp。在每一个函数中,$fp的值是确定的。
注:一种可行的栈空间规划方式如下
具体而言:
-
call fun时:
-
1. sw $t0, 0($sp) sw $t1, 4($sp) ... sw $t9, 36($sp) move $a0, para1 ... move $a3, para4 sw para5, 40($sp) sw para6, 44($sp) ... sub $sp, $sp, 4*k+40 # 设有k个入栈的参数 2. jal fun 3. add $sp, $sp, 4*k+40
-
-
callee的开头:
-
1. sw $fp, 4($sp) # 先把caller的$fp存起来! move $fp, sp sw $ra, 0($fp) 2. sw $s0, 12($fp) ... sw $s7, 40($fp) add $sp, $sp, 44
-
-
callee的结尾:
-
1. lw $ra, 0($fp) move $sp, $fp 2. lw $s0, 12($fp) ... lw $s7, 40($fp) lw $fp, 4($fp) # 一定要放在最后! 3. jr $ra
-
注:
当时的手稿,陪伴我度过了几个夜晚。感觉很有质感(hh),贴上来留个纪念。

编码结果
在工具类FuncDefs中完成。此类中的字段和方法如下:

此类的源代码:
package main.mips;
import main.MyException;
import main.Parser;
import main.VarAllocator;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public abstract class FuncDefs {
private static final ArrayList<StringBuilder> funcDefs = MipsUnit.funcDefs;
private static final StringBuilder mainFuncDef = MipsUnit.mainFuncDef;
private static final HashMap<String, Integer> glbCon2addr = MipsUnit.glbCon2addr; // Key有前缀@
// private static final HashSet<String> flag = new HashSet<>(); // 存放那些getelementptr的var
private static final int savedNum = -1; //
// 下面这几个相当于全局变量
private static HashMap<Integer, Integer> id2offset = new HashMap<>(); // 记录每一个var相对于$fp的偏移; // 这里的offset以大于零为增长
// private static HashMap<Integer, Integer> id2addr = new HashMap<>(); // 这里的offset以大于零为增长。alloca出来的var对应的绝对地址
private static Integer offset2fp;
private static StringBuilder curFuncDef;
private static int argMaxId;
/**
* 把 %var 的值存到 reg 里
*/
private static void loadVar2Reg(String varStr, String reg) {
if (varStr.startsWith("%v")) {
int var = VarAllocator.parseVarNum(varStr);
if (var < 4 && var <= argMaxId) {
// 从$a0-$a3里获取
curFuncDef.append(MipsCode.move(reg, "$a" + var));
} else {
// 从栈中获取
curFuncDef.append(MipsCode.lw(reg, "$fp", -id2offset.get(var)));
}
} else if (varStr.startsWith("@")){
// @arr, @m。只要是全局变量(不管是不是数组),都直接la指令就可以
curFuncDef.append(MipsCode.la(reg, varStr));
} else {
curFuncDef.append(MipsCode.li(reg, Integer.parseInt(varStr)));
}
}
/**
* 获取var在栈中的地址,并将其存到reg里
*/
private static void loadVar2RegG(String varStr, String reg) {
if (varStr.startsWith("%v")) {
int var = VarAllocator.parseVarNum(varStr);
if (var < 4 && var <= argMaxId) {
// 从$a0-$a3里获取
curFuncDef.append(MipsCode.move(reg, "$a" + var));
System.err.println("出了小问题1");
} else {
// 从栈中获取
curFuncDef.append(MipsCode.add(reg, "$fp", -id2offset.get(var)));
}
} else {
// @arr
System.err.println("出了小问题2");
curFuncDef.append(MipsCode.li(reg, glbCon2addr.get(varStr)));
}
}
/**
* 把 reg 存到 一个新的%var中,并在id2offset中存入var的地址映射信息
*
* @param reg
* @param varStr
*/
private static void storeReg2Var(String reg, String varStr) {
int var = VarAllocator.parseVarNum(varStr);
