
第一次大作业
1.作业①:
要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
输出信息:
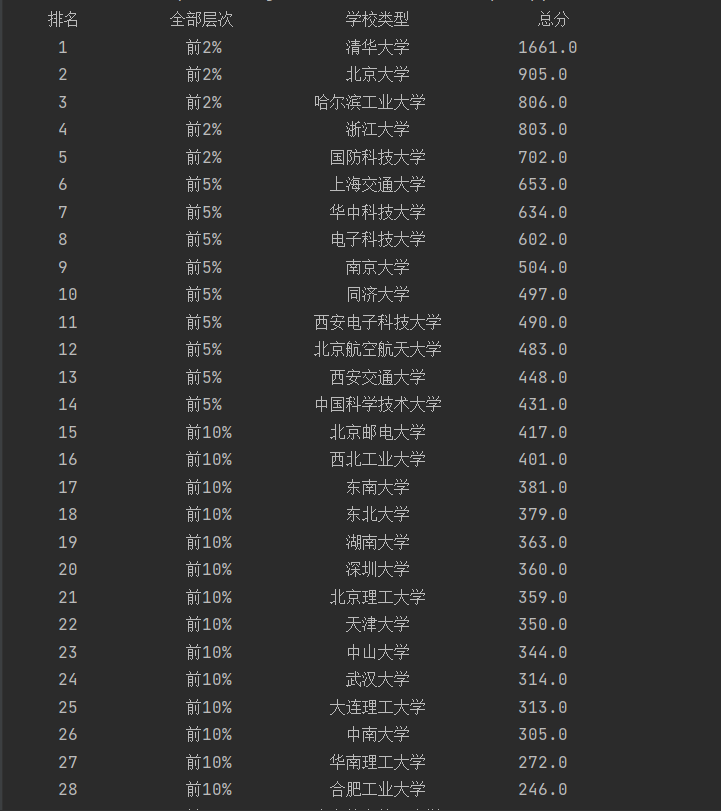
| 2020排名 | 全部层次 | 学校类型 | 总分 |
|---|---|---|---|
| 1 | 前2% | 中国人民大学 | 1069.0 |
| 2...... |
1)代码:
https://gitee.com/wjz51/wjz/blob/master/project_1/1_1.py
实验结果:
2)心得体会:
下述主要是关于正则表达式相关的体会,实验过程中在这方面耗时较久
re可以使用正则表达式(.*?),(.*?)对要匹配内容不做要求,更方便
例如(\s*.*?\s*)
re也可以使用匹配内容相对应的正则表达式
