PCA算法
原文来自主成分分析(PCA)原理总结 - 刘建平Pinard - 博客园,文章对PCA算法做了详细介绍,总结如下。
1.PCA的思想
PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。具体的,假如我们的数据集是n维的,共有m个数据(x(1),x(2),...,x(m))(x(1),x(2),...,x(m))。我们希望将这m个数据的维度从n维降到n'维,希望这m个n'维的数据集尽可能的代表原始数据集。我们知道数据从n维降到n'维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这n'维的数据尽可能表示原来的数据呢?
我们先看看最简单的情况,也就是n=2,n'=1,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向,u1和u2,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出,u1比u2好。
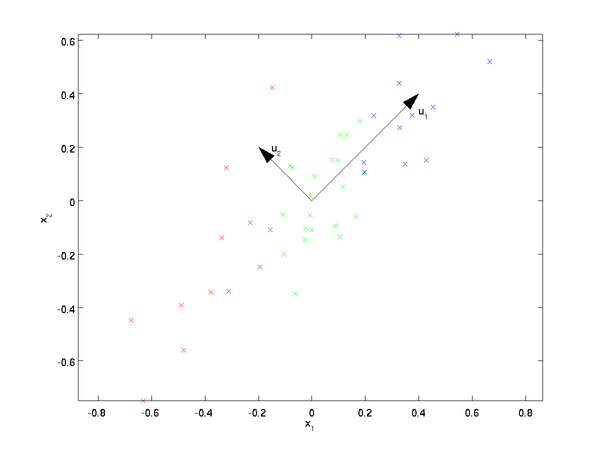
为什么u1比u2好呢?可以有两种解释,第一种解释是样本点到这个直线的距离足够近,第二种解释是样本点在这个直线上的投影能尽可能的分开。
假如我们把n'从1维推广到任意维,则我们的希望降维的标准为:样本点到这个超平面的距离足够近,或者说样本点在这个超平面上的投影能尽可能的分开。
基于上面的两种标准,我们可以得到PCA的两种等价推导
2.PCA的推导:基于最小投影距离
我们首先看第一种解释的推导,即样本点到这个超平面的距离足够近。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号