curFuncDef.append(MipsCode.sw(reg, "$fp", -offset2fp));
id2offset.put(var, offset2fp);
offset2fp += 4;
}
private static void storeReg2VarG(String reg, String varStr) {
storeReg2Var(reg, varStr);
// flag.add(varStr);
}
public static void genFuncDef() throws Exception {
if (!Parser.readLine("; define")) {
throw new MyException("没读到; define");
}
Pattern p = Pattern.compile("define dso_local (void|i32) @([a-zA-Z0-9_]+)\\((.*)\\) \\{");
Matcher m;
while (true) {
String curFuncDefLine = Parser.getLine(true);
m = p.matcher(curFuncDefLine);
if (!m.find()) {
// 说明读到了 ; main
break;
}
Parser.readLine();
curFuncDef = new StringBuilder();
funcDefs.add(curFuncDef);
String funcRetType = m.group(1); // 这个没用到,因为在函数最后一句时,type会再次出现
String funcName = m.group(2); // funcName不带有@前缀
String[] funcParams = m.group(3).split(", ");
curFuncDef.append(funcName).append(":\n");
// callee的开头
curFuncDef.append(MipsCode.sw("$fp", "$sp", -4)); // 先把caller的$fp存起来
curFuncDef.append(MipsCode.move("$fp", "$sp"));
curFuncDef.append(MipsCode.sw("$ra", "$fp", -0));
// final int savedNum = -1; // 最多可以设置为7,表示保存0-7这8个寄存器。savedNum为-1表示不保存任何寄存器
for (int i = 0; i <= savedNum; i++) {
curFuncDef.append(MipsCode.sw("$s" + i, "$sp", -(4 * i + 12)));
}
offset2fp = 4 * (savedNum + 4); // 用于记录各种var相对$fp的偏移
// curFuncDef.append(MipsCode.sub("$sp", "$sp", offset2fp));
// callee真正的函数体
curFuncDef.append(String.format("# callee %s start!\n", funcName));
realFuncPart(funcParams);
Parser.readLine();
}
}
public static void realFuncPart(String[] funcParams) throws Exception {
// callee的函数体
argMaxId = funcParams.length - 1;
if (funcParams.length > 4) {
// 有入栈的参数
int off = -4;
for (int i = argMaxId; i >= 4; i--) {
// 注意:我们是以栈的增长方向为正方向!而arg5,arg6...的存放地址实际上比callee的fp值要大
// 最后一个参数存放到 4($fp),倒数第二个参数存放到8($fp),以此类推
id2offset.put(i, off);
off -= 4;
}
}
String curInstr = Parser.getLine(true);
HashSet<String> alloca = new HashSet<>(); // 存放那些alloca的var
while (!curInstr.equals("}")) {
String[] elements = curInstr.split("; ");
curFuncDef.append(String.format("# %s\n", curInstr));
String instr = elements[0].replaceAll("\t", "");
// System.out.println(elements[1].replaceAll("[ \t]",""));
String instrType = elements[1].replaceAll("[ \t]", "");
String moreMsg = "INVALID_MOREMSG";
if (elements.length > 2) {
moreMsg = elements[2];
}
switch (instrType) {
/*
add, sub, mul, div, rem的mips指令其实是形式完全相同的
我把mul,div,rem分开写,是因为以后可能针对这三个特定的指令进行优化
*/
case "alloca": {
// %v3 = alloca i32
// alloca不生成中间代码,只是往num2offset里存信息
Pattern p01 = Pattern.compile("(%v\\d+) = alloca .*");
Matcher m01 = p01.matcher(instr);
int size = Integer.parseInt(moreMsg);
if (m01.find()) {
id2offset.put(VarAllocator.parseVarNum(m01.group(1)), offset2fp + 4 * (size - 1));
// curFuncDef.append(MipsCode.li("$t0", 0x7fffeffc - offset2fp));