例如 data-v-b80b4d60>([\u2E80-\u9FFF]+)
上面匹配的就是中文字符,如“清华大学”
注意:其中的\s* 匹配空格或换行符
检查正则表达式是否匹配正确
我使用的软件是 Match Tracer
下载地址:
http://www.regexlab.com/zh/mtracer/download.htm
2.作业②:
要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
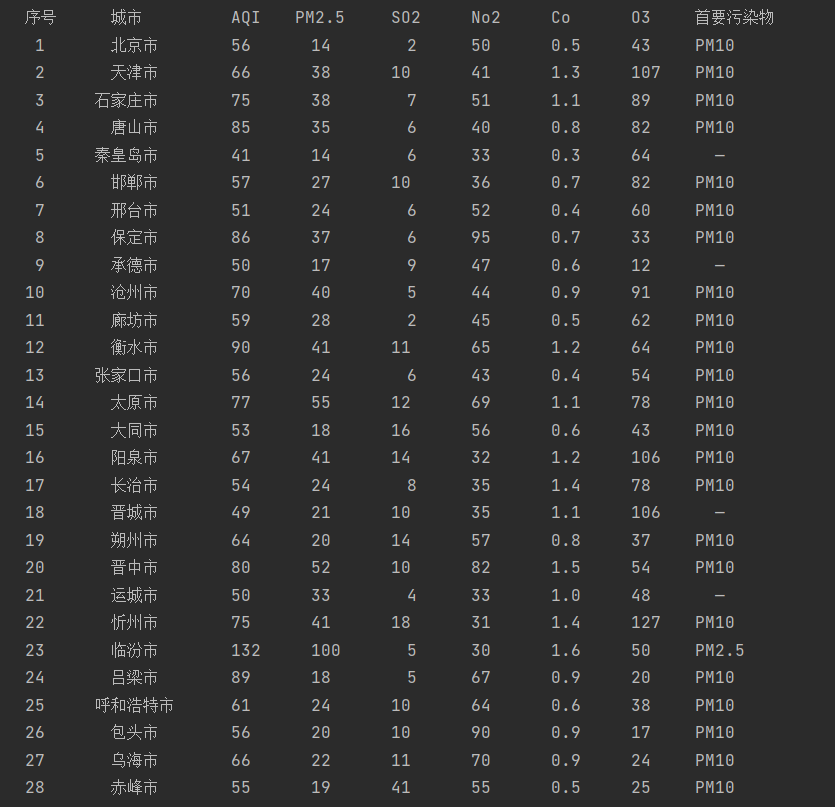
输出信息:
| 序号 | 城市 | AQI | PM2.5 | SO2 | No2 | Co | 首要污染物 |
|---|---|---|---|---|---|---|---|
| 1 | 北京 | 55 | 6 | 5 | 1.0 | 225 | — |
| 2...... |
