
数据采集第四次作业
1.作业①:
码云地址:https://gitee.com/wjz51/wjz/tree/master/project_4/4_1
1.1 要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法; Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
1.2 解题思路:
1.2.1 spider部分
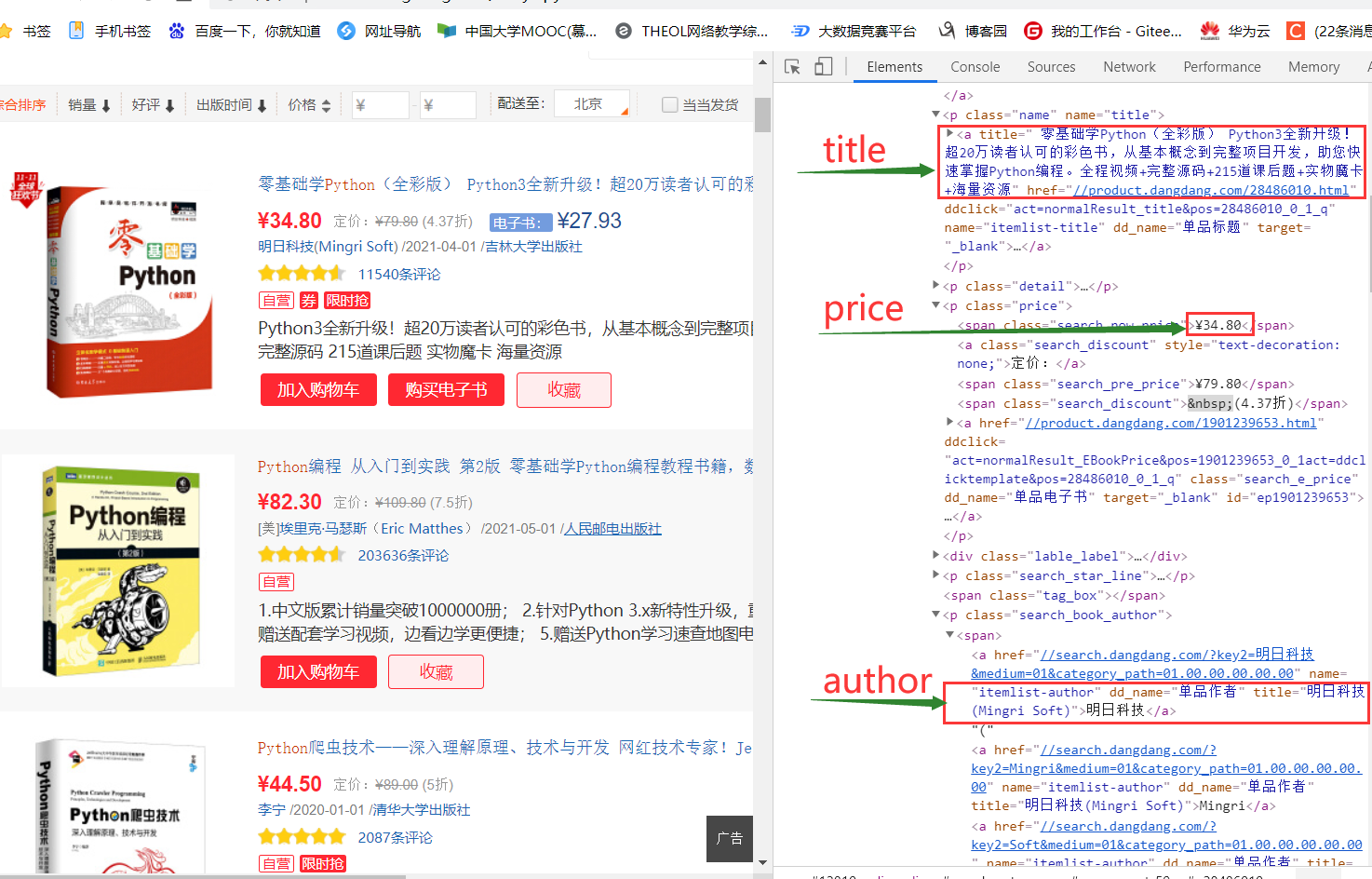
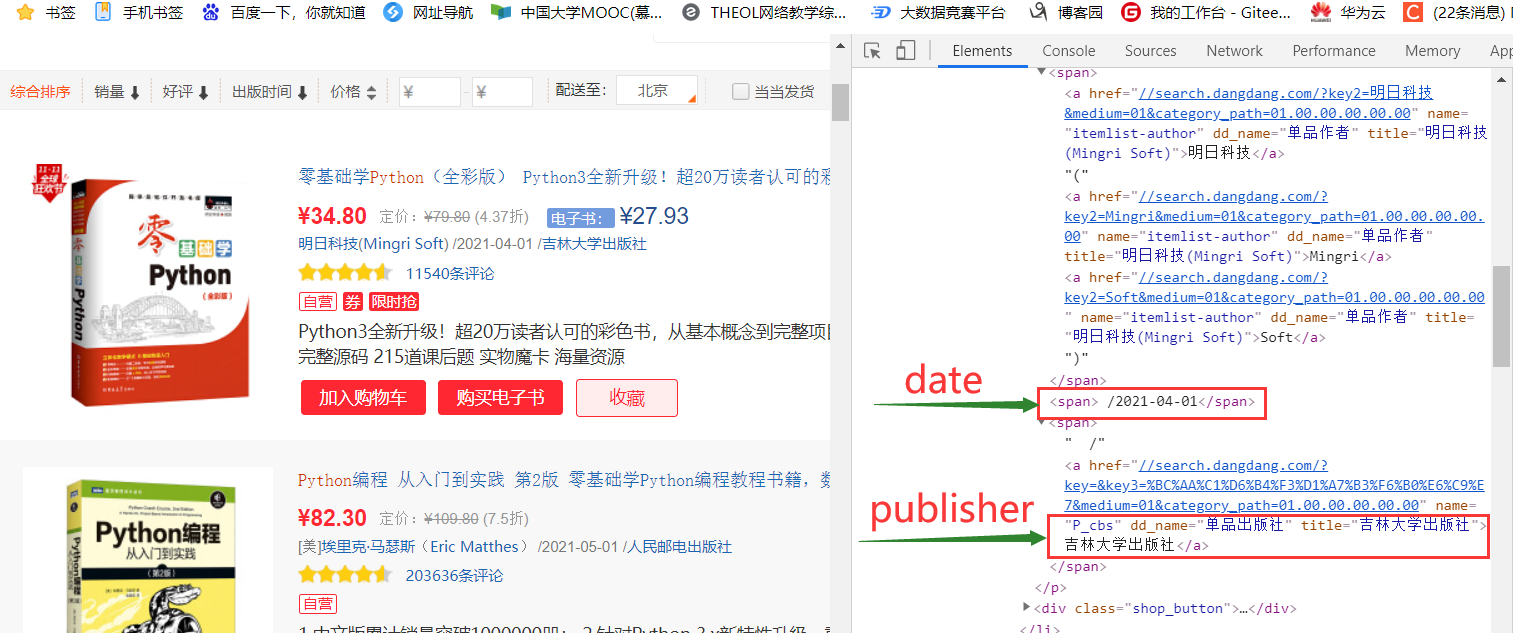
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date =li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()detail有时没有,为None,解决如下:
item = DangdangItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""1.2.2 items部分
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
1.2.3 settings部分
添加以下内容:
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}1.2.4 pipelines部分