// id2addr.put(VarAllocator.parseVarNum(m01.group(1)), 0x7fffeffc - offset2fp);
offset2fp += 4 * size;
alloca.add(m01.group(1));
}
break;
}
case "load": {
// %v5 = load i32, i32* %v3
// %v5 = load i32, i32* @g1
// 在mips里面,i32*和i32的处理貌似没啥不同。都是存到栈里的某个位置
Pattern p02 = Pattern.compile("(%v\\d+) = load .*, .*\\* (%v\\d+|@[a-zA-Z0-9_]+)");
Matcher m02 = p02.matcher(instr);
if (m02.find()) {
if (!alloca.contains(m02.group(2))) { // 不是alloca出来的,说明是getelementptr出来的
// 那么肯定是%v开头的
loadVar2Reg(m02.group(2), "$t1");
curFuncDef.append(MipsCode.lw("$t0", "$t1", 0));
} else {
if (m02.group(2).startsWith("%v")) {
// %v5 = load i32, i32* %v3
loadVar2Reg(m02.group(2), "$t0");
} else {
// %v5 = load i32, i32* @g1
int addr = glbCon2addr.get(m02.group(2));
curFuncDef.append(MipsCode.lw("$t0", addr));
}
}
storeReg2Var("$t0", m02.group(1));
}
break;
}
case "store": {
// store i32 %v5, i32* %v3
// store i32 %v5, i32* @g1
// store i32 5, i32* %v1
// store [5 x i32]* %v1, [5 x i32]** %v4
// store i32* %v0, i32** %v3
Pattern p03 = Pattern.compile("store .* ((?:%v)?-?\\d+), .*\\* (%v\\d+|@[a-zA-Z0-9_]+)");
Matcher m03 = p03.matcher(instr);
if (m03.find()) {
if (!alloca.contains(m03.group(2))) { // 不是alloca出来的,说明是getelementptr出来的
// 那么肯定是%v开头的
if (m03.group(1).startsWith("%v")) {
loadVar2Reg(m03.group(1), "$t0");
} else {
int value = Integer.parseInt(m03.group(1));
curFuncDef.append(MipsCode.li("$t0", value));
}
loadVar2Reg(m03.group(2), "$t1");
curFuncDef.append(MipsCode.sw("$t0", "$t1", 0));
} else {
if (m03.group(1).startsWith("%v")) {
loadVar2Reg(m03.group(1), "$t0");
} else {
int value = Integer.parseInt(m03.group(1));
curFuncDef.append(MipsCode.li("$t0", value));
}
if (m03.group(2).startsWith("%v")) {
// store i32 %v5, i32* %v3
int var2 = VarAllocator.parseVarNum(m03.group(2));
curFuncDef.append(MipsCode.sw("$t0", "$fp", -id2offset.get(var2)));
} else {
// store i32 %v5, i32* @g1
int addr = glbCon2addr.get(m03.group(2));
curFuncDef.append(MipsCode.sw("$t0", addr));
}
}
}
break;
}
case "call": {
// call void @putch(i32 102)
// call void @putint(i32 %v13)
// %v6 = call i32 @f1()
curFuncDef.append("# before call: \n");
for (int i = 0; i <= savedNum; i++) {
curFuncDef.append(MipsCode.sw("$t" + i, "$sp", -offset2fp));
offset2fp += 4;
}
Pattern p0 = Pattern.compile("call (void|i32) (@[a-zA-Z0-9_]+)\\((.*)\\)");
Matcher m0 = p0.matcher(instr);
String[] funcParams0 = {};
if (m0.find()) {
String type = m0.group(1);
String funcName0 = m0.group(2).substring(1);// 把前缀@去掉
if (!m0.group(3).isEmpty()) {
funcParams0 = m0.group(3).split(", ");
for (int i = 0; i < funcParams0.length; i++) {
String[] ss = funcParams0[i].split(" ");// 有时ss是[5 x i32]* %v1。此时,ss[ss.len-1]才是stmp
