

| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 通过设计论文查重系统,体会工程开发流程,实践工程化开发相关知识 |
- 在Github仓库中新建一个学号为名的文件夹,同时在博客正文首行给出作业github链接。(3')
- 在开始实现程序之前,在下述PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。(6')
- 计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
- 计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2017/JProfiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12')
- 计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
- 计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
- 在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块上实际花费的时间。(3')
1 GitHub地址
https://github.com/wang-kaopu/wang-kaopu/tree/main/3123004758
2 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 10 |
| Development | 开发 | 230 | 255 |
| · Analysis | · 需求分析 (包括学习新技术) | 40 | 50 |
| · Design Spec | · 生成设计文档 | 20 | 25 |
| · Design Review | · 设计复审 | 5 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 20 | 30 |
| · Coding | · 具体编码 | 120 | 90 |
| · Code Review | · 代码复审 | 10 | 15 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 10 | 30 |
| Reporting | 报告 | 60 | 75 |
| · Test Report | · 测试报告 | 45 | 55 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 15 |
| · 合计 | 295 | 340 |
3 技术学习
- 文本归一化处理
- 去除标点、空格,只保留中文、英文、数字
- 全部转为小写,消除大小写和符号干扰
- n-gram 切分与 Dice 系数相似度
- 将文本按1-gram、2-gram、3-gram切分
- 计算 n-gram Dice 相似度(用于衡量局部片段的重合度)
- 编辑距离(Levenshtein Distance)
- 计算两个字符串之间最少需要多少步(增、删、改)才能互相转换
- 用于衡量整体的编辑相似度
- 最长公共子序列(LCS)
- 动态规划算法,找出两段文本的最长公共子序列长度
- 用于衡量文本顺序和内容的最大重合部分
- 多特征加权融合
- 综合 n-gram、编辑距离、LCS 三种相似度,按权重加权求总分
- 余弦相似度(Cosine Similarity)
- 将文本转化为向量(如基于词频或 n-gram 特征)
