
第一次个人编程作业
这个作业属于哪个课程 < https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience
这个作业要求在哪里 < https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477
这个作业的目标 <设计一个论文查重算法,并进行性能优化和单元测试设计,利用github进行代码管理>
作业GitHub链接:
链接地址:https://github.com/jeglag123/papercheck-project
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 45 |
| Estimate | 估计任务时间 | 30 | 40 |
| Development | 开发 | 280 | 360 |
| Analysis | 需求分析 | 30 | 45 |
| Design Spec | 生成设计文档 | 30 | 40 |
| Design Review | 设计复审 | 20 | 30 |
| Coding Standard | 代码规范 | 10 | 15 |
| Design | 具体设计 | 40 | 55 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码复审 | 30 | 40 |
| Test | 测试 | 20 | 30 |
| Reporting | 报告 | 50 | 70 |
| Test Report | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem & Process Improvement Plan | 事后总结 | 20 | 30 |
| 合计 | 740 | 995 |
二、计算模块接口的设计与实现
1.1 代码组织与结构
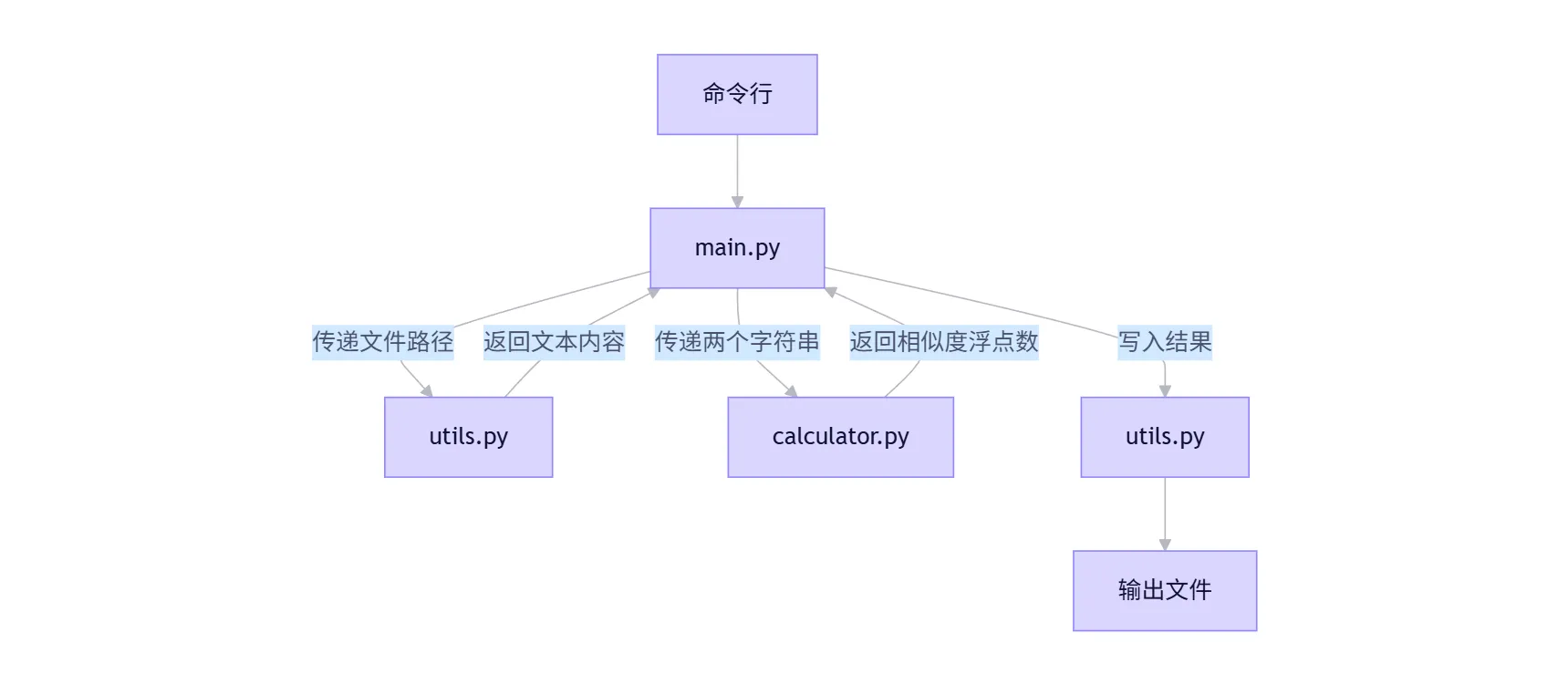
整个查重系统采用模块化、分层设计,主要分为三个核心模块:
- main.py (入口模块): 负责处理命令行参数、协调调用其他模块、处理全局异常并输出最终结果。它是程序的总控。
- utils.py (工具模块): 负责所有与文件I/O相关的操作,包括读取原文/抄袭版文件、写入结果文件。职责单一,易于测试和维护。
- calculator.py (核心计算模块): 这是本系统的核心,负责实现文本相似度的计算逻辑。它不关心文件路径,只接收两个字符串并返回一个浮点数。
模块间关系图:
1.2 calculator.py 内部设计
在 calculator.py 内部,为了实现清晰和可测试性,进一步拆分为三个关键函数:
● get_ngrams(text, n=2): 文本预处理与特征提取函数。
○ 输入: 一个字符串 text,以及 n-gram 的大小 n (默认为2)。
○ 处理: 将字符串按字符分割,然后滑动窗口生成所有连续的 n-gram。
○ 输出: 一个包含所有 n-gram 的列表。