1)代码:
https://gitee.com/wjz51/wjz/blob/master/project_1/1_2.py
实验结果:
2)心得体会:
主要是对网页爬取运用BeautifulSoup进行理解如下:
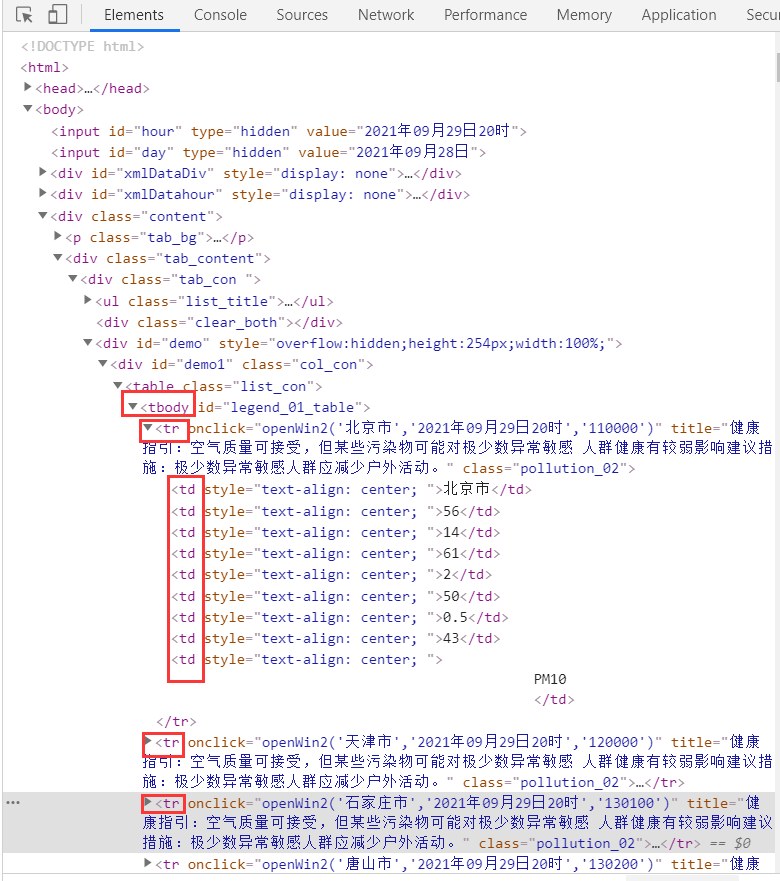
由上图可以看出'tbody'作为各城市相关信息的父节点
'tr'作为单个城市相关信息
'td'则是相关污染信息
对'td'进行选择即可
3.作业③:
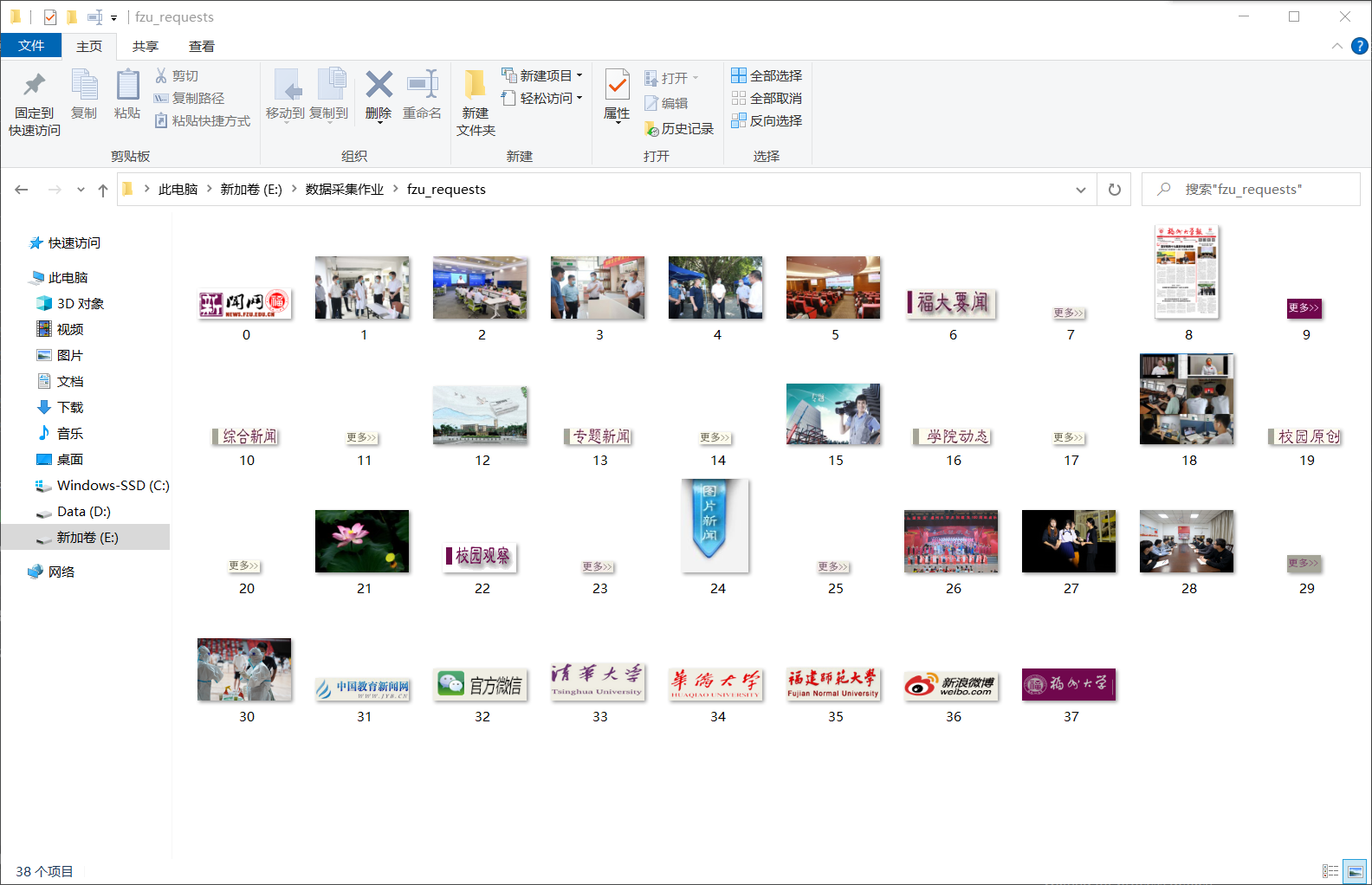
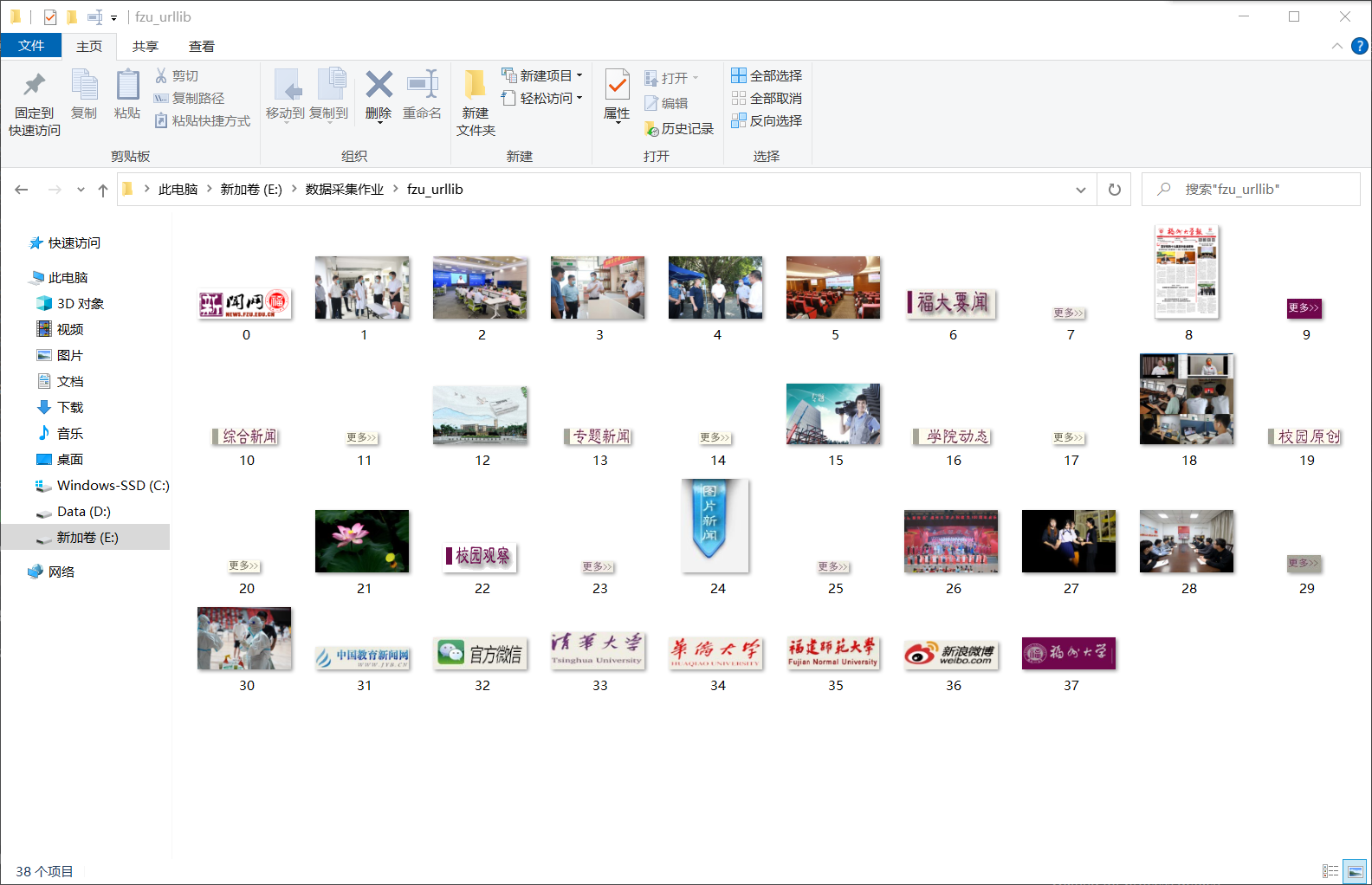
要求:使用urllib和requests和re爬取一个给定网页(https://news.fzu.edu.cn/)爬取该网站下的所有图片
3.1 requests和re
1)代码:
https://gitee.com/wjz51/wjz/blob/master/project_1/1_3_1.py
运行结果:
3.2 urllib和re
1)代码:
https://gitee.com/wjz51/wjz/blob/master/project_1/1_3_2.py
运行结果:
2)心得体会:
经过阅读HTML文件发现照片格式为<img src="(.*?)"

注意加入“http://news.fzu.edu.cn”才算正确的地址,如果不知道照片链接具体是什么,可以打开一个图片复制其网址查看
对部分函数进行说明:
函数:urllib.urlretrieve(url, filename, reporthook, data)
参数说明:
url:外部或者本地url
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