class DangdangPipeline:
def open_spider(self, spider):#打开数据库
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd = "Wjz20010501", db = "mydb", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):#关闭数据库
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "本书籍")
def process_item(self, item, spider):#向数据库中插入数据
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values(%s,%s,%s,%s,%s,%s)",
(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count += 1
except Exception as err:
print(err)
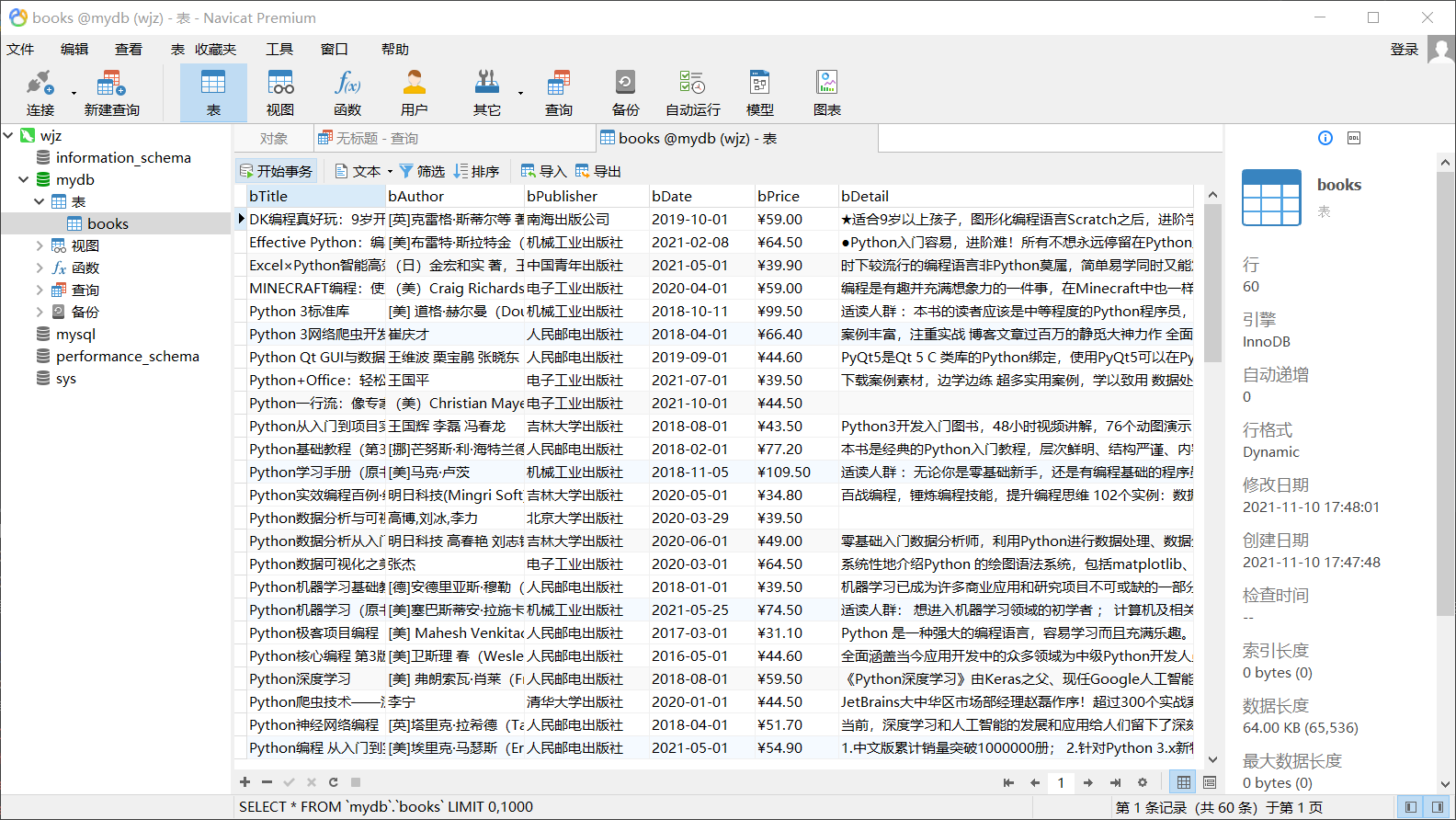
return item1.3 运行结果:
MySQL数据库结果:
1.4 心得体会:
该作业我再次熟悉了scrapy操作,以及学会并使用MySQL数据库存储。
2.作业②:
码云地址:https://gitee.com/wjz51/wjz/tree/master/project_4/4_2
