BERT总结:最先进的NLP预训练技术
BERT(Bidirectional Encoder Representations from Transformers)是谷歌AI研究人员最近发表的一篇论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding。它通过在各种各样的NLP任务中呈现最先进的结果,包括问答(SQuAD v1.1)、自然语言推理(MNLI)等,在机器学习社区中引起了轰动。
BERT的关键技术创新是将Transformers双向训练作为一种流行的注意力模型应用到语言建模中。这与之前研究文本序列(从左到右或从左到右和从右到左的组合训练)的结果相反。结果表明,双向训练的语言模型比单向训练的语言模型对上下文有更深的理解。在这篇论文中,研究人员详细介绍了一种名为Masked LM (MLM)的新技术,这种技术允许在以前不可能实现的模型中进行双向训练。
1. 背景
在计算机视觉领域,研究人员反复展示了在已知任务(如ImageNet)上对神经网络模型进行迁移学习预训练的价值,然后使用经过预训练的神经网络作为新的特定目的基模型进行参数微调。近年来,研究人员已经证明,类似的技术在许多自然语言任务中都是有用的。
另一种方法是基于特征的训练,这种方法在NLP任务中也很流行,最近的ELMo论文就是一个例子。在这种方法中,一个预先训练的神经网络产生了词嵌入,然后在NLP模型中用作特征。
2. BERT的工作方式
BERT使用了Transformer,它是一种学习文本中单词(或子单词)之间上下文关系的注意力机制。通常,Transformer包括两个独立的机制:一个是读取文本输入的编码器,另一个是生成任务预测的解码器。由于BERT的目标是生成语言模型,所以只需要编码器机制。谷歌的论文:Attention Is All You Need 详细描述了Transformer的工作原理。
BERT建立在最近的关于预训练表达研究工作的基础上,包括Semi-supervised Sequence Learning, Generative Pre-Training, ELMo和ULMFit。然而,与之前研究的模型不同的是,BERT是第一个深度双向的、无监督的语言表示,只使用纯文本语料库进行预训练。
预训练的词嵌入向量表达可以是上下文无关的,也可以是上下文相关的,而且上下文相关的表示还可以是单向的或双向的。举例说明:
- 上下文无关的模型(如word2vec或GloVe)为词汇表中的每个单词生成一个词嵌入向量。例如,“bank”一词在“bank account”和“bank of the river”中将具有相同的上下文无关表示。
- 上下文单向模型会根据句子中的其他单词,生成每个单词的表示。例如,在句子“I accessed the bank account”中,单向上下文模型将根据“I accessed the bank account”而不是“account”表示“bank”。
- 上下文双向模型(BERT)在表达单词“bank”时,使用它的前一个和下一个上下文—— “I accessed the ... account”,从一个很深的神经网络的最底部开始,使它被双向读取。
与以往最先进的上下文预训练方法相比,BERT神经网络体系结构的可视化如下所示。箭头表示信息从一层流向另一层。顶部的绿色框表示每个输入词的最终上下文表示:其中BERT是深度双向的,OpenAI GPT是单向的,ELMo是浅双向的。
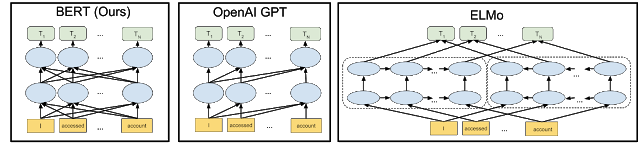
为什么以前没有对双向性做这样的研究?这是因为考虑到单向模型是有效训练,通过预测每个词在句子中的前一个词。然而,仅仅根据每个单词的前一个和下一个单词来训练双向模型是不可能的,因为这将允许被预测的单词在多层模型中间接地“看到自己”。
为了解决这个问题,我们使用了一种直接的技术,即屏蔽输入中的一些单词,然后对每个单词进行双向条件化,以预测屏蔽(MSAK)掉的单词。例如:

虽然这个想法已经存在很长时间了,但BERT是第一次成功地用它来训练深层神经网络。
此外,BERT对任何文本语料库都可以生成的一个非常简单的任务进行预训练来学习并模拟句子之间的关系:给定两个句子A和B, B是实际的在语料库A之后的下一个句子,此外还会产生一个随机的句子,例如:
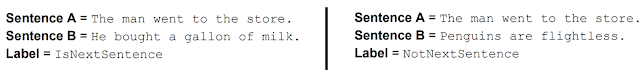
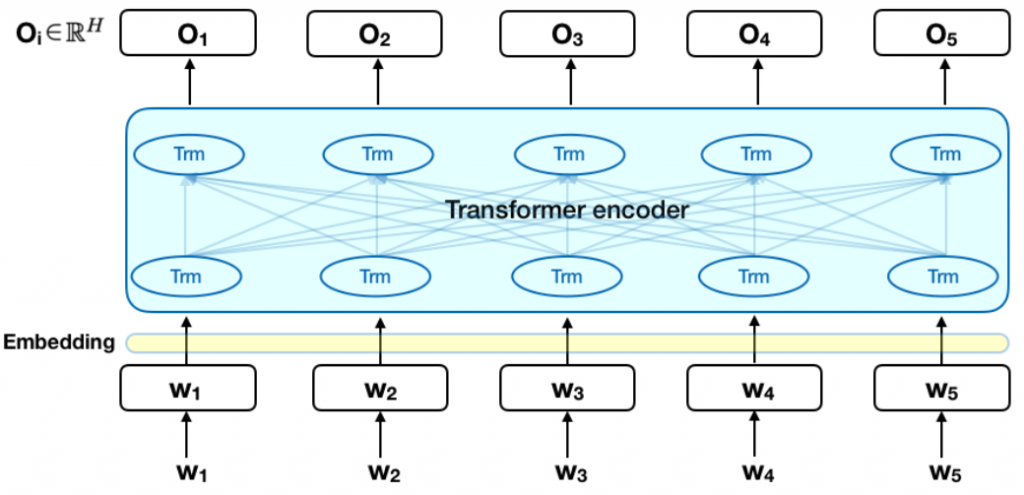
下面的图表是Transformer编码器的高级描述。输入是一个token序列,它首先嵌入到向量中,然后在神经网络中进行处理。输出是大小为H的向量序列,其中每个向量对应于具有相同索引的输入token。
在训练语言模型时,定义预测目标是一个挑战。许多模型预测一个序列中的下一个单词(例如,“The child came home from ___”),这是一种天生限制上下文学习的定向方法。为了克服这个挑战,BERT使用了两种训练策略:
3. Masked LM (MLM)
在向BERT输入单词序列之前,每个序列中有15%的单词被[MASK]token替换。然后,该模型试图根据序列中其他非MASK词提供的上下文来预测MASK词的原始值。在技术上,输出词的预测要求:
- 在编码器输出之上添加一个分类层。
- 将输出向量乘以嵌入矩阵,将它们转换为词汇表的维度。
- 使用softmax计算词汇表中每个单词的概率。
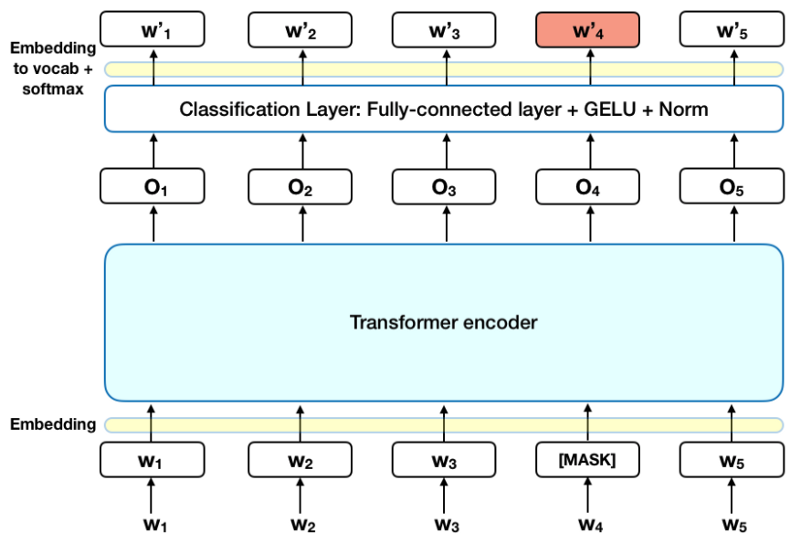
BERT损失函数只考虑了MASK值的预测,而忽略了非MASK词的预测。因此,模型的收敛速度比单向模型慢。
注意:在实践中,BERT实现稍微复杂一些,并没有替换掉15%的伪装词。
4. Next Sentence Prediction (NSP)
在BERT训练过程中,模型接收成对的句子作为输入,并学习预测这对句子中的第二句是否为原始文档中的后续句。在训练过程中,50%的输入是一对句子组合,其中第二句是原文档中的后一句,而在其余的50%中,从语料库中随机选择一个句子作为第二句。假设随机选择的句子与第一个句子相互独立。
为了帮助模型在训练中区分这两个句子,输入在进入模型前按照以下方式进行处理:
- 在第一个句子的开头插入[CLS]token,在每个句子的结尾插入[SEP]token。
- 在每个标记中添加一个表示句子A或句子B的嵌入句。句子嵌入在概念上类似于标记嵌入,词汇表为2。
- 每个标记都添加了位置嵌入,以指示其在序列中的位置。(位置嵌入的概念和实现方法参考论文:Attention Is All You Need )。

