大数据技术暑期实习三___大数据和Hadoop的大致概念及Ubuntu环境下Hadoop搭建及应用
1. 大数据
大数据是指无法在一定时间范围内用常规工具进行捕捉、管理和处理的数据集合,需要新的处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
主要解决海量数据的存储和分析计算问题。大数据的特点为(4V):Volume大量、Velocity高速、Variety多样、Value低价值密度。其核心技术即分布式存储,分布式处理。
大数据帮助人们进行精准化定制及预测,典型的案例如超市系统的啤酒和尿布的例子,电商平台的推荐系统,交通系统对路况数据的预测等。
2. Hadoop
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。Hadoop的优势:
A. 高可靠性: Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
B. 高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
C. 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
D. 高容错性:能够自动将失败的任务重新分配。
现在的hadoop版本一般为2.x相比1.x中MapReduce既负责计算又负责资源调度,2.x中新加入了yarn,他负责资源调度,而MapReduce仅负责计算,即从封闭式到可调度外部资源,能更好的适应需求。
2.1 HDFS
HDFS即分布式文件存储。
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)SecondaryNameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
2.2 MapReduce
MapReduce将计算过程分为两个阶段:Map和Reduce,
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
3. Hadoop环境搭建及wordcount程序运行
3.1 Linux环境中Hadoop伪分布式的搭建
ps:今天在重新调试Hadoop运行环境时,出现了DataNode,NameNode, SecondaryNameNode未能同时启动的情况,
后来发现时因为重新配置Hadoop时,格式化NameNode次数过多导致的,Hadoop根目录下tmp文件夹中的临时文件中DataNode,NameNode的ID不一致,无法匹配。
解决:关闭Hadoop进程后,清空tmp文件夹中内容,重新格式化NameNode,重启Hadoop即可,若输入jps命令发现SecondaryNameNode不能启动,则可以尝试重启Hadoop进程,还不行的话,可以重启一下虚拟机。

解压后,将此jar包直接放在虚拟机中eclipse安装根目录,plugin文件夹下
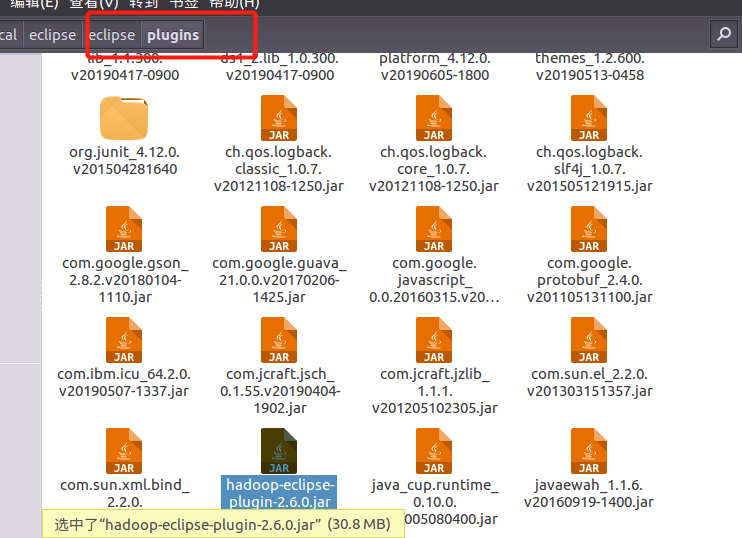
重启eclipse,启动eclipse之后会有hdfs的文件系统,打开mapreduce视窗,若没有该mapreduce视窗选项,建议重装eclipse或检查Hadoop版本是否匹配
我的Hadoop版本为2.7.1,一般比此版本低的2.x版本应该都没问题。


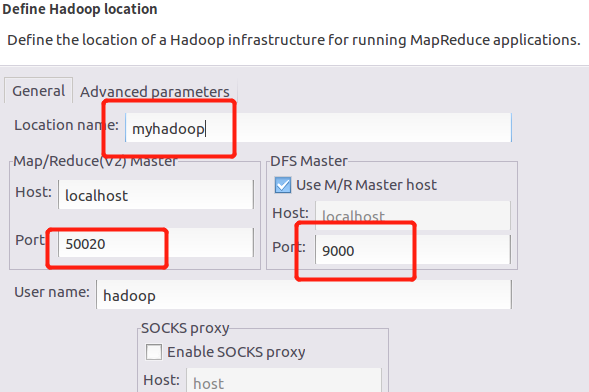
新建一个Hadoop连接,如果你是按照上述方式搭建的Hadoop,这两个端口就是这样
如果不是的话,左边的端口号要与Hadoop的xml配置文件dfs-site.xml中保持一致,右边的host端口号要与core-site.xml保持一致
3.3 实例
实例一WordCount
在本地新建一个test.txt文件,内容为
hello world hello hadoop world count

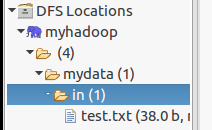
将linux本地 test.txt 上传到HDFS上的/mydata/in目录下。若HDFS目录不存在,需提前创建。
hadoop fs -mkdir -p /mydata/in
hadoop fs -put /usr/local/hadoop/test.txt /mydata/in
![]()
刷新eclipse的hdfs文件系统发现文件已经上传成功
新建一个MapReduce项目,编写java代码


import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * * @author 20163490 王敬斯 * @data 2019/9/3 * @todo Simple counting with Hadoop */ public class WordCount { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job job = Job.getInstance(); job.setJobName("WordCount"); // Job名称 //mapreduce调用 job.setJarByClass(WordCount.class); job.setMapperClass(doMapper.class); job.setReducerClass(doReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); Path in = new Path("hdfs://localhost:9000/mydata/in/test.txt"); //文件输入绝对路径 Path out = new Path("hdfs://localhost:9000/mydata/out"); //文件输出绝对路径 FileInputFormat.addInputPath(job, in); FileOutputFormat.setOutputPath(job, out); System.exit(job.waitForCompletion(true) ? 