2.1 要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
2.2 解题思路:
2.2.1 spider部分
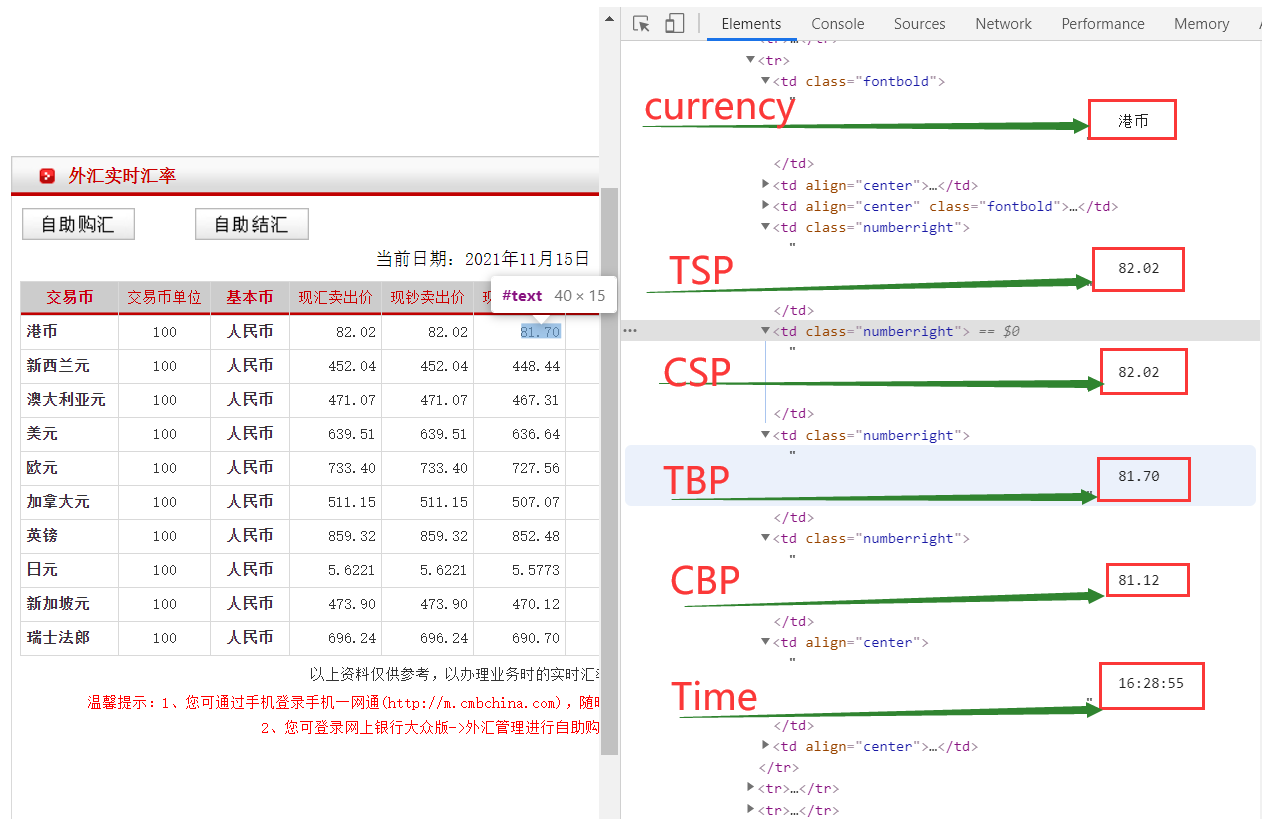
trs = response.xpath("//table[@width='740']//tr")
for i in range(1, len(trs)):
item = ZsbankItem()
#currency
curr = trs[i].xpath("./td[1]/text()").get()
curr = curr.split()
item["cur"] = curr[0]
#tsp
tspp = trs[i].xpath("./td[4]/text()").get()
tspp = tspp.split()
item["tsp"] = tspp[0]
#csp
cspp = trs[i].xpath("./td[5]/text()").get()
cspp = cspp.split()
item["csp"] = cspp[0]
#tbp
tbpp = trs[i].xpath("./td[6]/text()").get()
tbpp = tbpp.split()
item["tbp"] = tbpp[0]
#cbp
cbpp = trs[i].xpath("./td[7]/text()").get()
cbpp = cbpp.split()
item["cbp"] = cbpp[0]