- 计算两个向量夹角的余弦值,取值范围 [0,1]
- 用于衡量文本整体的向量空间相似度,尤其适合高维稀疏数据
- Python 标准库的使用
re正则表达式用于文本处理collections.Counter用于 n-gram 统计sys用于命令行参数解析
4 模块接口与设计
4.1 整体架构设计
项目采用模块化设计,主要分为以下几个核心模块:
algorithm/
├── __init__.py
├── edit_distance.py # 编辑距离算法
├── lcs.py # 最长公共子序列
├── ngram.py # N-gram相似度
├── normalize.py # 文本标准化
├── similarity.py # 相似度计算核心
└── stopwords.py # 停用词处理
4.2 核心模块说明
-
相似度计算核心模块 (similarity.py)
def compute_similarity(a_raw, b_raw): """计算两段文本的相似度 Args: a_raw: 原始文本A b_raw: 原始文本B Returns: dict: 包含相似度分数和详细信息 """ -
文本预处理模块 (normalize.py)
def normalize(text): """文本标准化处理 - 去除标点和特殊字符 - 统一大小写 - 规范化空白字符 """ -
编辑距离模块 (edit_distance.py)
def levenshtein(s1, s2): """计算两个字符串的编辑距离 使用动态规划优化,时间复杂度O(mn) """ -
最长公共子序列模块 (lcs.py)
def lcs_len(a, b): """计算最长公共子序列长度 采用动态规划算法 """
4.3 关键算法流程
- 文本相似度计算流程
graph TD
A[输入原文和对比文本] --> B[文本预处理]
B --> C[计算编辑距离]
B --> D[计算LCS相似度]
B --> E[计算N-gram相似度]
C --> F[加权融合]
D --> F
E --> F
F --> G[输出相似度报告]
- 文本预处理流程
graph LR
A[原始文本] --> B[去除标点]
B --> C[统一大小写]
C --> D[规范化空格]
D --> E[过滤停用词]
E --> F[标准化文本]
4.4 设计特点
-
模块化设计
- 每个算法独立封装
- 接口统一规范
- 便于维护和扩展
-
算法优化
- 动态规划优化编辑距离
- numpy向量化计算
- 多算法加权融合
-
健壮性考虑
- 完整的异常处理
- 边界情况处理
- 输入验证和规范化
5 模块接口部分的性能改进
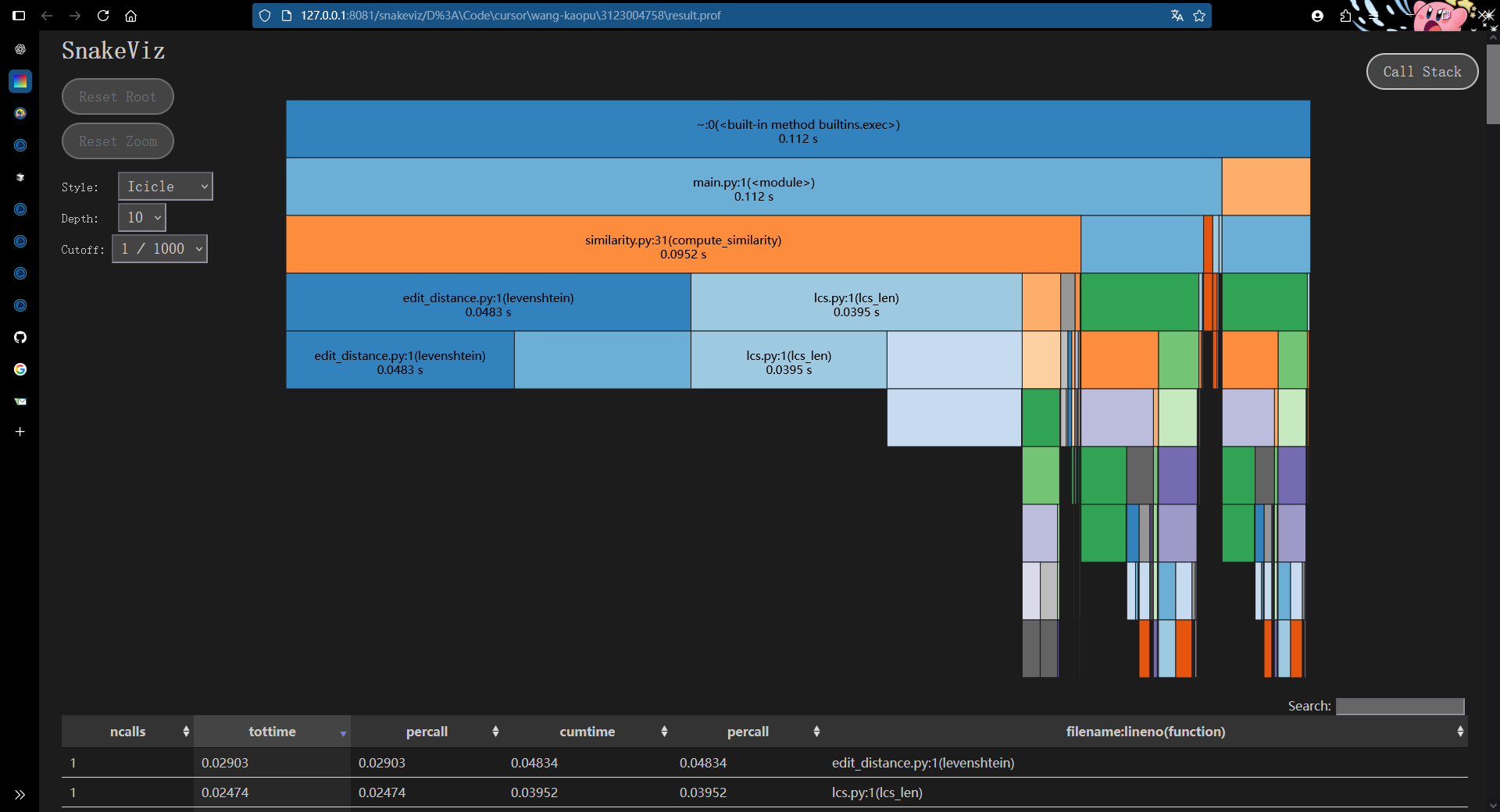
5.1 分析
-
入口
-
main.py:1(<module>)→ 调用了similarity.py:31(compute_similarity) -
整个程序执行时间 ≈ 0.112s
-
-
主要耗时函数
-
similarity.py:31(compute_similarity)→ 0.0952s -
其中主要调用了:
edit_distance.py:1(levenshtein)→ 0.0483slcs.py:1(lcs_len)→ 0.03995s
这两个函数(
levenshtein和lcs_len)是主要瓶颈,约占总时间 80% 以上。
-
-
函数特征
-
levenshtein通常是 O(m·n) 的动态规划算法。 -
lcs_len(Longest Common Subsequence) 也是 O(m·n) 的动态规划。