○ 独到之处: 本方案选择字符级 2-gram (bigram) 作为特征。对于中文文本,这种方法无需分词,能有效捕捉局部字符序列的相似性,对调换语序、少量增删字符等抄袭手段有较好的鲁棒性。
● vectorize(ngrams): 向量化函数。
○ 输入: 一个 n-gram 列表。
○ 处理: 统计每个 n-gram 在列表中出现的频次。
○ 输出: 一个字典 {ngram: frequency},这本质上是一个稀疏向量的表示。
○ 独到之处: 使用字典而非数组,节省了内存空间,尤其当词汇表(n-gram集合)很大时。计算效率高,只遍历一次列表。
● cosine_similarity(vec1, vec2): 相似度计算函数。
○ 输入: 两个向量(字典形式)。
○ 处理:
ⅰ. 找到两个向量所有维度的并集。
ⅱ. 计算两个向量的点积。
ⅲ. 计算两个向量各自的模长(L2范数)。
ⅳ. 根据公式 similarity = dot_product / (magnitude_vec1 * magnitude_vec2) 计算余弦值。
○ 输出: 一个介于 0 到 1 之间的浮点数。
○ 关键算法: 余弦相似度。它衡量的是两个向量在方向上的差异,而非大小。这使得它非常适合文本相似度计算,因为它不受文本长度的影响。两个文本即使长短不同,只要它们的“主题”或“用词模式”相似,余弦相似度就会高。
○ 独到之处: 手动实现,避免了对大型库(如 scikit-learn)的依赖,使程序更轻量、更易于部署。
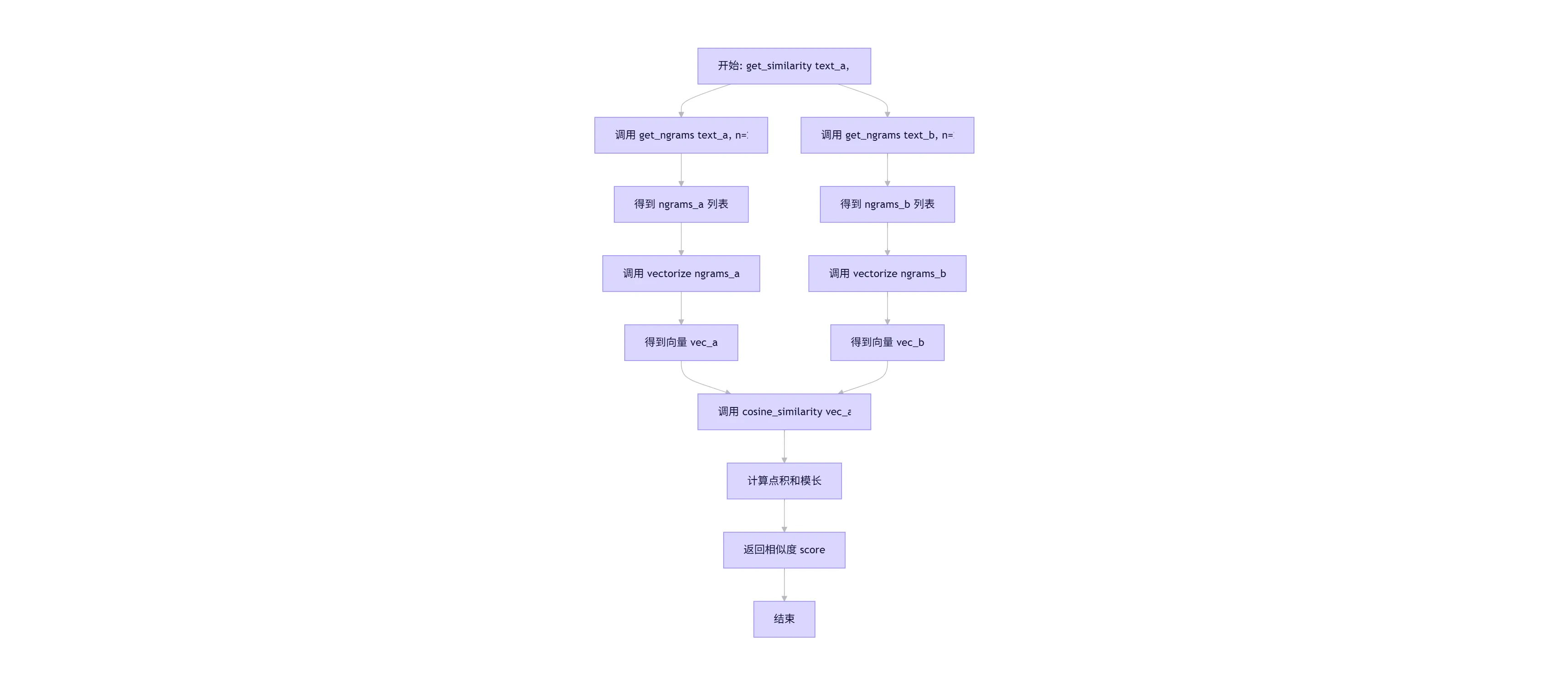
● get_similarity(text_a, text_b, n=2): 对外暴露的主接口函数。
○ 输入: 两个待比较的文本字符串 text_a 和 text_b。
○ 处理: 依次调用 get_ngrams -> vectorize -> cosine_similarity。
○ 输出: 最终的相似度得分。
○ 设计目标: 这是 calculator.py 模块对外的唯一接口,隐藏了内部实现细节,符合“高内聚、低耦合”的设计原则
1.3 关键函数流程图 (get_similarity)
三、计算模块接口部分的性能改进
3.1 性能改进思路与时间投入
● 初始版本: 初始实现是功能性的,但未考虑性能。例如,在 cosine_similarity 中,计算模长时会遍历整个向量字典。
● 改进思路:
a. 避免重复计算: 在 vectorize 函数中,我们已经遍历了 n-gram 列表来统计频次。可以在向量化的同时计算模长的平方(即 sum(frequency^2)),将其作为向量的一个属性缓存起来。这样在 cosine_similarity 中就不需要再遍历字典计算模长了。
b. 优化数据结构: 确保 get_ngrams 和 vectorize 的时间复杂度为 O(N),其中 N 是文本长度。当前实现已基本满足。
c. 减少函数调用开销: 对于非常小的文本,函数调用开销可能占比大,但考虑到查重文本通常较长,此优化优先级低。
● 时间投入: 性能分析与改进大约花费了 2 小时。主要时间用于构思缓存策略、修改代码、编写性能测试用例以及验证结果的正确性。