String stmp = funcParams0[i].split(" ")[ss.length - 1]; // 102 %v13
if (stmp.startsWith("%v")) {
// call void @putint(i32 %v13)
/* int var = VarAllocator.parseVarNum(stmp);*/
if (i < 4) {
loadVar2Reg(stmp, "$a" + i);
} else {
loadVar2Reg(stmp, "$t0");
curFuncDef.append(MipsCode.sw("$t0", "$sp", -offset2fp));
offset2fp += 4;
}
} else {
// call void @putch(i32 102)
int value = Integer.parseInt(stmp);
if (i < 4) {
curFuncDef.append(MipsCode.li("$a" + i, value));
} else {
curFuncDef.append(MipsCode.li("$t0", value));
curFuncDef.append(MipsCode.sw("$t0", "$sp", -offset2fp));
offset2fp += 4;
}
}
}
}// 前面每次新建变量(lw,sw)时,都没有让$sp加4,而是通过 offset($fp)来实现的,因为这样可以减少一定的指令数。
// 在这里即将调用函数,需要让sp的值正确,所以必须更新sp的值
curFuncDef.append(MipsCode.sub("$sp", "$sp", offset2fp));
// offset2fp = 0;
curFuncDef.append(MipsCode.jal(funcName0));
int numOfVarIntoStack = funcParams0.length > 4 ? funcParams0.length - 4 : 0;
curFuncDef.append(MipsCode.add("$sp", "$sp", 4 * (numOfVarIntoStack +savedNum + 1)));
for (int i = 0; i <= savedNum; i++) {
curFuncDef.append(MipsCode.lw("$t" + i, "$sp", -4 * i));
}
if (type.equals("i32")) {
storeReg2Var("$v0", instr.split(" = ")[0]);
}
}
break;
}
case "add":
case "sub": {
// %v5 = add i32 1, 1
// %v4 = add i32 %v3, 2345
// %v5 = add i32 1, %v1
// %v7 = add i32 %v5, %v6
Pattern p01 = Pattern.compile("(%v\\d+) = (add|sub) i32 (-?\\d+), (-?\\d+)");
Matcher m01 = p01.matcher(instr);
if (m01.find()) {
int i1 = Integer.parseInt(m01.group(3));
int i2 = Integer.parseInt(m01.group(4));
int value = i1 + (m01.group(2).equals("add") ? 1 : -1) * i2;
curFuncDef.append(MipsCode.li("$t0", value));
storeReg2Var("$t0", m01.group(1));
} else {
// 有1个或2个操作符为%var
Pattern p04 = Pattern.compile("(%v\\d+) = (add|sub) i32 ((?:%v)?-?\\d+), ((?:%v)?-?\\d+)");
Matcher m04 = p04.matcher(instr);
if (m04.find()) {
String op = m04.group(2);
String token1 = m04.group(3);
String token2 = m04.group(4);
if (token1.startsWith("%v")) {
loadVar2Reg(token1, "$t0");
} else {
int value = Integer.parseInt(token1);
curFuncDef.append(MipsCode.li("$t0", value));
}
if (token2.startsWith("%v")) {
loadVar2Reg(token2, "$t1");
} else {
int value = Integer.parseInt(token2);
curFuncDef.append(MipsCode.li("$t1", value));
}
curFuncDef.append(op.equals("add")
? MipsCode.add("$t2", "$t0", "$t1") : MipsCode.sub("$t2", "$t0", "$t1"));
storeReg2Var("$t2", m04.group(1));
}
}
break;
}
case "mul": // 与add类似,故不在此展示
case "sdiv": // 与add类似,故不在此展示
case "srem": // 与add类似,故不在此展示
case "ret": {
// ret i32 %v11
// ret i32 0
// ret void
Pattern p0 = Pattern.compile("ret (void|i32 ((?:%v)?-?\\d+))");
Matcher m0 = p0.matcher(instr);
if (m0.find()) {
if (m0.group(1).startsWith("i32")) {
if (m0.group(2).startsWith("%v")) {
loadVar2Reg(m0.group(2), "$v0");
} else {
