
心得体会-04-基于ASR与NMT技术的AI软件系统设计方案
我们在学习《高级软件工程》这门课程的关于软件系统设计部分的知识,希望在结合当前工程实践项目的课题《语音识别和翻译系统的实现》,对此系统进行完整的设计方案阐述。该工程实践是以深度学习为主要技术,以移植Hilens平台为最终目的的深度学习落地项目。现在我们只做了模型训练这一步,因为Hilens是华为官方提供的AI运行平台,只要把训练好的模型输出为pt文件就可以在华为云平台上转化成Hilens支持的格式,加载进去就可以测试与运行了,因此,主要的软件系统设计还是在模型设计上面,也是本文所要描述的重点。
一、 整体设计方案
我们的目标是将ASR(自动语音识别)技术和NMT(神经网络机器翻译)技术集成到Hilens设备上。其中我们通过ASR技术(语音转文本)可以将普通话发音转成中文汉字,如果中文汉字有误还需添加文本纠错技术;我们也可以通过NMT技术将中文文本翻译成英文文本;也可以通过ASR+NMT技术组合直接实现普通话发音转成英文文本输出。因此,总体上是两种技术,三种功能,具体如下所示:
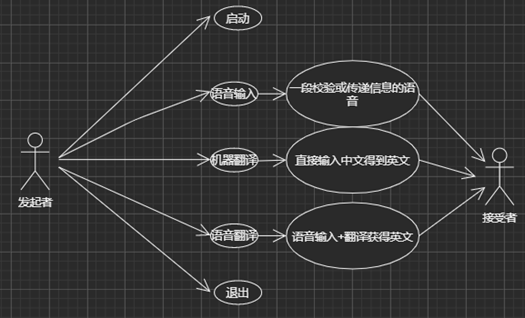
二、 软件架构风格与策略
软件架构既要考虑满足数量众多的各种系统功能需求, 也需要完成诸如系统的易用性、系统的可维护性等非功能性的设计目标, 还要遵从各种行业标准和政策法规。 不过并不是每一个项目我们都需要从头开始进行完全创新性的设计,更多的是通过研究借鉴优秀的设计方案,来逐步改进我们的设计。换句话说,大多数的设计工作都是通过复用(Reuse)相似项目的解决方案,或者采用一些优秀设计方案的方法,这让看起来非常有挑战性的软件架构设计工作变得有例可循。但是,软件架构又是至关重要的:
(1) 软件架构模型有助于项目成员从整体上理解整个系统
(2) 给复用提供了一个高层视图,既可以辅助决定从其他系统中复用设计或组件,也给我们构建的软件架构模型未来的复用提供了更多可能性
(3) 软件架构模型为整个项目的构建过程提供了一个蓝图,贯穿于整个项目的生命周期
(4) 软件架构模型有助于理清系统演化的内在逻辑、有助于跟踪分析软件架构上的依赖关系、有助于项目管理决策和项目风险管理等
而本工程实践既有语音识别的任务,也有机器翻译的任务,但两个任务是类似的,语音识别任务是将语音片段输入得到中文输出、机器翻译任务是将中文输入得到英文输出,往上抽象都可以理解为序列的输入、序列的输出任务,因此只讨论机器翻译的代码风格与策略,语音识别可类比与此。
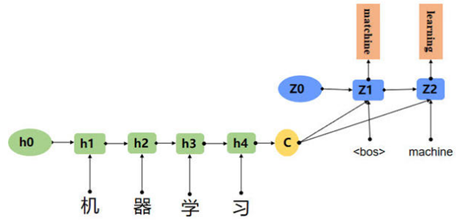
机器翻译任务主要考虑的是数据的收集、预处理、数据输入策略、模型的构建、数据的输出以及训练的策略,主要工作量在于模型构建。分别概述如下:
(1) 数据的收集——因为本训练任务实际上是一个有监督学习模型,因此需要的数据是一系列的平行语料对(这里是中英语料对),因此寻找的是公开的平行语料对(比如WMT语料)
(2) 数据的预处理——因为英文本质上有空格隔开单词,单词本身就代表比较完整的意思;而中文是由字组成的,而字的本身并不能比较完整表达意思,词才是比较合理的表达载体。因此需要对中文语料进行分词,开源的分词工具有很多,我们选择的是jieba分词工具,并采用精确模式+HMM的方式对中文语料进行分词。分词后需要分别统计平行语料的单词的词频,而中英语料单词不一样,因此不共享单词表。最后用到的是分词后的平行语料以及统计的单词表,共四个文件:
——train.zh
——train.en
——zh.vacob
——en.vacob
(3) 数据的输入策略——数据的输入包括分词后的中文文本、英文文本、中文单词、英文单词。首先中文文本输入编码器、编码器输出和英文文本都输入到解码器,中英文文本都是以句子为单位,超长的句子(例如超过100词的句子)会截断,并且以batch_size大小批量的方式输入。两个单词表会读入分别构建两个字典(单词索引对、索引单词对)共四个字典。
(4) 模型的构建——模型是以seq2seq为参考,加入attention机制并且将编码器与解码器的LSTM完全替换为MultiHead-Attention结构,即构建类似于Transformers架构的模型。因为算力有限以及模型轻量化的需求,所以我们采用三层的编码器+解码器结构。
(5) 模型的训练策略——采用反向传播更新参数,共训练500,000步,前8,000步先采用小学习率,并逐步增大学习率,然后根据Adam的方式逐步减小学习率,逐步收敛。
(6) 数据的输出——编码器的输出是512维的向量,这么低维的向量来表示这么多的信息,意味着信息密度很高。解码器最末端输出的向量大小是和英文单词表大小一致的,向量的值是一个类似概率分布的,根据其值选择最可能的若干个单词作为翻译输出。
三、 接口API
