ForkAndJoin框架概念
ForkJoinPool是ExecutorService接口的实现,它专为可以递归分解成小块的工作而设计。
fork/join框架将任务分配给线程池中的工作线程,充分利用多处理器的优势。
使用fork/join框架的第一步是编写一部分工作的代码。类似的伪代码如下:
如果(当前工作部分足够小)
直接做这项工作
其他
把当前工作分成两部分
调用这两个部分并等待结果
将此代码包装在ForkJoinTask子类中,通常是RecursiveTask(可以返回执行结果)或者RecursiveAction。
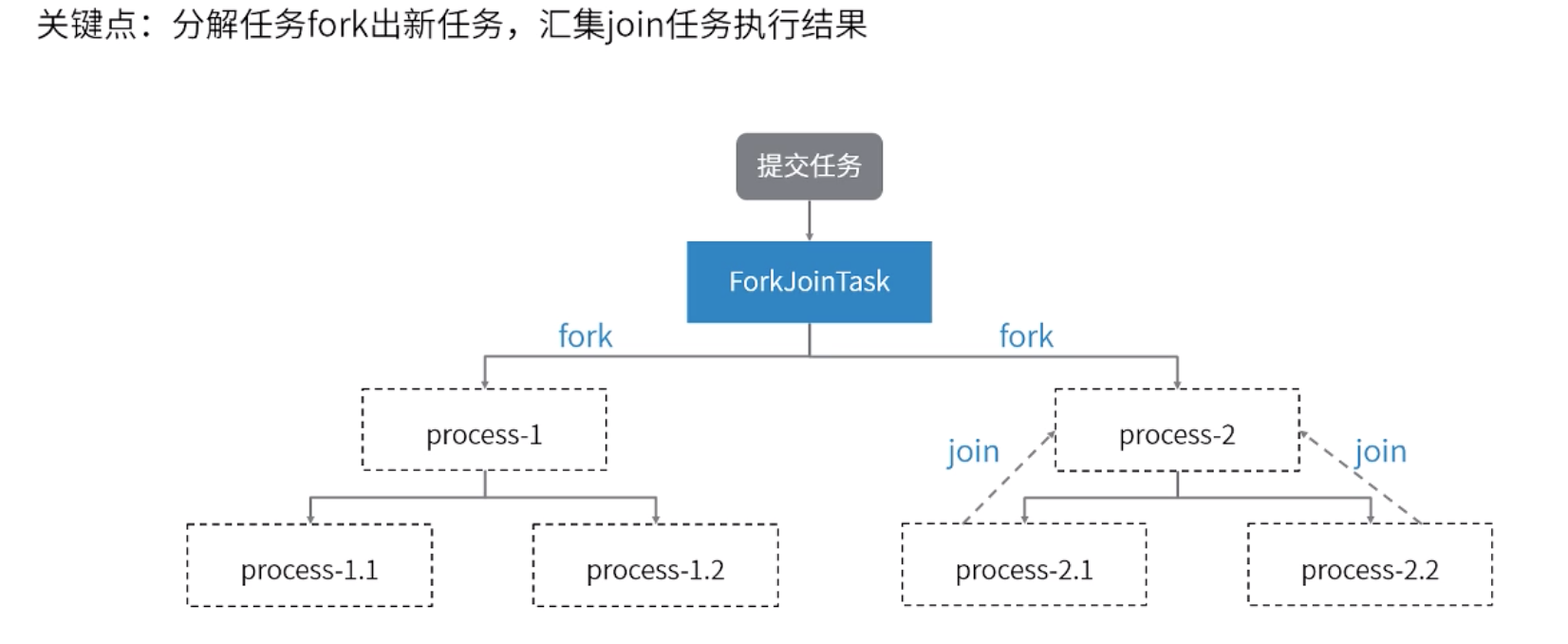
假如有一个从1累加到100的需求,使用forkAndJoin框架可以如下实现:
import java.util.ArrayList; import java.util.List; import java.util.concurrent.ExecutionException; import java.util.concurrent.Executors; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.RecursiveTask; public class ForkAndJoin { //获得执行ForkAndJoin任务的线程池 private static final ForkJoinPool forkJoinPool = (ForkJoinPool) Executors.newWorkStealingPool(); public static void main(String args[]) throws ExecutionException, InterruptedException { List<Integer> list = new ArrayList<>(); for (int i = 1; i < 101; i++) { list.add(i); } ForkAndJoinRequest request = new ForkAndJoinRequest(0, list.size() - 1, list); forkJoinPool.submit(request); System.out.println(request.get()); } } //定义request继承RecursiveTask,并实现compute方法 class ForkAndJoinRequest extends RecursiveTask<Integer> { private int start; private int end; private List<Integer> list; public ForkAndJoinRequest(int start, int