curFuncDef.append(MipsCode.li("$v0", Integer.parseInt(m0.group(2))));
}
}
if (curFuncDef == mainFuncDef) {
mainFuncDef.append(MipsCode.li("$v0", 10));
mainFuncDef.append(MipsCode.syscall());
}else {
curFuncDef.append("# callee end!\n");
// callee的结尾
curFuncDef.append(MipsCode.lw("$ra", "$fp", 0));
curFuncDef.append(MipsCode.move("$sp", "$fp"));
for (int i = 0; i <= savedNum; i++) {
curFuncDef.append(MipsCode.lw("$s" + i, "$fp", -(4 * i + 12)));
}
curFuncDef.append(MipsCode.lw("$fp", "$fp", -4));
curFuncDef.append(MipsCode.jr("$ra"));
curFuncDef.append("\n");
}
}
break;
}
case "getelementptr": {
// %v16 = getelementptr i32, i32* %v10, i32 5
// var1 var2 offset
Pattern p01 = Pattern.compile("(%v\\d+) = getelementptr i32, i32\\* (%v\\d+), i32 ((?:%v)?-?\\d+)");
Matcher m01 = p01.matcher(instr);
if (m01.find()) {
String var1 = m01.group(1);
String var2 = m01.group(2);
String offset = m01.group(3);
loadVar2Reg(var2, "$t0");
if (m01.group(3).startsWith("%v")) {
loadVar2Reg(offset, "$t1");
curFuncDef.append(MipsCode.mul("$t1", "$t1", 4));
} else {
curFuncDef.append(MipsCode.li("$t1", Integer.parseInt(offset) * 4));
}
curFuncDef.append(MipsCode.add("$t2", "$t1", "$t0"));
storeReg2VarG("$t2", var1);
}
break;
}
case "getelementptr0": {
// %v9 = getelementptr [2 x [3 x i32]], [2 x [3 x i32]]* %v8, i32 0, i32 0
// %v10 = getelementptr [3 x i32], [3 x i32]* %v9, i32 0, i32 0
// var1 var2
Pattern p01 = Pattern.compile("(%v\\d+) = getelementptr .*, .*\\* (%v\\d+|@[a-zA-Z0-9_]+), i32 0, i32 0");
Matcher m01 = p01.matcher(instr);
if (m01.find()) {
String var1 = m01.group(1);
String var2 = m01.group(2);
if (alloca.contains(var2)) {
// 把var2的地址copy到$t1
loadVar2RegG(var2, "$t0");
} else {
// copy值
loadVar2Reg(var2, "$t0");
}
storeReg2Var("$t0", var1);
}
break;
}
case "label": {
curFuncDef.append(instr).append('\n');
break;
}
case "br": {
// br label %l2
Pattern p01 = Pattern.compile("br label %(l\\d+)");
Matcher m01 = p01.matcher(instr);
if (m01.find()) {
curFuncDef.append(MipsCode.b(m01.group(1)));
}
break;
}
case "brc": {
// br i1 %v5, label %l4, label %l3
Pattern p01 = Pattern.compile("br i1 (%v\\d+), label %(l\\d+), label %(l\\d+)");
Matcher m01 = p01.matcher(instr);
if (m01.find()) {
curFuncDef
.append(MipsCode.beqz(m01.group(1), m01.group(3)))
.append(MipsCode.b(m01.group(2)))
;
}
break;
}
case "zext": {
// %v4 = zext i1 %v3 to i32
// var1 var2
// 其实不需要生成什么mips代码,只需要把var1关联一下
Pattern p01 = Pattern.compile("(%v\\d+) = zext i1 (%v\\d+) to i32");
Matcher m01 = p01.matcher(instr);
if (m01.find()) {
int var1 = VarAllocator.parseVarNum(m01.group(1));
int var2 = VarAllocator.parseVarNum(m01.group(2));
id2offset.put(var1, id2offset.get(var2));
}
break;
}
case "icmp": {
// %v5 = icmp eq i32 %v4, 4
// icmp指令后面通常会接zext或brc指令