#time
timee = trs[i].xpath("./td[8]/text()").get()
timee = timee.split()
item["time"] = timee[0]2.2.2 items部分
class ZsbankItem(scrapy.Item):
# define the fields for your item here like:
cur = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
time = scrapy.Field()2.2.3 settings部分
添加以下内容:
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}2.2.4 pipelines部分
class ZsbankPipeline:
cnt=0
def open_spider(self, spider):#打开数据库
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd = "Wjz20010501", db = "mydb", charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from bank")
self.opened = True
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):#关闭数据库
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):#向数据库中插入数据
try:
if self.opened:
ZsbankPipeline.cnt +=1
id = str(ZsbankPipeline.cnt)
self.cursor.execute("insert into bank (Id,Currency,TSP,CSP,TBP,CBP,Time) values(%s,%s,%s,%s,%s,%s,%s)",
(id,item["cur"], item["tsp"], item["csp"], item["tbp"], item["cbp"],item["time"]))
except Exception as err:
print(err)
return item2.3 运行结果:
MySQL数据库结果:
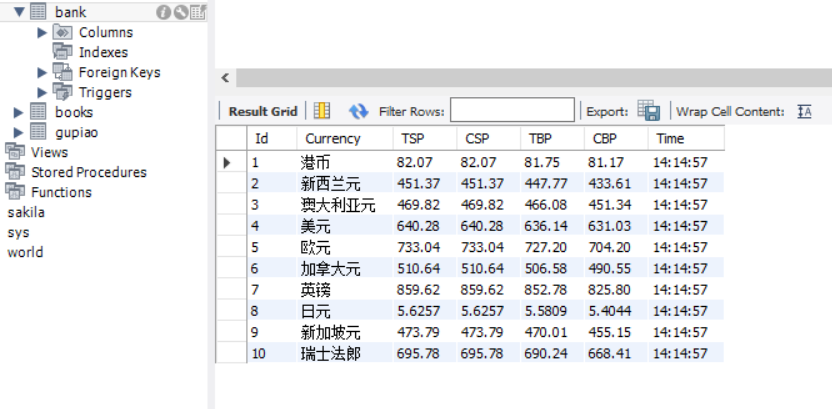
2.4 心得体会:
该作业我可以熟练应用scrapy以及更加娴熟的使用MySQL数据库
3. 作业③:
码云地址:https://gitee.com/wjz51/wjz/blob/master/project_4/4_3.py
3.1 要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
3.2 解题思路:
3.2.1 xpath部分
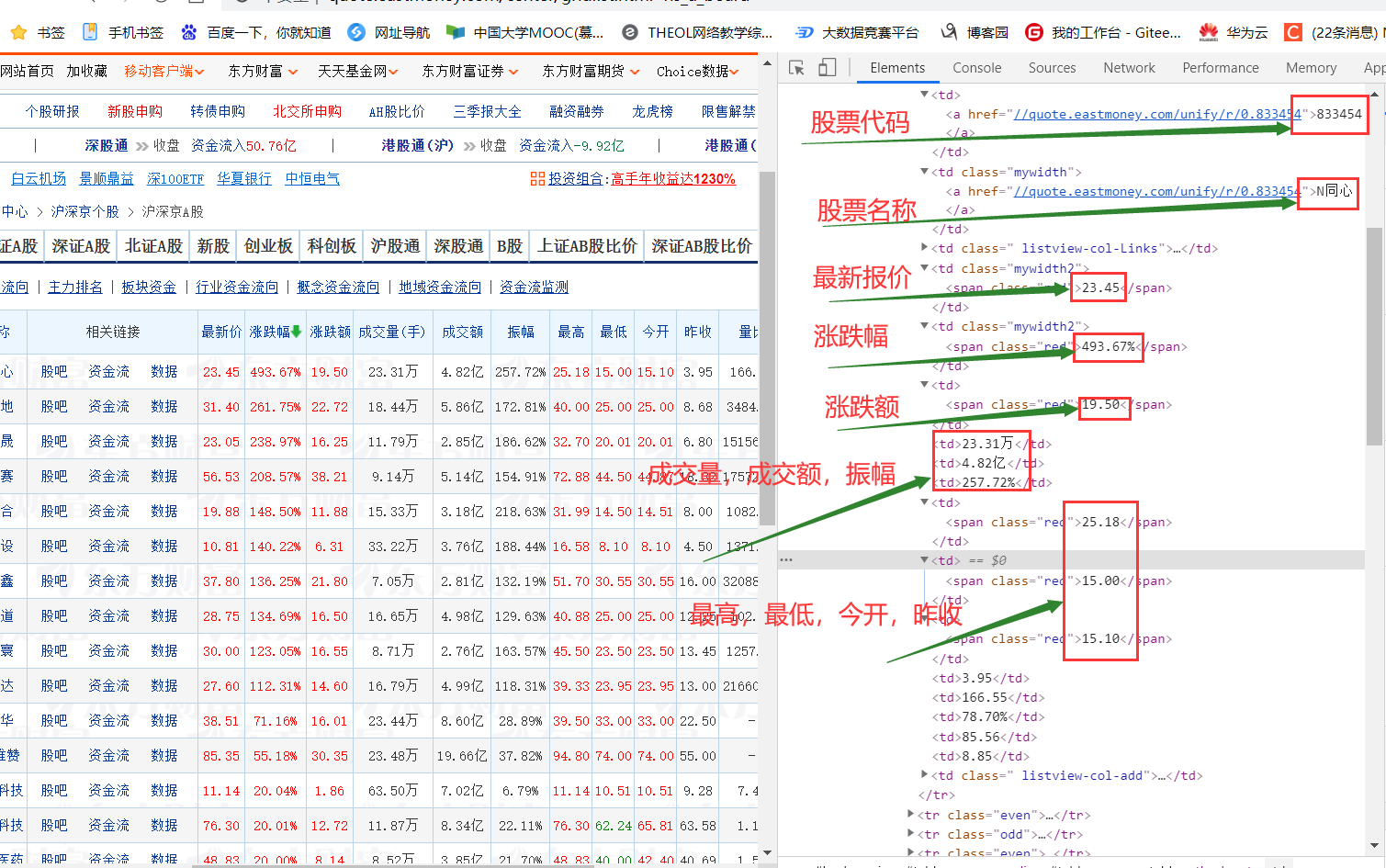
