第一单元(表达式解析)总结
写在前面
本单元的任务是解析表达式。共有三次任务,层层递进,每一次的任务都向前兼容上一次的任务。所以,我会简单略述我的前两次作业中的架构,并在第三次作业的部分详细展示我的构建思路。并在本文较靠后的位置集中分享了我的思考。
第一次作业
文件结构
UML类图

Class Metrics
| main.CannotParseException | 1.0 | 1.0 | 1.0 |
|---|---|---|---|
| main.Lexer | 1.25 | 3.0 | 10.0 |
| main.Main | 3.0 | 3.0 | 3.0 |
| main.TestType | 0.0 | ||
| main.Tools | 1.75 | 4.0 | 7.0 |
| mono.ConstantNumber | 1.5 | 2.0 | 3.0 |
| mono.Monomial | 1.0 | 1.0 | 6.0 |
| mono.PowerFunction | 2.0 | 3.0 | 4.0 |
| poly.Expression | 9.0 | 9.0 | 9.0 |
| poly.Factor | 3.0 | 3.0 | 3.0 |
| poly.Polynomial | 2.8181818181818183 | 16.0 | 31.0 |
| poly.Term | 4.0 | 4.0 | 4.0 |
| Total | 81.0 | ||
| Average | 2.1315789473684212 | 4.454545454545454 | 6.75 |
反思
优化
这次作业的优化思路比较清晰,我还发了一篇讨论区文章“如何让我们的输出变短”。
强测与互测
这次作业强测100分,互测没有被hack,还hack了同组的2位同学各一个bug。(并没有仔细研究他们的代码,而是直接生成大量随机样例未给程序进行大量评测来hack的。)
其他
使用了递归下降法,为迭代做了充分的准备。
在完成这次作业之余,我还和同学交流探讨并且实现了自动评测机。这为验证我自己以及其他roommate的程序正确性提供了很大帮助。
第二次作业
文件结构
与第三次作业基本相同,详见第三次作业的该部分
UML类图
与第三次作业基本相同,详见第三次作业的该部分
Class Metrics
| main.CannotParseException | 1.0 | 1.0 | 1.0 |
|---|---|---|---|
| main.CustomFunctionDefinition | 1.2 | 2.0 | 6.0 |
| main.CustomFunctionManager | 3.5 | 6.0 | 7.0 |
| main.DataCarrier | 1.0625 | 2.0 | 17.0 |
| main.Lexer | 1.2307692307692308 | 3.0 | 16.0 |
| main.Main | 4.0 | 4.0 | 4.0 |
| main.ParsingMode | 0.0 | ||
| main.SumFunctionParser | 9.0 | 9.0 | 9.0 |
| main.Tools | 1.5555555555555556 | 4.0 | 14.0 |
| mono.ConstantNumber | 1.2 | 2.0 | 6.0 |
| mono.Monomial | 1.1111111111111112 | 2.0 | 10.0 |
| mono.PowerFunction | 2.25 | 4.0 | 9.0 |
| poly.Expression | 10.0 | 10.0 | 10.0 |
| poly.Factor | 4.5 | 8.0 | 9.0 |
| poly.Polynomial | 1.3333333333333333 | 4.0 | 12.0 |
| poly.Term | 5.0 | 5.0 | 5.0 |
| trig.TrigExpression | 1.1666666666666667 | 2.0 | 7.0 |
| trig.TrigFactor | 2.3333333333333335 | 7.0 | 14.0 |
| trig.TrigFactorSimple | 1.3636363636363635 | 3.0 | 15.0 |
| trig.TrigTerm | 1.2222222222222223 | 3.0 | 11.0 |