Pattern p01 = Pattern.compile("(%v\\d+) = icmp s?([a-z]+) i32 ((?:%v)?-?\\d+), ((?:%v)?-?\\d+)");
Matcher m01 = p01.matcher(instr);
if (m01.find()) {
String type = m01.group(2);
String nextInstr = Parser.getNextLine(1, true);
elements = nextInstr.split("; ");
// curFuncDef.append(String.format("# %s\n", curInstr));
instr = elements[0].replaceAll("\t", "");
// System.out.println(elements[1].replaceAll("[ \t]",""));
instrType = elements[1].replaceAll("[ \t]", "");
loadVar2Reg(m01.group(3), "$t0");
loadVar2Reg(m01.group(4), "$t1");
if (instrType.equals("brc")) {
// 后面接的是brc指令,那么可以稍微优化一点
// br i1 %v5, label %l4, label %l3
Pattern p02 = Pattern.compile("br i1 (%v\\d+), label %(l\\d+), label %(l\\d+)");
Matcher m02 = p02.matcher(instr);
if (m02.find()) {
String l4 = m02.group(2);
String l3 = m02.group(3);
curFuncDef.append(MipsCode.bCond(type, "$t0", "$t1", l4))
.append(MipsCode.b(l3));
}
Parser.readLine();
} else {
curFuncDef.append(MipsCode.sCond(type, "$t2", "$t0", "$t1"));
storeReg2Var("$t2", m01.group(1));
}
}
break;
}
default:
throw new MyException("无法识别的llvm_ir指令");
}
Parser.readLine();
curInstr = Parser.getLine(true);
}
}
public static void genMainFuncDef() throws Exception {
if (!Parser.readLine("; main")) {
throw new MyException("没读到; main");
}
Parser.readLine("define dso_local i32 @main() {");
mainFuncDef.append("main:\n");
mainFuncDef.append(MipsCode.move("$fp", "$sp")); // 将sp的值保存到fp中,这个fp的值即为最顶层的活动记录的栈帧
offset2fp = 0;
curFuncDef = mainFuncDef;
realFuncPart(new String[]{});
}
}
七、错误处理设计
设计思路
由于在五、中间代码生成设计中,已经建立起符号表了。所以此时的工作量已经少了很多。
此外,需要注意的是,并不是遇到第一个错误就直接结束错误处理,而是将源文件中的全部错误都输出。所以,需要在捕捉到一个错误的时候,“装作”其没有出错,并且继续进行分析。
在进行错误处理的时候:
- 如果捕获到了
ExceptionNeededReport,则不用回溯,继续处理就行。 - 如果捕捉到了
Exception,则说明按照文法解析失败,需要回溯。
每一种错误类型的处理思路如下:
- 非法符号:在FormatString中进行判断
- 名字重定义:查符号表
- 未定义的名字:查符号表
- 函数参数个数不匹配:查符号表,结合函数定义时的函数形参来进行判断
- 函数参数类型不匹配:查符号表,结合函数定义时的函数形参来进行判断
- 无返回值的函数存在不匹配的return语句:无脑处理即可
- 有返回值的函数缺少return语句:读到函数结束的
}前,判断是否有return - 不能改变常量的值:查符号表,check其是否为const
- 缺少分号、缺少右小括号、缺少右中括号:在读取不到时,抛出异常,并假设读到了,再继续进行后边的分析。
- printf中格式字符与表达式个数不匹配:读取FormatString时加以判断
- 在非循环块中使用break和continue语句:给Block一个isLoop属性,对于出现break和continue的块,判断其isLoop
编码结果
由于错误处理分布在各个Parsable的代码中,如果一一列出,会非常占篇幅,在此就不详细展示了。
在代码实现上,可以对每一个错误类型写一个类进行包装。例如:
package main.exceptions;
public class FuncMissingRetStmt_G extends ExceptionNeededReport{
public FuncMissingRetStmt_G(String s, int lineNum) {
super(s, 'g', lineNum);
}
}
其中ExceptionNeededReport为:
package main.exceptions;
import main.MyException;
import main.output.MyOutputManager;
public class ExceptionNeededReport extends MyException {
private char type;
private int lineNum = -1;
public ExceptionNeededReport(String s, char type, int lineNum) {
super(s);
this.type = type;