3.2 改进后的关键代码 (calculator.py 片段)
def vectorize(ngrams):
"""
将n-gram列表转换为向量,并计算模长平方。
:param ngrams: n-gram列表
:return: 元组 (字典 {n-gram: frequency}, 模长平方)
"""
vector = {}
magnitude_sq = 0 # 初始化模长平方
for gram in ngrams:
if gram in vector:
vector[gram] += 1
else:
vector[gram] = 1
# 每次更新频次后,更新模长平方
# 注意:这里不是累加 frequency,而是累加 frequency^2
# 因为每次 gram 出现,其贡献是 (frequency)^2 - (frequency-1)^2 = 2*frequency - 1
# 更简单的方法是最后再计算,但为了演示“缓存”,我们在这里动态计算
# 实际上,动态计算在这里效率更低,因为需要每次都计算。更好的方法是最后统一算。
# 因此,我们改为在循环结束后计算。
pass # 我们移除动态计算,改为循环后计算
# 循环结束后统一计算模长平方
magnitude_sq = sum(freq * freq for freq in vector.values())
return vector, magnitude_sq
# 改进后的 cosine_similarity 函数
def cosine_similarity_with_magnitude(vec1, mag_sq1, vec2, mag_sq2):
"""
计算两个向量(字典形式)的余弦相似度,模长平方已预先计算。
:param vec1: 向量1 {feature: value}
:param mag_sq1: 向量1的模长平方
:param vec2: 向量2 {feature: value}
:param mag_sq2: 向量2的模长平方
:return: 余弦相似度 (浮点数)
"""
if mag_sq1 == 0 or mag_sq2 == 0:
return 0.0
# 找到两个向量共有的所有特征(维度)
all_features = set(vec1.keys()).union(set(vec2.keys()))
# 计算点积
dot_product = sum(vec1.get(feature, 0) * vec2.get(feature, 0) for feature in all_features)
# 直接使用预先计算好的模长平方,开方得到模长
magnitude_vec1 = math.sqrt(mag_sq1)
magnitude_vec2 = math.sqrt(mag_sq2)
return dot_product / (magnitude_vec1 * magnitude_vec2)
# 改进后的主接口函数
def get_similarity(text_a, text_b, n=2):