| trig.TrigTermSimple | 1.3333333333333333 | 3.0 | 12.0 |
| trig.TrigType | 0.0 | ||
| Total | 194.0 | ||
| Average | 1.6166666666666667 | 4.2 | 8.818181818181818 |
反思
对于sum和自定义函数的处理,我的方式是将其在字符串级别进行替换(类似于C语言中的#define),个人思路比较清晰,细节注意得当,也没有出现什么问题。
优化
这次作业中的三角函数部分可以优化(题目对于其innerPart有比较多的限制,也减轻了我们的优化负担)。
我优化思路比较清晰,还发了一篇讨论区文章“如何让我们的输出变短”。只不过受限于时间,仍没能将“正项尽量放前面”这个小优化项写进代码。
强测与互测
这次作业强测93分(wa了1个点),互测被hack,还hack了同组的一些同学。(同样,并没有仔细研究他们的代码,而是直接生成大量随机样例未给程序进行大量评测来hack的。)
我自己的bug分析:
2个bug。(但是因为很细微,我可以在5行之内修复他们)
- 问题出在三角函数因子的
toString方法重写。在解析形如sin(x)**0的这种指数为0的三角函数因子时,我忽视了这种情况,导致其toString方法返回的字符串形式错误。 - 在使用
subString(0,2).equals("1*")进行优化的时候,不如使用startWith("1*")。因为,前者在String对象的长度小于2的时候会抛出异常,导致程序出错,而后者更为安全。
第三次作业
文件结构

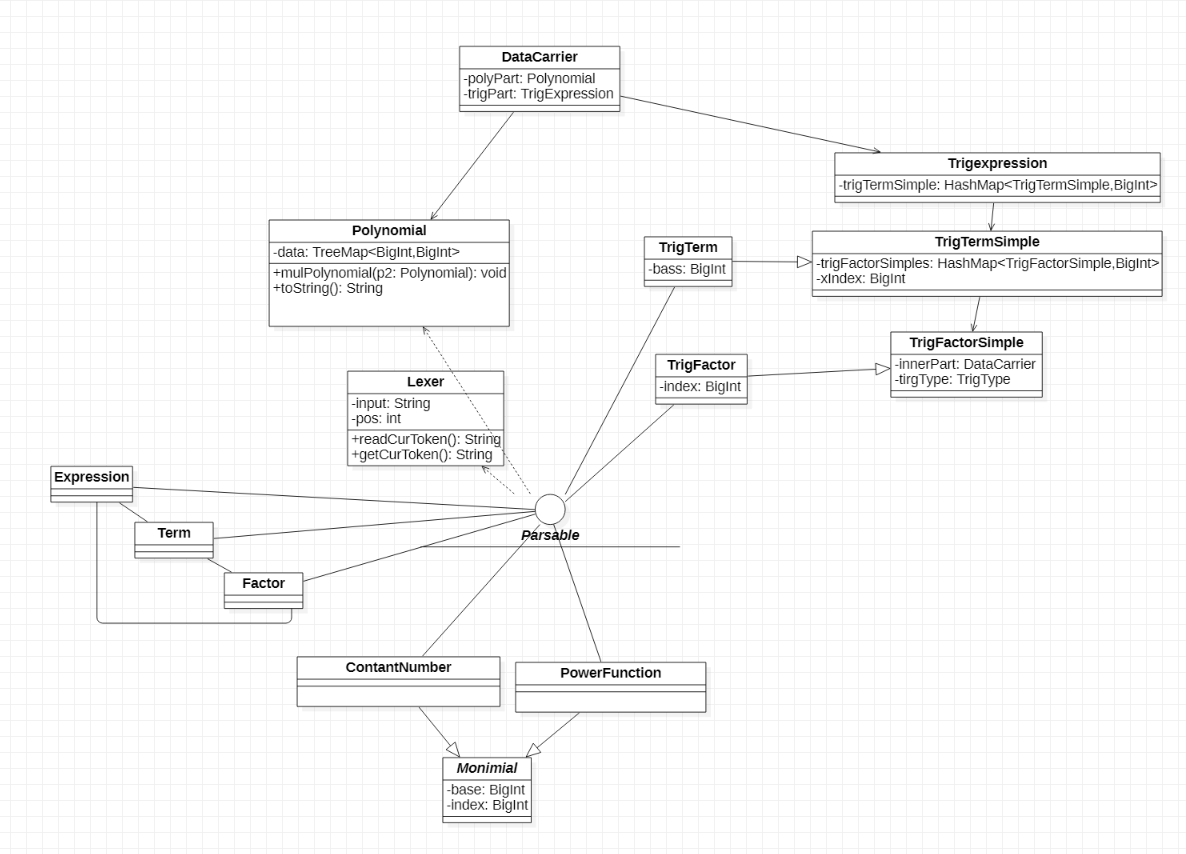
UML类图
Class Metrics
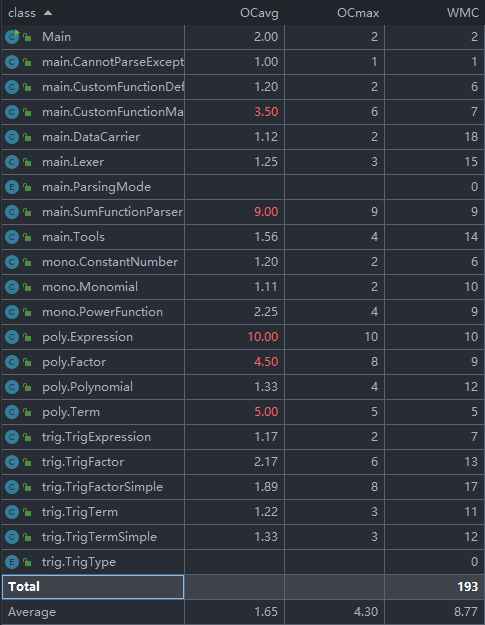
其中,大部分的类的复杂度度量都可以接受。
我重点看了Expression类和SumFunctionParser类,发现原来是因为我在进行解析的过程中,加入了大量对于异常的处理(理论上不加也可以),才导致OC很大。将这部分进行注释之后,SumFunctionParser的OC下降至3,Expression类的OC下降至7。
(Expression类的OC仍然很大是因为,在对其进行处理的时候,使用了switch语句。这个不可避免啦)
Method Metrics


可见,CogC较高的,是TrigFactorSimple的toString方法。很有趣的是,最终在互测和强测中被揪出来的那一处bug就是在这里产生的。(详见下面的bug分析部分)
另外,涉及到解析(与lexer类有关)的函数,ev(G)都普遍较高。程序非结构化程度较高。可以理解,毕竟这部分涉及到我的解析算法。
注,在我的设计中,对于实现了Parsable接口的类,其构造方法就是通过以Lexer对象作为传入的参数,通过解析来实现构造Parsable对象的
反思
优化
这次作业没有新加任何东西,但是将第二次作业的很多限制条件去除掉了。
我做的最主要的优化是充分利用sin()**2+cos()**2=1进行递归、嵌套优化。还自己写了计时器类进行了对于优化的限制。
但是受限于时间,我没能将最终的版本提交上去。最终提交的版本只进行了第二次作业的优化。
优化的部分代码和思路
在主函数中只需调用
Hashset<String> s = lexer.getTransformedExps(0,5,100000,new MyTimer()); // 5和100000是可以自行调整的参数
将s里的所有字符串进行解析,取解析后最短的表达式作为输出结果即可。
Lexer类中的getTransformedExps方法实现如下:
public class Lexer {
public HashSet<String> getTransformedExps(int start, int depth, int maxSize, MyTimer timer) {
/**
* 对于待变换表达式,从下标为start开始,对之后出现的sin/cos进行变换,返回一个HashSet,里面装了各种变换得到的形式
* 处理深度不超过depth的嵌套三角因子
* (maxSize,timer是防止得到的变换形式过多、运行时间过长导致无法在有效时间内返回结果设置的,可以先不用管)
*/
HashSet<String> ret = new HashSet<>(); // 这里面放的一定是Expression(外面包裹了括号的那种)