本工程实践既有语音识别的任务,也有机器翻译的任务,我们继续讨论机器翻译代码工程中的API,语音识别可类比于此。
本工程主要由两部分代码组成:训练部分的代码、翻译部分的代码,分别列表如下:
Train部分(train.py)
|
API名称 |
API输入 |
API输出 |
API功能 |
备注 |
|
parser |
终端参数的键 |
无 |
参数解释器 |
可设置默认值 |
|
load |
数据的路径 |
Torch支持的数据 |
载入数据 |
|
|
prepare_dataloaders |
载入的数据 |
训练集与验证集 |
载入数据和单词,产生训练集与验证集 |
|
|
Transformer |
模型参数 |
模型实例化对象 |
通过输入参数定义神经网络模型的结构,返回一个实例化的模型对象 |
|
|
ScheduledOptim |
优化器的参数 |
一个定义好调度策略的优化器 |
返回一个有确定调度策略的优化器 |
|
|
train_epoch |
模型、训练数据、优化器 |
训练误差、训练准确率 |
训练并计算当前epoch的误差和准确率 |
|
|
eval_epoch |
模型、验证数据、优化器 |
验证误差、验证准确率 |
验证并计算当前epoch的误差和准确率 |
|
Translate部分(translate.py)
|
API名称 |
API输入 |
API输出 |
API功能 |
备注 |
|
parser |
终端参数的键 |
无 |
参数解释器 |
可设置默认值 |
|
load |
单词表或模型的路径 |
Torch支持的数据 |
载入单词表或已训练好的模型 |
|
|
prepare_dataloaders |
载入的数据 |
训练集与验证集 |
载入数据和单词,产生训练集与验证集 |
|
|
Transformer |
模型参数 |
模型实例化对象 |
通过输入参数定义神经网络模型的结构,返回一个实例化的模型对象 |
|
|
load_state_dict |
加载模型的参数 |
无 |
加载模型参数,配合模型使用 |
|
|
translate_batch |
一个batch的待翻译数据 |
翻译的结果与翻译的成绩 |
完成一个batch里面的翻译任务 |
|
四、 软件视图
软件架构模型是通过一组关键视图来描述的,同一个软件架构,由于选取的视角(Perspective)和抽象层次不同可以得到不同的视图,这样一组关键视图搭配起来可以完整地描述一个逻辑自洽的软件架构模型。一般来说,我们常用的几种视图有分解视图、依赖视图、泛化视图、执行视图、实现视图、部署视图和工作任务分配视图。
本工程实践项目线下训练模型、线上转换模型、线下写入模型,分别从实现视图和部署视图角度来展示工程内容:
(一) 实现视图
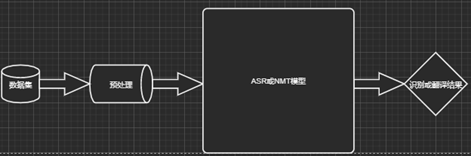
(二) 部署视图
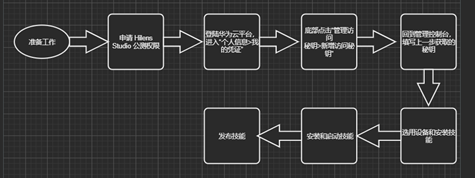
五、 核心数据结构设计
模型训练与部署过程中最主要的是word embedding以及矩阵运算,故核心的数据结构是有字典、列表。
六、 源代码目录文件结构
源代码中主要入口地址是train.py和translate.py,其中translate依赖于train得到的模型,而train依赖于dataset和precess的数据,transformer文件夹下的是模型的所有基础构件。
七、 软件系统运行环境和技术选型说明
软件运行分为训练与Hilens语音识别与机器翻译:
(1) 训练是在装有Python及其他依赖的的Ubuntu、Windows系统上,训练过程需要比较高端的英伟达显卡支持加速(显卡内存大于6GB),内存条内存大于8GB。
(2) 语音识别与机器翻译是在Hilens平台上运行,性能比较弱,底层库由华为提供或者自己添加。
八、 举例说明核心工作机制
本工程实践项目核心工作机制举例如下:
(1) 仅仅启用语音识别功能时,比如用户发出“你好”声音,通过声音收集器模数转换得到声音数字信号,输入到ASR模型,再经过文本纠错输出“你好”字符串,最后显示给用户;
(2) 仅仅启用机器翻译功能时,比如用户在文本框内输入“你好”字符串,输入到NMT模型,输出“Hello”字符串,最后显示给用户;
(3) 同时启用语音识别和机器翻译功能时,比如用户发出“你好”声音,通过声音收集器模数转换得到声音数字信号,输入到ASR模型,再经过文本纠错输出“你好”字符串,然后输入到NMT模型,输出“Hello”字符串,最后显示给用户。
九、总结
通过学习《高级软件工程》这门课程的软件系统设计部分的知识,对如何整体构建软件系统有了更进一步的认识,但小编才疏学浅,加上如何将深度学习与软件构建结合起来有比较大的难度,很多地方都做得不好,望各位提意见,小编会继续学习进步的,谢谢!