要预测第二个句子是否确实与第一个句子有关联,需要执行以下步骤:
- 整个输入序列通过Transformer模型。
- [CLS]token的输出使用一个简单的分类层(学习权重和偏差矩阵)转换为一个2 1形状的向量。
- 用softmax计算IsNextSequence的概率。
在训练BERT模型时,将MASK LM和下一个句子预测一起训练,目的是最小化这两种策略的组合损失函数。
5. 如何使用BERT (Fine-tuning)
使用BERT完成特定的任务相对简单::BERT可以用于各种各样的语言任务,但只在核心模型中添加了一个小层。
假设已经对数据进行了分类,可以使用BERT对预先训练好的模型进行微调,方法是对输入进行标记,将其输入到BERT模型中,并使用[CLS]token(第一个token)输出来预测分类。
- 通过在[CLS]token的Transformer输出之上添加一个分类层,像情绪分析这样的分类任务与下一个句子分类类似。
- 在问答系统的任务中,软件接收到一个关于文本序列的问题,需要在序列中标记答案。使用BERT,一个问答模型可以通过学习两个额外的向量来训练,这两个向量标记了答案的开始和结束。
- 在命名实体识别(NER)中,软件接收到一个文本序列,并需要标记文本中出现的各种类型的实体(人员、组织、日期等)。通过使用BERT,可以通过将每个token的输出向量放入一个预测NER标签的分类层来训练NER模型。
在微调训练中,大多数超参数与BERT训练保持一致,本文对需要调优的超参数给出了具体的指导(第3.5节)。BERT团队使用这种技术在各种具有挑战性的自然语言任务中取得了最先进的结果,本文第4部分对此进行了详细介绍。
6. BERT_large与BERT_base
模型大小很重要,即使是大规模的。拥有3.45亿个参数的BERT_large是同类模型中最大的一个。它在小规模任务上明显优于BERT_base,后者使用相同的体系结构,“仅”使用1.1亿个参数。
有足够的训练数据,更多的训练步骤==更高的准确率。例如,在MNLI任务中,在1M步(128000字批量大小)上训练的BERT_base准确率比在相同批量大小下训练的500K步提高了1.0%。
BERT的双向训练方法(MLM)收敛速度慢于从左到右的训练方法(因为每批预测的单词只有15%),但是经过少量的预处理步骤后,双向训练仍然优于从左到右的训练。

关于BERT_large和BERT_base的性能评估对比如下图所示:

7. 总结
BERT无疑是利用机器学习进行自然语言处理的突破性进展。事实上,它是可接近的,并允许快速微调,将可能允许广泛的实际应用在未来。本文尽量做到在不探究过多技术细节的情况下描述BERT的主要思想。对于那些希望更深入研究的人,我们强烈推荐阅读全文和文章中引用的辅助文章。另一个有用的参考资料是BERT源代码和模型。
在BERT中训练语言模型是通过预测输入中随机选择的15%的标记来完成的。这些标记被预处理如下:80%被[MASK]标记替换,10%被随机单词替换,10%使用原始单词。论文之所以选择上述比例,主要是考虑以下几点:
- 如果我们100%地使用[MASK],模型就不会为非MASK字产生好的标记表示。非MASKtoken仍然用于上下文,但是模型是为预测掩码词而优化的。
- 如果我们90%的时间使用[MASK], 10%的时间使用随机单词,这将教会模型观察到的单词永远不会正确。
- 如果我们90%的时间使用[MASK], 10%的时间使用相同的单词,那么模型就可以简单地复制非上下文嵌入。没有对这种方法的比率做消融,它可能在不同的比率下工作得更好。
此外,模型性能没有通过简单地屏蔽100%所选token进行测试。
8. 参考文献
[1] Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing

 浙公网安备 33010602011771号
浙公网安备 33010602011771号