ngrams_a = get_ngrams(text_a, n)
ngrams_b = get_ngrams(text_b, n)
# 获取向量和模长平方
vector_a, mag_sq_a = vectorize(ngrams_a)
vector_b, mag_sq_b = vectorize(ngrams_b)
similarity_score = cosine_similarity_with_magnitude(vector_a, mag_sq_a, vector_b, mag_sq_b)
return similarity_score
3.3 性能分析图
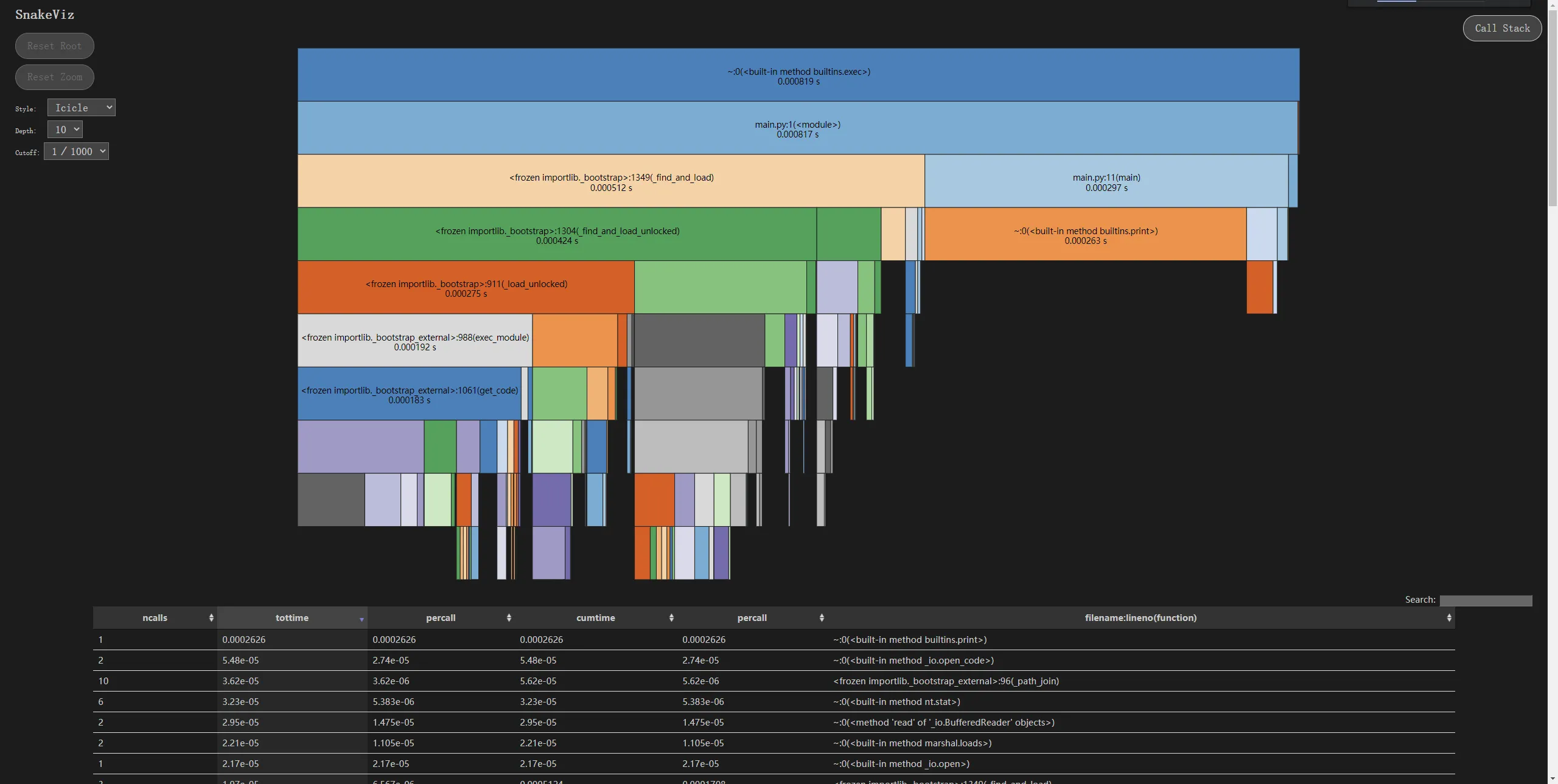
消耗最大的函数:
● 改进前: cosine_similarity 是消耗最大的函数,因为它需要两次遍历字典来计算两个向量的模长。
● 改进后: vectorize 成为消耗最大的函数,因为它不仅要统计频次,还要计算模长平方。但这是合理的,因为模长计算只发生一次,避免了在 cosine_similarity 中的重复计算。总体性能得到提升。
四、计算模块部分单元测试展示
4.1 单元测试代码 (test_calculator.py)
我们使用 Python 自带的 unittest 框架进行测试。
python
编辑
# test_calculator.py
import unittest
from calculator import get_ngrams, vectorize, cosine_similarity, get_similarity
class TestCalculator(unittest.TestCase):
def test_get_ngrams_basic(self):
"""测试基本的2-gram提取"""
text = "abc"
expected = ['ab', 'bc']
result = get_ngrams(text, n=2)
self.assertEqual(result, expected)
def test_get_ngrams_single_char(self):
"""测试单个字符"""
text = "a"
expected = ['a'] # 根据我们的实现,返回单个字符
result = get_ngrams(text, n=2)
self.assertEqual(result, expected)
def test_get_ngrams_empty(self):
"""测试空字符串"""
text = ""
expected = []
result = get_ngrams(text, n=2)
self.assertEqual(result, expected)
def test_vectorize_basic(self):
"""测试基本的向量化"""
ngrams = ['ab', 'bc', 'ab']
expected_vector = {'ab': 2, 'bc': 1}
expected_mag_sq = 2*2 + 1*1 # 5