0 : 1); } //Mapper 文本切割 public static class doMapper extends Mapper<Object, Text, Text, IntWritable>{ /* 第一个Object表示输入key的类型 * 第二个Text表示输入value的类型 * 第三个Text表示表示输出键的类型 * 第四个IntWritable表示输出值的类型 */ public static final IntWritable one = new IntWritable(1); public static Text word = new Text(); @Override protected void map(Object key, Text value, Context context) // throws IOException, InterruptedException { StringTokenizer tokenizer = new StringTokenizer(value.toString(), "\t"); //通过空格进行分类 word.set(tokenizer.nextToken()); context.write(word, one); } } //Reduce 汇总计数,参数同Map public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ private IntWritable result = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; //循环遍历 for (IntWritable value : values) { sum += value.get(); //value一样则sum+1 } result.set(sum); context.write(key, result); //输出结果 } } }
运行选择run on hadoop
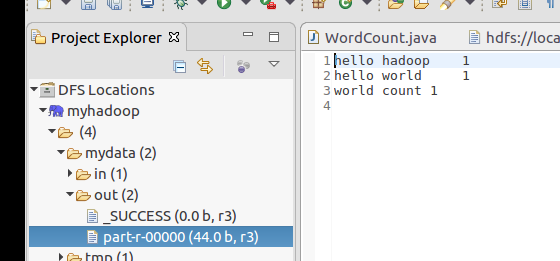
刷新hdfs文件,发现在out输出文件夹中有输出文件
实例二 Pi值计算
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.io.Text; import java.io.IOException; import java.util.Random; /** * 在正方形内生成的样本点越多,计算Pi值越精确,这样,这个问题就很适合用Hadoop来处理啦。假设要在正方形内生成1000万个点,可以设置10个Map任务,每个Map任务处理100万个点,也可以设置100个Map任务,每个Map任务处理10万个点。 */ public class CalPI { public static class PiMapper extends Mapper<Object, Text, Text, IntWritable>{ private static Random rd = new Random(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { int pointNum = Integer.parseInt(value.toString()); for(int i = 0; i < pointNum; i++){ // 取随机数 double x = rd.nextDouble(); double y = rd.nextDouble(); // 计算与(0.5,0.5)的距离,如果小于0.5就在单位圆里面 x -= 0.5; y -= 0.5; double distance = Math.sqrt(x*x + y*y); IntWritable result = new IntWritable(0); if (distance <= 0.5){ result = new IntWritable(1); } context.write(value, result); } } } public static class PiReducer extends Reducer<Text,IntWritable,Text,DoubleWritable> { private DoubleWritable result = new DoubleWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { double pointNum = Double.parseDouble(key.toString()); double sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum/pointNum*4); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf,"calculate pi"); job.setJarByClass(CalPI.class); job.setMapperClass(PiMapper.class); // job.setCombinerClass(PiReducer.class); job.setReducerClass(PiReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(DoubleWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
实例三 日志分析
需求一:去除日志中字段长度小于等于11的日志。
数据准备:(自己在电脑的任一日志文件中截取十几二十行就行)
需求二:对web访问日志中的各字段识别切分,去除日志中不合法的记录,根据统计需求,生成各类访问请求过滤数据。
数据准备:(自己在电脑的任一日志文件中截取十几二十行就行)
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 去除日志中字段长度小于等于11的日志。 * create date 2019.9.3 * author wangrenyi */ public class LogDriver { public static void main(String[] args) throws Exception { // 1 获取 job 信息 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 加载 jar 包 job.setJarByClass(LogDriver.class); // 3 关联 map job.setMapperClass(LogMapper.class); // 4 设置最终输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 设置 reducetask 个数为 0 job.setNumReduceTasks(0); // 5 设置输入和输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6 提交 job.waitForCompletion(true); } } MapperClass: package