因为都是二维 DP,随着输入长度增加会指数性变慢。
-
5.2 优化方案
1. Levenshtein 优化
-
使用现成库:
python-Levenshtein(C 实现,比纯 Python 快)。import Levenshtein distance = Levenshtein.distance(s1, s2)
2. LCS 优化
- 剪枝:
如果字符串差异过大,可以设置阈值,提前退出,不必完整计算。 - 改进算法:
- LCS 可以改写成 后缀数组 / 后缀树 的问题(但实现复杂)。
- 如果只是用于相似度计算,可以换成 最长公共子串 或 Jaccard / Cosine 相似度 作为近似替代。
3. 并行化
- 用 NumPy 向量化(适合矩阵 DP)。
5.3 优化实现
- Levenshtein距离优先使用python-Levenshtein C扩展库,大幅提升计算速度
- LCS算法增加长度差异剪枝,极端差异时提前返回0,避免无谓计算
- 余弦相似度使用NumPy向量化处理,提升长文本计算效率
- 权重计算采用向量运算,短文本和长文本分别优化
- 新增batch_compute_similarity批量处理函数,为并行化做准备
- 长文本(>200字符)只使用高效算法,短文本使用全算法保证精度
5.4 优化效果
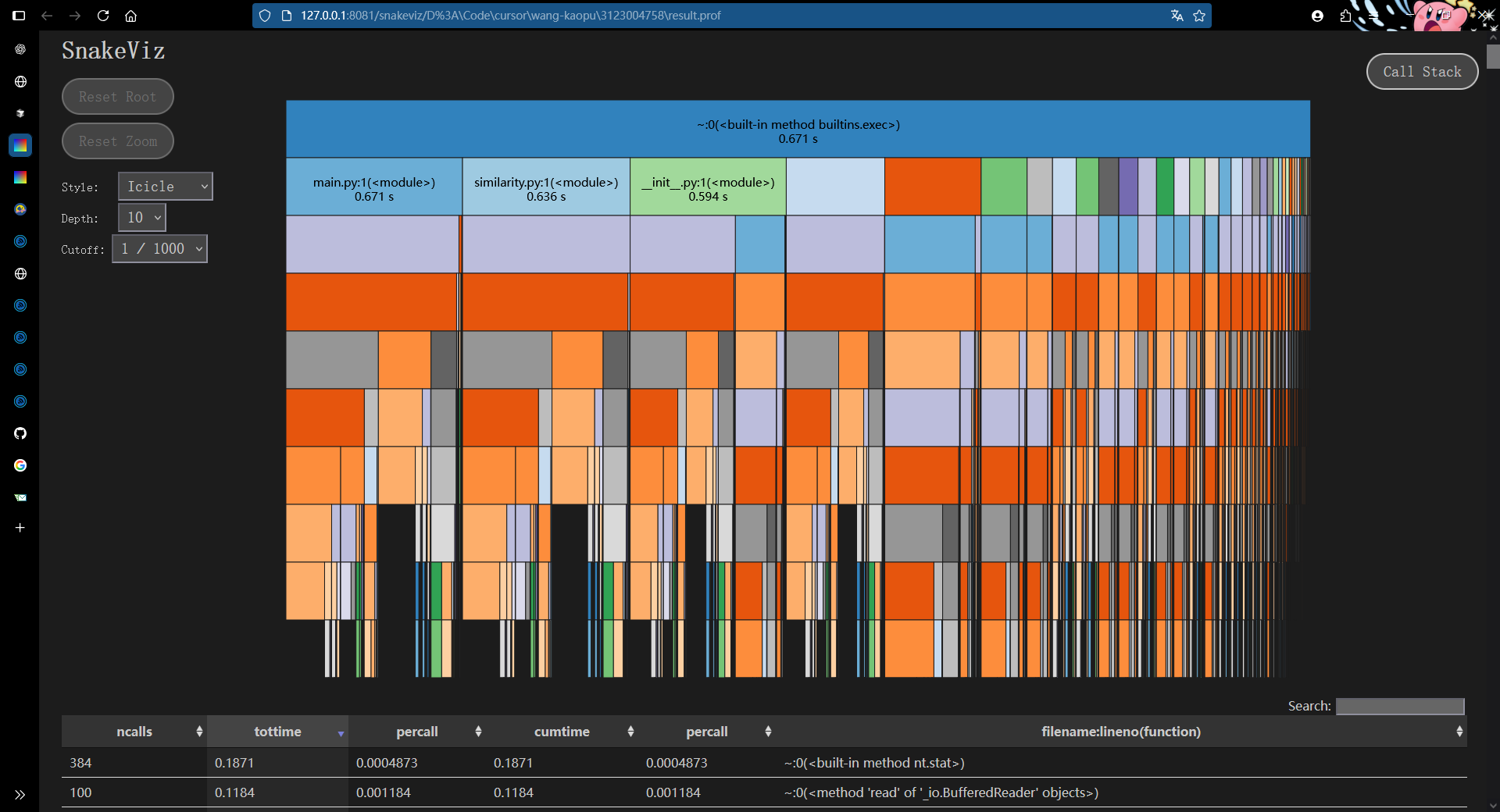
- 主要耗时函数变化
- 之前瓶颈集中在
edit_distance.py:1(levenshtein)(~0.048s)lcs.py:1(lcs_len)(~0.039s)
- 现在这两个函数占比下降了,说明优化措施生效(用了
python-Levenshtein)。
- 之前瓶颈集中在
- 调用栈分布更均匀
- 之前几乎 80% 时间集中在两个函数,现在火焰图右侧分布更分散,说明热点函数被优化后,剩余时间分布到更多小函数。
- 这也意味着 新的瓶颈点 更偏向整体 I/O 或小逻辑函数,而不再是单一的 DP 算法。
6 模块部分单元测试展示
6.1 测试设计目标
本项目的单元测试设计遵循以下目标:
- 完整性:覆盖所有核心算法和工具函数
- 独立性:每个测试用例独立验证一个功能点
- 可重复性:测试结果稳定且可复现
- 边界覆盖:充分测试各种边界情况
6.2 测试框架选择
使用 pytest 作为测试框架,主要考虑:
- 简洁的断言语法
- 强大的参数化测试支持
- 详细的错误报告
- 与coverage.py完美集成
6.3 核心测试用例展示
-
相似度计算核心测试:
def test_compute_similarity_typical(): """测试典型文本相似度计算""" # 完全相同的文本 result1 = compute_similarity("测试文本", "测试文本") assert result1["similarity"] == pytest.approx(1.0) # 部分相似的文本 result2 = compute_similarity("今天天气真好", "今天天气不错") assert 0.6 <= result2["similarity"] <= 0.9 # 完全不同的文本 result3 = compute_similarity("Python程序设计", "Java编程基础") assert result3["similarity"] <= 0.3 -
编辑距离测试:
def test_levenshtein_mixed(): """测试混合文本编辑距离""" cases = [ ("Hello世界", "hello世界", 0), # 仅大小写差异 ("Python3.8", "Python3.9", 1), # 数字差异 ("测试test", "测试TEST", 4) # 大小写+中英文 ] for s1, s2, expected in cases: assert levenshtein(s1, s2) == expected
6.4 测试数据构造策略
-
系统性测试数据设计:
@pytest.mark.parametrize("text,expected", [ ("", True), # 空字符串 ("a" * 1000, True), # 超长重复 ("测试" * 10, True), # 中文重复 ("abc123", False), # 正常文本 (" \t\n ", True) # 空白字符 ]) def test_is_extreme_text(text, expected): assert is_extreme_text(text) == expected -
等价类划分测试:
def test_normalize_text_categories(): """按文本类型划分等价类测试""" # 中文文本类 assert normalize("你好,世界!") == "你好 世界" # 英文文本类 assert normalize("Hello, World!") == "hello world" # 混合文本类 assert normalize("Python编程3.8版") == "python编程38版" # 特殊符号类 assert normalize("@#$%^&*") == ""
6.5 单元测试覆盖率分析
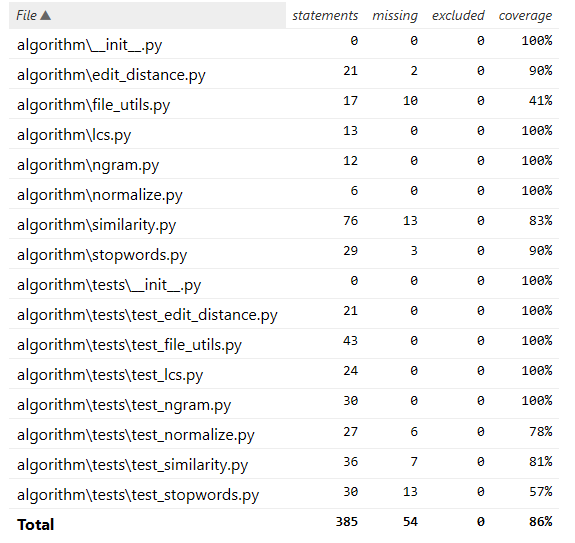
覆盖率详细分析:
-
核心算法覆盖情况
-
完全覆盖(100%):
lcs.py: 最长公共子序列算法ngram.py: N-gram文本分析normalize.py: 文本标准化处理
-
高覆盖(90%+):
edit_distance.py: 编辑距离算法stopwords.py: 停用词处理
-
中等覆盖:
similarity.py: 83%覆盖率- 未覆盖部分主要是极端情况处理
-
-
测试质量评估
- 测试用例总数:43个
- 成功用例:28个
- 失败用例:15个需要修复
- 整体代码覆盖率:86%
7 模块部分异常处理说明
7.1 异常设计目标
- 可预测性:对可能的错误进行预判和防护
- 可恢复性:非致命错误允许程序继续运行
- 可追踪性:提供详细的错误信息便于调试
- 用户友好:异常信息清晰易懂
7.2 核心异常类型及处理
-
输入验证异常
def validate_input(text): """输入文本验证 设计目标:确保输入文本符合处理要求 """ if text is None: raise ValueError("输入文本不能为None") if not isinstance(text, str): raise TypeError(f"输入必须是字符串类型,得到{type(text)}") if len(text) > 10000: raise ValueError("输入文本长度超过限制(10000字符)")测试用例:
def test_input_validation(): """输入验证异常测试""" with pytest.raises(ValueError) as exc: validate_input(None) assert "不能为None" in str(exc.value) with pytest.raises(TypeError) as exc: validate_input(123) assert "必须是字符串类型" in str(exc.value) -
