

一、主题式网络爬虫设计方案
1.主题式网络爬虫名称
名称:爬取阳光电影详细信息汇总
2.主题式网络爬虫爬取的内容与数据特征分析
本次爬虫主要爬取电影天堂华语电视剧信息
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
本次设计方案依靠request库访问,用BeautifulSoup分析网页结构获取数据,采集到的数据保存在本地。
二、主题页面的结构特征分析
1.最新电影列表页面结构分析

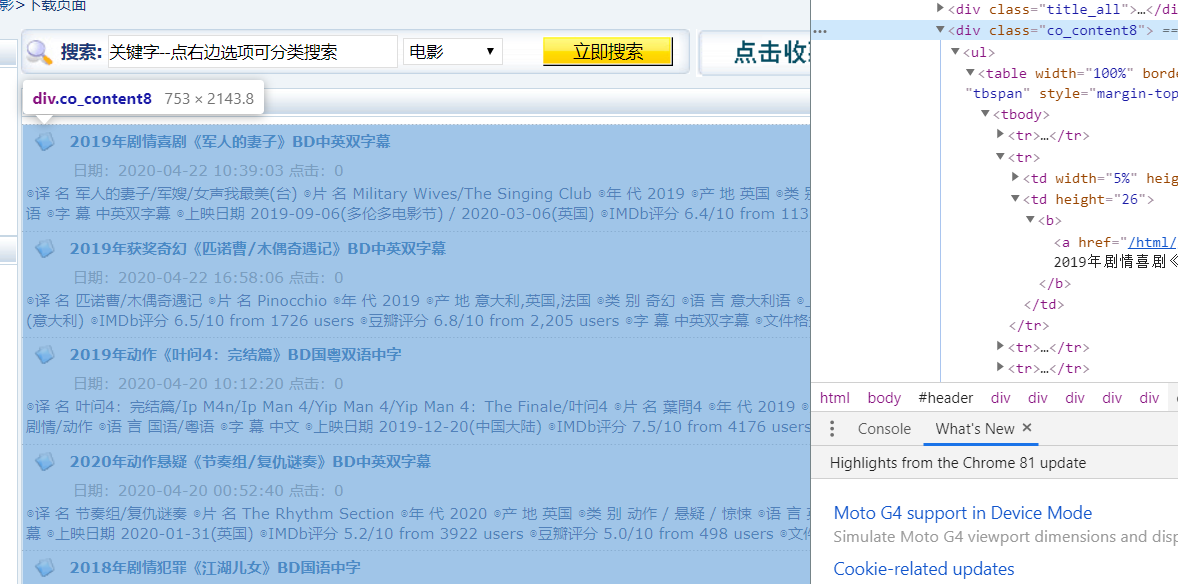
可以获取到框架的标签,在框架中拆分读取数据,获取内页地址
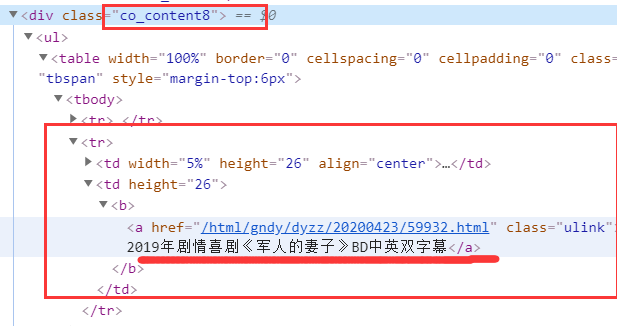
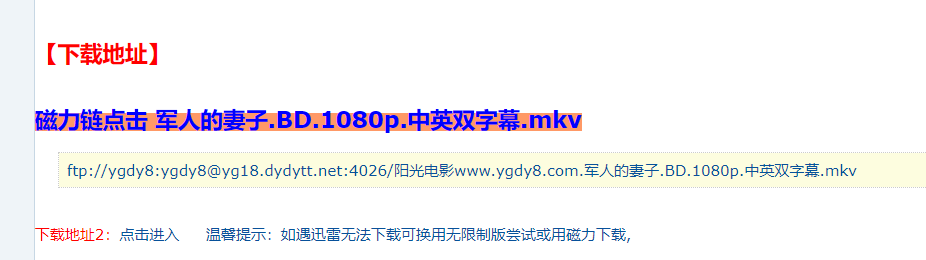