stdu.wry.mapreduce.log1; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> { private Text k = new Text(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { // 1 获取 1 行数据 String line = value.toString(); // 2 解析日志 boolean result = parseLog(line, context); // 3 日志不合法退出 if (!result) { return; } // 4 设置 key k.set(line); // 5 写出数据 context.write(k, NullWritable.get()); } // 解析日志 private boolean parseLog(String line, Mapper<LongWritable, Text, Text, NullWritable>.Context context) { // 切割 String[] fields = line.split(" "); if (fields.length > 11) { // 系统计数器 context.getCounter("LogMapper", "parseLog_true").increment(1); return true; } else { context.getCounter("LogMapper", "parseLog_false").increment(1); return false; } } }
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 对web访问日志中的各字段识别切分,去除日志中不合法的记录,根据统计需求,生成各类访问请求过滤数据。 * create date 2019.9.3 * author wangrenyi */ public class LogDriver { public static void main(String[] args) throws Exception { // 1 获取 job 信息 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 加载 jar 包 job.setJarByClass(LogDriver.class); // 3 关联 map job.setMapperClass(LogMapper.class); // 4 设置最终输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 5 设置输入和输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6 提交 job.waitForCompletion(true); } } package stdu.wry.mapreduce.log2; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 对web访问日志中的各字段识别切分,去除日志中不合法的记录,根据统计需求,生成各类访问请求过滤数据。 * create date 2019.9.3 * author wangrenyi */ public class LogDriver { public static void main(String[] args) throws Exception { // 1 获取 job 信息 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 加载 jar 包 job.setJarByClass(LogDriver.class); // 3 关联 map job.setMapperClass(LogMapper.class); // 4 设置最终输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 5 设置输入和输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6 提交 job.waitForCompletion(true); } } package stdu.wry.mapreduce.log2; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> { Text k = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取 1 行 String line = value.toString(); // 2 解析日志是否合法 LogBean bean = pressLog(line); if (!bean.isValid()) { return; } k.set(bean.toString()); // 3 输出 context.write(k, NullWritable.get()); } // 解析日志 private LogBean pressLog(String line) { LogBean logBean = new LogBean(); // 1 截取 String[] fields = line.split(" "); if (fields.length > 11) { // 2 封装数据 logBean.setRemote_addr(fields[0]); logBean.setRemote_user(fields[1]); logBean.setTime_local(fields[3].substring(1)); logBean.setRequest(fields[6]); logBean.setStatus(fields[8]); logBean.setBody_bytes_sent(fields[9]); logBean.setHttp_referer(fields[10]); if (fields.length > 12) { logBean.setHttp_user_agent(fields[11] + " " + fields[12]); } else { logBean.setHttp_user_agent(fields[11]); } // 大于 400, HTTP 错误 if (Integer.parseInt(logBean.getStatus()) >= 400) { logBean.setValid(false); } } else { logBean.setValid(false); } return logBean; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号