if (!timer.checkAvailable()) {
return ret;
}
String newExp3 = input;
do {
newExp3 = newExp3.replaceAll("\\({3}([^()])+\\){3}", "(($1))");
} while (newExp3.matches(".*\\({3}([^()])+\\){3}.*"));
ret.add(input);
setPos(start);
if (depth == 0 || isOver()) {
return ret;
}
String curToken;
do {
curToken = readCurToken();
} while (!curToken.matches("cos|sin") && !isOver());
if (isOver()) { // 说明没有sin/cos项
return ret;
}
// 此时curToken为"cos"或者"sin"
String trigName = curToken;
String otherTrigName = trigName.equals("sin") ? "cos" : "sin";
int innerStart = getPos();
int trigStart = innerStart - 3;
if (!readCurToken().equals("(")) {
throw new RuntimeException("字符串的sin/cos后面没有跟'('!");
}
int cnt = 1; // 表示 左括号个数-右括号个数的值。当cnt的值变为0时,这个三角因子就读取完毕了
while (true) {
curToken = readCurToken();
if (curToken.equals("(")) {
cnt++;
} else if (curToken.equals(")")) {
cnt--;
if (cnt == 0) {
break;
}
}
}
//此时已经刚刚读取了")"
int innerEnd = getPos();
BigInteger index;
if (getCurToken().equals("**")) {
readCurToken();
index = new ConstantNumber(this).getValue();
} else {
index = BigInteger.ONE; // 没有指数部分,即相当于指数为1
}
int trigEnd = getPos();
String innerStr = getRawStr(innerStart, innerEnd); // innerStr已被括号包裹
// 把innerPart的部分进行变换,并且
Set<String> innerTransformedExps = new Lexer(innerStr, null).getTransformedExps(0, depth - 1, maxSize,timer);
// .stream().map(str -> new Expression(new Lexer(str, null)).toString()).collect(Collectors.toSet())
;
// sin(x)**6 ->
// (sin(x)**6*(1-cos(x)**2)**0)
// (sin(x)**4*(1-cos(x)**2)**1)
// (sin(x)**2*(1-cos(x)**2)**2)
// (sin(x)**0*(1-cos(x)**2)**3)
for (BigInteger curIndex = index; curIndex.compareTo(BigInteger.ZERO) >= 0;
curIndex = curIndex.subtract(BigInteger.valueOf(2))) {
BigInteger curIndexTmp = curIndex; // lambda表达式中使用的变量应为final或有效final,所以需要新建这个临时的变量
BigInteger curIndexOther = index.subtract(curIndexTmp).divide(BigInteger.valueOf(2));
innerTransformedExps.forEach(its -> { // its: innerTransformedStr