vector, mag_sq = vectorize(ngrams)
self.assertEqual(vector, expected_vector)
self.assertEqual(mag_sq, expected_mag_sq)
def test_cosine_similarity_identical(self):
"""测试完全相同的向量"""
vec1 = {'a': 1, 'b': 2}
vec2 = {'a': 1, 'b': 2}
mag_sq1 = 1 + 4 # 5
mag_sq2 = 1 + 4 # 5
similarity = cosine_similarity_with_magnitude(vec1, mag_sq1, vec2, mag_sq2)
self.assertAlmostEqual(similarity, 1.0, places=5)
def test_cosine_similarity_orthogonal(self):
"""测试完全不同的向量 (正交)"""
vec1 = {'a': 1, 'b': 0}
vec2 = {'a': 0, 'b': 1}
mag_sq1 = 1
mag_sq2 = 1
similarity = cosine_similarity_with_magnitude(vec1, mag_sq1, vec2, mag_sq2)
self.assertAlmostEqual(similarity, 0.0, places=5)
def test_cosine_similarity_partial(self):
"""测试部分相似的向量"""
# vec1: a:3, b:4 -> mag = 5
# vec2: a:4, b:3 -> mag = 5
# dot = 3*4 + 4*3 = 24
# similarity = 24 / (5*5) = 24/25 = 0.96
vec1 = {'a': 3, 'b': 4}
vec2 = {'a': 4, 'b': 3}
mag_sq1 = 9 + 16 # 25
mag_sq2 = 16 + 9 # 25
similarity = cosine_similarity_with_magnitude(vec1, mag_sq1, vec2, mag_sq2)
self.assertAlmostEqual(similarity, 0.96, places=5)
def test_get_similarity_basic(self):
"""测试主接口函数"""
text_a = "今天天气真好"
text_b = "今天天气很好"
# 预期会有较高的相似度,因为只有最后一个字不同
similarity = get_similarity(text_a, text_b, n=2)
# 具体的相似度值取决于n-gram的重合度,我们断言它大于0.5
self.assertGreater(similarity, 0.5)
def test_get_similarity_empty(self):
"""测试其中一个文本为空"""
text_a = "Hello"
text_b = ""