trs = self.driver.find_elements_by_xpath('//*[@id="table_wrapper-table"]/tbody/tr')
for tr in trs:
try:
dm = tr.find_element_by_xpath("./td[2]/a").text
name = tr.find_element_by_xpath("./td[3]/a").text
new = tr.find_element_by_xpath("./td[5]/span").text
zdf = tr.find_element_by_xpath("./td[6]/span").text
zde = tr.find_element_by_xpath("./td[7]/span").text
cjl = tr.find_element_by_xpath("./td[8]").text
cje = tr.find_element_by_xpath("./td[9]").text
zf = tr.find_element_by_xpath("./td[10]").text
zg = tr.find_element_by_xpath("./td[11]/span").text
zd = tr.find_element_by_xpath("./td[12]/span").text
jk = tr.find_element_by_xpath("./td[13]/span").text
zs = tr.find_element_by_xpath("./td[14]").text3.2.2 板块部分和翻页处理
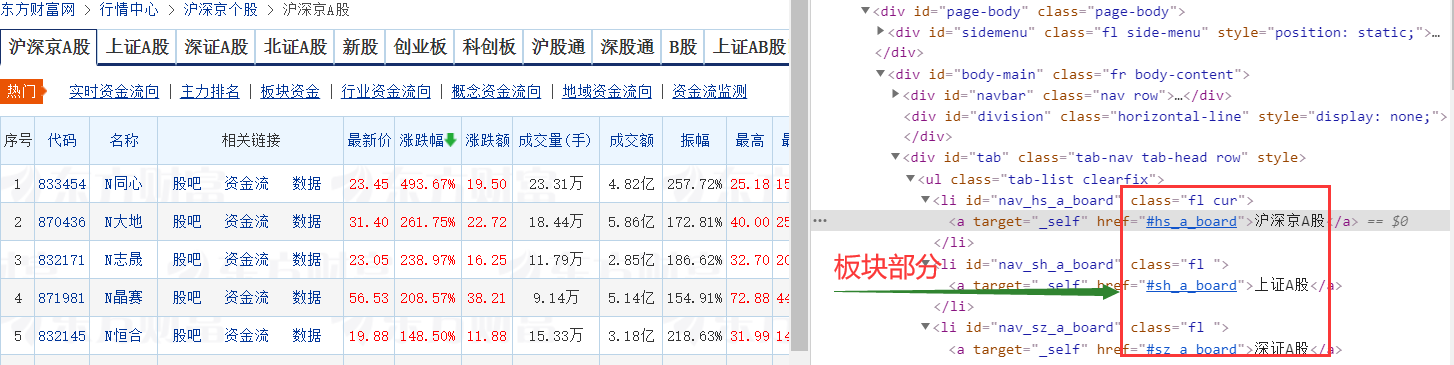
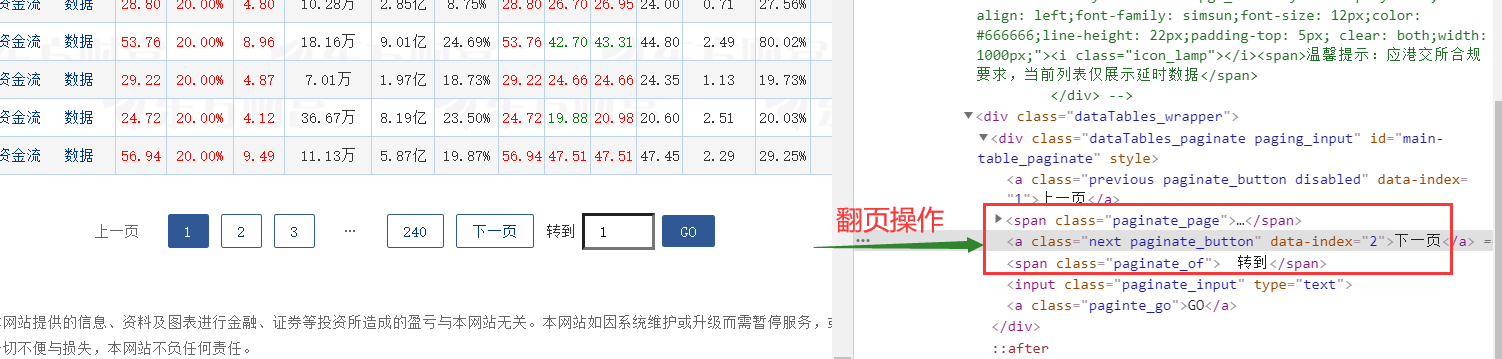
我是选择每个板块爬取两页数据,当page=2或=4时改变板块,其余情况进行翻页操作
if(self.page<6):
if(self.page==2):
self.driver.get('http://quote.eastmoney.com/center/gridlist.html#sh_a_board')
elif(self.page==4):
self.driver.get('http://quote.eastmoney.com/center/gridlist.html#sz_a_board')
else:
nextpage = self.driver.find_element_by_xpath("//a[@class='next paginate_button']")
nextpage.click()
self.page = self.page + 1
time.sleep(10)
self.processSpider()3.3 运行结果:
MySQL数据库结果:
控制台输出结果:
3.4 心得体会:
该作业我再次熟悉了selenium,以及熟练使用翻页处理和切换板块
切换板块时出现element is not attached to the page document,原因是页面数据未加载完全,解决方法是time.sleep(10);