String replacePart;
String itsb = "(" + its + ")"; // itsb: innerTransformedStrWithBrackets
replacePart = String.format("(%s%s**%s*(1-%s%s**2)**%s)",
trigName, itsb, curIndexTmp.toString(),
otherTrigName, itsb, curIndexOther.toString());
String newExp = this.input.substring(0, trigStart) + replacePart +
this.input.substring(trigEnd);
String newExp2 = newExp;
do {
newExp2 = newExp2.replaceAll("\\({3}([^()])+\\){3}", "(($1))");
} while (newExp2.matches(".*\\({3}([^()])+\\){3}.*"));
ret.add(newExp2);
// ret.add("(" + new Expression(new Lexer(newExp, null)).toString() + ")");
});
if (ret.size() >= maxSize) {
break;
}
}
HashSet<String> retA = new HashSet<>(); // retAppend,表示还需要给ret追加的内容
ret.forEach(exp -> {
int realTrigEnd = trigEnd + exp.length() - input.length();
new Lexer(exp, null).getTransformedExps(realTrigEnd, depth, maxSize - ret.size(),timer).forEach(nExp -> {
// retA.add("(" + new Expression(new Lexer(nExp, null)).toString() + ")");
retA.add(nExp);
});
});
ret.addAll(retA);
return ret;
}
}

强测与互测
这次作业强测83分(wa了2个点),互测被hack,还hack了同组的一些同学。(同样,并没有仔细研究他们的代码,而是直接生成大量随机样例未给程序进行大量评测来hack的。)
我自己的bug分析:
1个bug。
问题出在TrigFactorSimple的toString方法中。有些情况,innerPart在toString之后还需要再额外包裹一层括号,以适应因子的形式化表述。但是,我在某些必须加括号的情况下(形如sin((x+3))),忘记添加了括号。导致最终的输出不符合形式化表述。
值得注意的是,该方法是我写的程序中CogC最大的一个(达到了17),而该方法的模块设计复杂度(由iv(G)来衡量)和模块判定结构复杂程度(由v(G)来衡量)也居高不下。
诚然,在这个部分,确实不得不涉及到较为复杂的逻辑和与其他类相对较高的耦合。当时在写代码时并未在意,虽然自以为思路比较清晰,但还是留下了难以发现的bug。看来,在以后遇到类似情况时,要优先寻找更为简洁、更为低耦合的写法和算法。如果实在不行,那么在较为复杂的逻辑和关联、依赖关系中也一定要多加注意,写码时要慎重思忖。
收获与反思
通过这个单元的学习,我能感受到,我们在未来的道路上要面对的,已经从我们以往的“单个文件的小程序”中的“算法”问题,上升为“包含多个文件的大项目”的“架构”问题。
我在第二次作业布置下来的第一天,在构思时,首先用铅笔绘制了简易的UML图,理清了写代码的思路。那几张草图跟随了我2周,期间也偶有修修改改,现在还保存在我的夹子中。我甚至觉得,OO的课程,甚至可以在每个单元的首次作业中,先布置绘制UML图、写博客的作业。我觉得,就应该想清楚了再动手,磨刀不误砍柴工。
另外,在第二周、第三周的周五、周六,我将大部分的时间花在了优化性能上。结果最终连正确性也没能保证好,成绩并不理想。我想,在以后的作业中,我要重新定位好自己。正如我们的评分中正确性分值和性能分值是八二开一样,我想,我也应重新审视正确性的重要性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号