end, List<Integer> list) { this.start = start; this.end = end; this.list = list; } @Override protected Integer compute() { int count = end - start; if (count <= 25) { //如果需要累加的数量小于等于25,则直接执行 int result = 0; for (int i = start; i <= end; i++) { result += i; } return result; } else { //否则fork出其他request int mid = (start + end) / 2; ForkAndJoinRequest request1 = new ForkAndJoinRequest(start, mid, list); request1.fork(); //调用fork方法将自身放入等待队列中等待执行 ForkAndJoinRequest request2 = new ForkAndJoinRequest(mid + 1, end, list); request2.fork(); //等待执行结果 return request1.join() + request2.join(); } } }
ForkJoin实现思路:
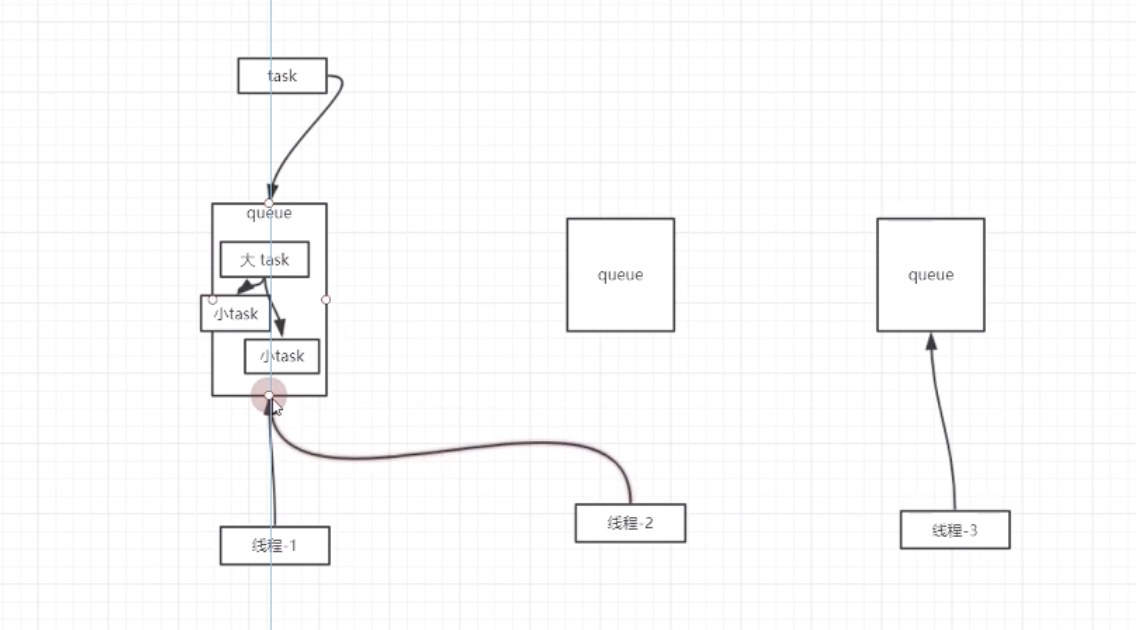
每个Worker线程都维护一个任务队列,即ForkJoinWorkerThread中的任务队列
任务队列是双向队列,这样可以同时实现LIFO和FIFO
子任务会被加入到原先任务所在Worker线程的任务队列
Work线程使用LIFO的方法取出任务,后进队列的任务先取出来(子任务需要先执行)
当任务队列为空,会随机从其他Worker的队列中拿走一个任务执行(工作窃取)
如果一个Worker线程遇到了join操作,而这时正在处理其他任务,会等到这个任务执行结束,否则立刻返回
如果一个Worker线程窃取任务失败,它会调用yield或者sleep方法休息一会再尝试。如果所有线程都是等待状态,那么此线程业务
阻塞直到新任务的到来
ForkJoinPool适用情况:
使用尽可能少的线程池--在大多数情况下,最好的决定是为每个应用程序或者系统使用一个线程池。
如果不需要特定调整,请使用默认的公共线程池。ForkJoinPool默认会产生CPU个数的线程
使用合理的阈值将ForkJoinTask拆分为子任务
避免在ForkJoinTask中出现任何阻塞。所以文件操作,http接口调用等场景不建议使用
适合数据处理、结果汇总、统计等场景
java8实例:java.util.Arrays类用于其parallelSort()方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号