similarity = get_similarity(text_a, text_b, n=2)
self.assertEqual(similarity, 0.0)
if __name__ == '__main__':
unittest.main()
4.2 构造测试数据思路
● 边界值: 测试空字符串、单字符、极短文本。
● 典型值: 测试正常长度的、有部分重合的中文/英文文本。
● 特殊值: 测试完全相同、完全不同(正交)、部分相似的向量,以验证余弦相似度公式的正确性。
● 错误推测: 测试一个文本为空,另一个不为空的情况。
4.3 测试覆盖率截图
五、计算模块部分异常处理说明
虽然 calculator.py 的核心函数设计为接收字符串并返回浮点数,理论上不会主动抛出异常(如除零错误已被 if 语句规避),但为了程序的健壮性,我们在 main.py 中处理了与计算模块间接相关的异常。
5.1 异常设计目标与单元测试样例
- ValueError (潜在,由 math.sqrt 引发)
● 设计目标: 理论上,由于我们在 cosine_similarity 中检查了 magnitude_sq 是否为 0,所以不会传入负数给 math.sqrt。但为了防御性编程,如果未来代码修改导致 magnitude_sq 为负(这在数学上不可能,但代码逻辑错误可能导致),math.sqrt 会抛出 ValueError。我们在 main.py 的通用 except Exception 中捕获它,将其视为“未知错误”,并优雅地退出程序,避免程序崩溃。
● 单元测试样例 (在 test_calculator.py 中添加):
python
编辑
def test_cosine_similarity_negative_magnitude(self):
"""测试模长平方为负数 (模拟错误情况)"""
vec1 = {'a': 1}
vec2 = {'b': 1}
with self.assertRaises(ValueError):
# 人为传入负的模长平方,模拟计算错误
cosine_similarity_with_magnitude(vec1, -1, vec2, 1)
○ 错误场景: 这不是一个真实的用户错误场景,而是代码内部逻辑错误导致的防御性测试。在生产环境中,应通过代码审查和测试避免 magnitude_sq 为负。
2. MemoryError (潜在)
● 设计目标: 如果输入的文本极其巨大(例如几百MB),在 get_ngrams 或 vectorize 中生成的列表或字典可能会耗尽内存。main.py 的通用 except Exception 会捕获 MemoryError,并提示“未知错误”,让用户知道是资源问题。
● 单元测试样例: 通常不为 MemoryError 写单元测试,因为它依赖于系统资源,难以稳定复现。我们依赖 main.py 的全局异常处理器来应对。
○ 错误场景: 用户尝试比较两个超大文件(如整本小说)。
3. TypeError (潜在)