this.lineNum = lineNum;
}
public ExceptionNeededReport(String s, char type) {
this(s, type, -1);
}
public int getLineNum() {
return lineNum;
}
public char getType() {
return type;
}
}
其中,MyException为:
package main;
public class MyException extends Exception {
public MyException(String s) {
super("line " + Parser.getLineNum() + ": " + s);
}
}
八、代码优化设计
寄存器分配
在一开始完成代码生成的任务时,先试用朴素寄存器分配算法。这种思想最简单,也最低效:将所有的变量或临时变量都放在内存里。如此一来,每翻译一条中间代码之前我们都需要把要用到的变量先加载到寄存器中,得到该代码的计算结果之后又需要将结果写回内存。这种方法的确能将中间代码翻译成可以正常运行的目标代码,而且实现和调试都特别容易,不过它最大的问题是对寄存器的利用率实在太低。它不仅闲置了MIPS为我们提供的大部分通用寄存器,那些未被闲置的寄存器也没有对减少目标代码的访存次数做出任何贡献。
史晓华老师有言,“别的优化都不做,光做好寄存器分配,就已经能够竞速前百分之20%了”。所以这也是我在优化中最耗时、耗费精力的部分。
活跃变量分析
我们定义第i条中间代码的后继集合succ[i]为:
- 如果第i条中间代码为无条件跳转语句GOTO,并且跳转的目标是第j条中间代码,则succ[i]={j}。
- 如果第i条中间代码为条件跳转语句IF,并且跳转的目标是第j条中间代码,则succ[i]={j,i+1}。
- 如果第i条中间代码为返回语句RETURN,则succ[i]=NULL。
- 如果第i条中间代码为其他类型的语句,则succ[i]={i+1}。
我们再定义def[i]为被第i条中间代码赋值了的变量的集合,use[i]为被第i条中间代码使用到的变量的集合,in[i]为在第i条中间代码运行之前活跃的变量的集合,out[i]为在第i条中间代码运行之后活跃的变量的集合。活跃变量分析问题可以转化为解下述数据流方程的问题:

我们可以通过迭代的方法对这个数据流方程进行求解。算法开始时我们令所有的in[i]为空,之后每条中间代码对应的in和out集合按照上式进行运算,直到这两个集合的运算结果收敛为止。格理论告诉我们,in和out集合的运算顺序不影响数据流方程解的收敛性,但会影响解的收敛速度。对于上述数据流方程而言,按照i从大到小的顺序来计算in和out往往要比按照i从小到大的顺序进行计算要快得多。
图染色算法分配寄存器
全局的寄存器分配算法,这种全局分配算法必须要能有效地从中间代码的控制流中获取变量的活跃信息,而活跃变量分析(Liveliness Analysis)恰好可以为我们提供这些信息。如何进行活跃变量分析我们在后面介绍,现在假设我们已经进行过这种分析并了解到了在每个程序点上哪些变量在将来的控制流中可能还会被使用到。一个显而易见的寄存器分配原则就是,同时活跃的两个变量尽量不要分配相同的寄存器。这是因为同时活跃的变量可能在之后的运行过程中被用到,如果把它们分到一起那么很可能会产生寄存器内变量的换入换出操作,从而增加访存代价。
据此我们定义,两个不同变量x和y相互干扰的条件为:
- 存在一条中间代码i,满足x∈out[i]且y∈out[i]。
- 或者存在一条中间代码i,这条代码不是赋值操作x:=y或y:=x,且满足x∈def[i]且y属于out[i]。
如果将中间代码中出现的所有变量和临时变量都看作顶点,两个变量之间若相互干扰则在二者所对应的顶点之间连一条边,那么我们就可以得到一张干涉图(Interference Graph)。如果此时我们为每个变量都分配一个固定的寄存器,而将处理器中的k个寄存器看成k种颜色,我们又要求干涉图中相邻两顶点不能染同一种颜色,那么寄存器分配问题就变成了一个图染色(Graph-coloring)问题。对于固定的颜色数k,判断一张干涉图是否能被k着色是一个NP-Complete问题。因此,为了能够在多项式时间内得到寄存器分配结果,我们只能使用启发式算法来对干涉图进行着色。一个比较简单的启发式染色算法(称作Kempe算法)为:
- 如果干涉图中包含度小于或等于k-1的顶点,就将该顶点压入一个栈中并从干涉图中删除。
- 重复执行上述操作,如果最后干涉图中只剩下了少于k个顶点,那么此时就可以为剩下的每个顶点分配一个颜色,然后依次弹出栈中的顶点添加回干涉图中,并选择它的邻居都没有使用过的颜色对弹出的顶点进行染色。
- 如果出现了干涉图中所有的顶点都至少为k度,我们仍然选择一个顶点删除并且将其压栈,并且标记这样的顶点为待溢出的顶点,之后继续删点操作。
- 被标记为待溢出的顶点在最后被弹出栈时,如果我们足够幸运,有可能它的邻居总共被染了少于k种颜色。此时我们就可以成功地为该顶点染色并清除它的溢出标记。否则,我们无法为这个顶点分配一个颜色,它所代表的变量也就必须要被溢出到内存中了。
常量传播
对于const变量,在中间代码生成时将使用处尽可能优化为常量
窥孔优化
-
对于连续的跳转指令,可以将其优化
例如
... b l7 l8: b l5 l7: b l6 ...优化后:
... b l6 l8: b l5 l7: b l6 ... -
对于一些对同一位置进行lw,sw的,可以省去后面一条
例如
... lw $t0,0($fp) sw $t0,0($fp) ...可优化为:
... lw $t0,0($fp) ...
指令选择
这部分可做的很多,例如:
- 一些乘除指令转换为加减
- div的三操作数指令会多出判断除数是否为0的分支,可替换成div+mflo
- 用addi来替代subi,subu,addu直接对立即数进行使用。在立即数少于等于16位下,即在[-32768,32767]下效果显著。
补充说明
虽然在我的编译器中,加入了上面提到的几点优化,但遗憾的是,最终在ddl前,我的寄存器分配的版本还是有bug。所以,最终提交的版本基本上没做什么优化。还是有些遗憾的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号