三、网络爬虫程序设计
1.爬取数据
def getVodList(): #获取目标页面 url = "https://www.ygdy8.net/html/gndy/dyzz/index.html" ua = {'user-agent':'Mozilla/5.0'} r = requests.get(url, headers=ua) r.raise_for_status() r.encoding = 'gbk' #使用GBK编码 #parse soup = BeautifulSoup(r.text, 'html.parser') #table.tbspan soup.find_all('table', class_='tbspan') #parse Title and Url for table in soup.find_all("a", class_='ulink'): videos_name.append(table.get_text()) videos_url.append(table.get('href'))
2.爬取内页数据
def getVideoInfo(url): #获取目标页面 ua = {'user-agent':'Mozilla/5.0'} r = requests.get('https://www.ygdy8.net' + url, headers=ua) r.raise_for_status() r.encoding = 'gbk' #parse soup = BeautifulSoup(r.text, 'html.parser') #td-bgcolor for table in soup.find_all('td', attrs={"bgcolor": "#fdfddf"}): down_url = table.get_text() return down_url
3.爬取详细数据
getVodList() #循环获取电影内页 for i, j in zip(videos_url, videos_name): down_url = getVideoInfo(i) print('[name] ', j) print('[down] ', down_url) videos.append(j + "|" + down_url) saveData(videos)
4.保存
def saveData(ulist): ''' 保存数据 ''' try: #创建文件夹 os.mkdir("C:\ygdy") except: #如果文件夹存在则什么也不做 "" try: #创建文件用于存储爬取到的数据 with open("C:\\ygdy\\new_move_list.txt","w") as f: for i in range(len(ulist)): f.write(ulist[i]) f.write('\n') except: "Error_saveData"
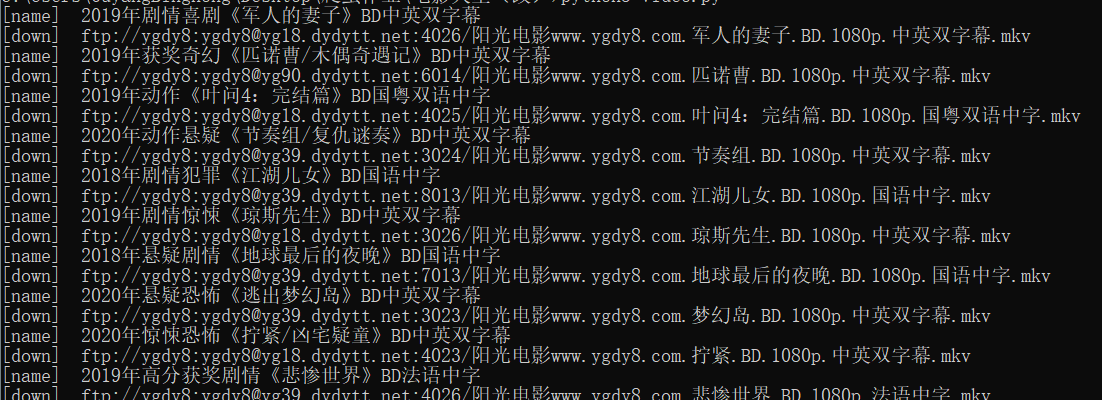
运行截图:
完整代码:
#!/usr/bin/env python # coding=utf-8 import requests from bs4 import BeautifulSoup import os import re videos_name = [] videos_url = [] videos = [] def getVodList(): #获取目标页面 url = "https://www.ygdy8.net/html/gndy/dyzz/index.html" ua = {'user-agent':'Mozilla/5.0'} r = requests.get(url, headers=ua) r.raise_for_status() r.encoding = 'gbk' #使用GBK编码 #parse soup = BeautifulSoup(r.text, 'html.parser') #table.tbspan soup.find_all('table', class_='tbspan') #parse Title and Url for table in soup.find_all("a", class_='ulink'): videos_name.append(table.get_text()) videos_url.append(table.get('href')) def getVideoInfo(url): #获取目标页面 ua = {'user-agent':'Mozilla/5.0'} r = requests.get('https://www.ygdy8.net' + url, headers=ua) r.raise_for_status() r.encoding = 'gbk' #parse soup = BeautifulSoup(r.text, 'html.parser') #td-bgcolor for table in soup.find_all('td', attrs={"bgcolor": "#fdfddf"}): down_url = table.get_text() return down_url def saveData(ulist): ''' 保存数据 ''' try: #创建文件夹 os.mkdir("C:\ygdy") except: #如果文件夹存在则什么也不做 "" try: #创建文件用于存储爬取到的数据 with open("C:\\ygdy\\new_move_list.txt","w") as f: for i in range(len(ulist)): f.write(ulist[i]) f.write('\n') except: "Error_saveData" getVodList() #循环获取电影内页 for i, j in zip(videos_url, videos_name): down_url = getVideoInfo(i) print('[name] ', j) print('[down] ', down_url) videos.append(j + "|" + down_url) saveData(videos)
四、结论
经过python对网络爬虫的学习,让自己深刻了解到了python这门语言强大的功能,以及对数据处理的简便与快捷,让数据以更生动
形象具体的方式呈现在我们眼前,同时了解到自身对这门语言的理解还不够透彻,在处理很多方面细节不够到位,让自己认识到更多
的不足,同时加深了对这门语言的热爱。期间看过大量的教学视频,查找了大量的第三方库的使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号