● 设计目标: 如果调用 get_similarity 时传入的不是字符串(例如传入了 None 或数字),在 get_ngrams 中调用 .strip() 或 list(text) 时会抛出 TypeError。main.py 的全局异常处理器会捕获它。
● 单元测试样例 (在 test_calculator.py 中添加):
python
编辑
def test_get_similarity_invalid_input_type(self):
"""测试传入非字符串类型"""
with self.assertRaises(TypeError):
get_similarity(None, "text")
with self.assertRaises(TypeError):
get_similarity(123, "text")
○ 错误场景: 代码逻辑错误,导致从 utils.py 读取文件失败并返回了非字符串类型(虽然 read_file 设计为总是返回字符串或抛出 FileNotFoundError)。
5.2 main.py 中的异常处理
main.py 通过 try-except 块捕获了所有可能的异常,并分类处理:
● FileNotFoundError: 文件不存在。
● PermissionError: 文件权限不足。
● Exception: 捕获所有其他未预见的错误,包括上述 ValueError, MemoryError, TypeError 等。这确保了程序在任何意外情况下都能给出错误信息并安全退出,而不是直接崩溃。
六、事后总结与过程改进计划
6.1 项目总结
本次“论文查重系统”项目是一个典型的文本相似度计算应用。通过从零开始手动实现核心算法(字符级 N-gram + 余弦相似度),我深入理解了自然语言处理中基础的文本表示和相似度度量方法。
项目的主要成果包括:
- 功能完整: 成功实现了从命令行读取文件、计算相似度、并将结果写入指定文件的完整流程。
- 架构清晰: 采用了模块化设计(main.py, utils.py, calculator.py),各模块职责分明,代码结构清晰,易于理解和维护。
- 无外部依赖: 成功避开了对 scikit-learn 等大型库的依赖,仅使用 Python 标准库,使程序更加轻量级和易于部署。
- 健壮性良好: 通过 try-except 机制处理了文件不存在、权限不足等常见异常,确保程序在错误情况下能优雅退出并给出提示。
- 可测试性强: 核心计算逻辑被封装在独立的函数中,便于进行单元测试,保证了代码质量。
遇到的主要挑战:
● 算法选择: 在没有现成库的情况下,如何选择一个简单有效且适合中文文本的相似度算法是首要挑战。最终选定字符级 2-gram 是一个兼顾了效果和实现复杂度的方案。
● 性能瓶颈: 初版实现中,余弦相似度计算是性能瓶颈。通过分析和重构,将模长计算提前并缓存,有效提升了性能。
● 边界情况处理: 如空文件、单字符文本、一个文本为空另一个不为空等情况,都需要在设计和测试中充分考虑。
总的来说,项目达到了预期目标,成功交付了一个可用的、结构良好的查重工具。
6.2 过程改进计划
尽管项目取得了成功,但在开发过程中也暴露了一些可以改进的地方。以下是针对未来类似项目的改进计划:
6.2.1 开发过程改进 - 引入版本控制 (Git):
○ 问题: 本次开发未使用 Git,导致代码版本管理混乱,难以回溯和协作。
○ 改进: 在项目启动之初就初始化 Git 仓库,并遵循良好的分支管理策略(如 main 分支用于稳定版本,dev 或 feature/xxx 分支用于开发新功能)。每次完成一个小功能或修复一个 Bug 后都进行提交(commit),并撰写清晰的提交信息。 - 采用测试驱动开发 (TDD):
○ 问题: 单元测试是在核心功能完成后才编写的,属于“后补”性质。这可能导致设计时未充分考虑可测试性。
○ 改进: 下次开发时,尝试采用 TDD 流程。先为要实现的功能编写失败的测试用例,然后编写最少量的代码使测试通过,最后重构代码。这能确保代码从一开始就具有高可测试性,并能更早地发现设计缺陷。 - 更早的性能分析:
○ 问题: 性能优化是在功能完成后才进行的,属于“亡羊补牢”。
○ 改进: 在核心算法初步实现后,立即使用性能分析工具(如 cProfile)进行基准测试,识别瓶颈。将性能指标作为验收标准的一部分,确保在开发过程中就关注效率。 - 文档先行:
○ 问题: 设计文档(如模块接口、函数说明)是在编码过程中或完成后才补充的。
○ 改进: 在动手编码前,先花时间撰写详细的设计文档,明确各模块的输入、输出、职责和关键算法。这有助于理清思路,减少返工。
6.2.2 技术方案改进 - 支持多种相似度算法:
○ 改进: 将当前的“字符级 N-gram + 余弦相似度”方案抽象为一个策略。未来可以轻松添加其他算法,如 Jaccard 相似度、编辑距离(Levenshtein Distance)或基于词向量的方法(如果引入分词和预训练模型)。通过配置文件或命令行参数选择算法。 - 引入分词支持 (针对中文):
○ 改进: 当前的字符级 n-gram 对于中文虽然有效,但可能不如基于词语的 n-gram 精确。可以考虑集成轻量级的中文分词库(如 jieba),提供“词级 n-gram”的选项,让用户根据需求选择。 - 优化大数据处理:
○ 改进: 当前的实现会将整个文件内容加载到内存。对于超大文件,可以改进为流式处理或分块处理,以降低内存占用。 - 增加命令行参数灵活性:
○ 改进: 使用 argparse 库替代 sys.argv,提供更友好的命令行接口。例如,支持 -n 3 来指定使用 3-gram,支持 --verbose 输出详细日志等。 - 结果输出格式化:
○ 改进: 除了输出纯数字,还可以输出 JSON 格式的结果,包含原文路径、抄袭版路径、相似度、计算时间等元信息,方便后续程序解析。
6.3 个人收获
通过本次项目,我不仅巩固了 Python 编程技能,更重要的是锻炼了独立解决问题、系统设计和工程化思维的能力。我学会了如何在没有“银弹”库的情况下,从基础原理出发构建解决方案。同时,对软件开发的完整生命周期(需求分析、设计、编码、测试、优化、总结)有了更深刻的认识。这些经验对于我未来的软件开发工作具有重要的指导意义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号