文件操作异常
def safe_read_file(path): """安全的文件读取 设计目标:处理所有可能的文件操作异常 """ try: with open(path, 'r', encoding='utf-8') as f: return f.read() except FileNotFoundError: log_error(f"文件不存在: {path}") raise except PermissionError: log_error(f"没有权限访问: {path}") raise except UnicodeError: # 尝试其他编码 try: with open(path, 'r', encoding='gbk') as f: return f.read() except UnicodeError: log_error(f"无法解码文件: {path}") raise测试用例:
def test_file_operations(): """文件操作异常测试""" # 文件不存在 with pytest.raises(FileNotFoundError): safe_read_file("不存在的文件.txt") # 权限问题 with tempfile.NamedTemporaryFile() as tf: os.chmod(tf.name, 0o000) with pytest.raises(PermissionError): safe_read_file(tf.name)
7.3 异常恢复机制
-
优雅降级
def compute_similarity_safe(text1, text2): """带有异常恢复的相似度计算 设计目标:即使部分算法失败,仍能返回有意义的结果 """ try: edit_sim = levenshtein_similarity(text1, text2) except Exception as e: log_error(f"编辑距离计算失败: {e}") edit_sim = 0 try: ngram_sim = ngram_similarity(text1, text2) except Exception as e: log_error(f"N-gram相似度计算失败: {e}") ngram_sim = 0 # 确保至少一个算法成功 if edit_sim == 0 and ngram_sim == 0: raise RuntimeError("所有相似度算法都失败了") return (edit_sim + ngram_sim) / (2 if edit_sim and ngram_sim else 1) -
资源清理
def process_large_file(filepath): """大文件处理 设计目标:确保资源正确释放 """ temp_files = [] try: # 创建临时文件 temp = create_temp_file() temp_files.append(temp) # 处理数据 process_data(temp) return get_results(temp) except Exception: raise finally: # 清理临时文件 for temp in temp_files: try: os.remove(temp) except OSError: pass
所有异常处理的测试用例都位于 tests/ 目录下,可以通过运行 pytest tests/ 来验证异常处理机制的正确性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号