
数据竞赛实战(5)——方圆之外
前言
1,背景介绍
这里给出六千张图像做为训练集。每个图像中只要一个图形,要么是圆形,要是是正方形。你的任务是根据这六千张图片训练出一个二元分类模型,并用它在测试集判断每个图像中的形状是圆还是方;测试集中有些图像既不是圆也不是方,也请将其甄别出来。
2,任务类型
二元分类,异常检测,图像识别
3,数据文件说明
数据文件分为三个:
train.csv 训练集 文件大小为34.7MB
test.csv 预测集 文件大小为30.0MB
sample_submit.csv 提交示例 文件大小为40KB
4,数据变量说明

训练集中共有6000个灰度图像,预测集中有5191个灰度图像。每个图像中都会含有大量的噪点。图像的分辨率为40*40,也就是40*40的矩阵,每个矩阵以行向量的形式被存放在train.csv和test.csv中。train.csv和test.csv中每行数据代表一个图像,也就是说每行都有1600个特征。
训练集中的图像是圆形或者方形,测试集中的图像除了圆形和方形,还有非圆非方的异形。

任务是提交预测集中每个图像的标签(而非概率),以0表示圆,1表示方,2表示异形。格式应该与sample_submit.csv 一致。
train.csv 和 test.csv 均为逗号分隔形式的文件。在python中可以通过如下形式读取:
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
5,评估方法
提交的结果为每行的预测标签,也就是0,1,2 。评价方法为准确率。
您提交的结果为每行样本(每个样本)的预测标签,0表示圆形,1表示方形,2表示异形。
6,解题思路
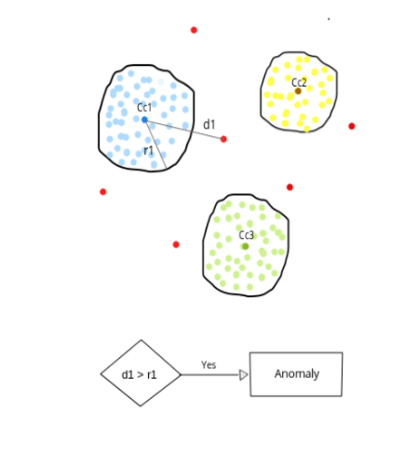
6.1 KNN做异常检测思路:
如何用K Means做非监督的异常检测(outlier anomaly detection)?
类似于one-class SVM,先用干净的数据(没有异常点)得到一个K Means。然后把测试集(包含异常点)根据之前KMeans的结果进行聚类,如果一个点距离它最近的中心超过之前训练集里的最大距离的话,就判断它为异常点。
参考文献: https://www.cnblogs.com/rongyux/p/5967470.html
http://www.bubuko.com/infodetail-1156495.html
https://www.docin.com/p-1298017248.html
这种方法简单,但是效果可能不是很好,这里我试验过了,就不贴代码了,代码在GitHub上,想看的可以去看。
6.2 相当于检测 out of distribution 的数据
可以参考uncertainty measure的方法,去年nips专门有专题解决uncertainty measure的问题。
可以参考:https://arxiv.org/abs/1610.02136
https://nips.cc/Conferences/2019/Schedule?showParentSession=15553
6.3 两分类来做
大概的思路这里说一下。
我打算结合之前的二分类,做一个二元分类,当阈值低于某个点的时候,我们设置其为第三类。下面我会尝试,看看效果如何。
6.4 三分类来做
我在知乎提问过,总的来说,各路大神的建议都是三分类,我就尝试了三分类来做。
知乎链接:https://www.zhihu.com/question/366130808
大概建议最多的就是三分类了。所以我打算尝试一下。
7,两分类来做
为什么想到这样做呢?我们慢慢来。
首先之前的二分类训练集只有两类图像,要么是圆形,要么是方形,我通过数据查看的图像如下:
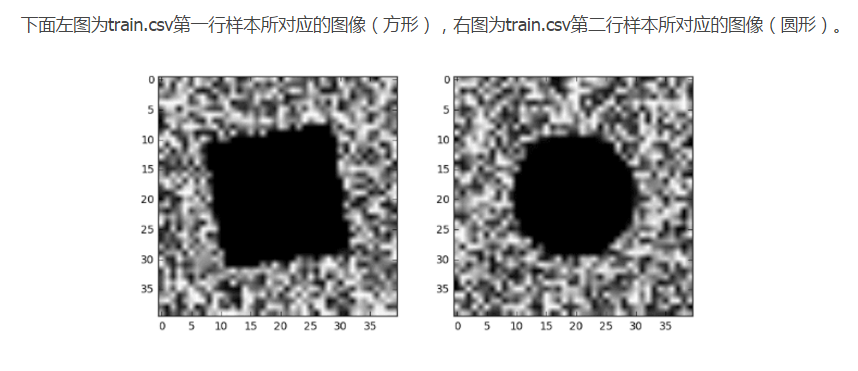
如何通过Python进行矩阵与图像之间的转换,我之前的博客里面有,这里不再赘述。
而我们这次训练集中也是只有两类图像,要么是圆形,要么是方形,我们查看数据如下:

从肉眼来看,特征还是很明显的。我们利用上面博客中的卷积神经网络进行二元分类。
首先,我们跑一下第一个数据的二元分类,数据我们叫 datain,当然第二次数据我们称为 dataout。第一次的数据毫无疑问是没有任何问题的,但是这里就再跑一边。
代码如下:
# _*_coding:utf-8_*_
from keras.callbacks import TensorBoard
from keras.layers import Dense, Dropout, MaxPooling2D, Flatten, Convolution2D
from keras.models import Sequential
from keras import backend as K
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from scipy.ndimage import median_filter
import matplotlib.pyplot as plt
def load_train_test_data(train, test):
np.random.shuffle(train)
labels = train[:, -1]
test = np.array(test)
data, data_test = data_modify_suitable_train(train, True), data_modify_suitable_train(test, False)
train_x, test_x, train_y, test_y = train_test_split(data, labels, test_size=0.33) # test_size=0.7
return train_x, train_y, test_x, test_y, data_test
def data_modify_suitable_train(data_set=None, type=True):
if data_set is not None:
data = []
if type is True:
np.random.shuffle(data_set)
# data = data_set[:, 0: data_set.shape[1] - 1]
data = data_set[:, 0: -1]
print(data.shape)
else:
data = data_set
data = np.array([np.reshape(i, (40, 40)) for i in data])
# data = np.array([median_filter(i, size=(3, 3)) for i in data])
# data = np.array([(i > 10) * 100 for i in data])
data = np.array([np.reshape(i, (i.shape[0], i.shape[1], 1)) for i in data])
return data
def f1(y_true, y_pred):
def recall(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
precision = precision(y_true, y_pred)
recall = recall(y_true, y_pred)
return 2 * ((precision * recall) / (precision + recall))
def bulit_model(train, test):
model = Sequential()
model.add(Convolution2D(filters=8,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Flatten())
model.add(Dense(units=128,
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=1,
activation='sigmoid'))
# 完成模型的搭建后,使用.compile方法来编译模型
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', f1])
model.summary()
return model
def train_models(train, test, batch_size=64, epochs=20, model=None):
train_x, train_y, test_x, test_y, t = load_train_test_data(train, test)
# print(train_x.shape, train_y.shape, test_x.shape, test_y.shape, t.shape)
if model is None:
model = bulit_model(train, test)
history = model.fit(train_x, train_y,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
print("刻画损失函数在训练与验证集的变化")
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='valid')
plt.legend()
plt.show()
# ##### 注意这个t
pred_prob = model.predict(t, batch_size=batch_size, verbose=1)
pred = np.array(pred_prob > 0.5).astype(int)
score = model.evaluate(test_x, test_y, batch_size=batch_size)
print('score is %s' % score)
print("刻画预测结果与测试结果")
return pred
if __name__ == '__main__':
train = pd.read_csv('datain/train.csv')
test = pd.read_csv('datain/test.csv')
# train = train.iloc[:,1:]
# test = test.iloc[:,1:]
# print(type(train))
train = np.array(train.drop('id', axis=1))
test = np.array(test.drop('id', axis=1))
# print(type(train))
pred = train_models(train, test)
# submit = pd.read_csv('dataout/sample_submit.csv')
# submit['y'] = pred
# submit.to_csv('my_CNN_prediction.csv', index=False)
我们训练到最后一轮,发现loss越来越小,acc已经等于1,f1 score也等于1。
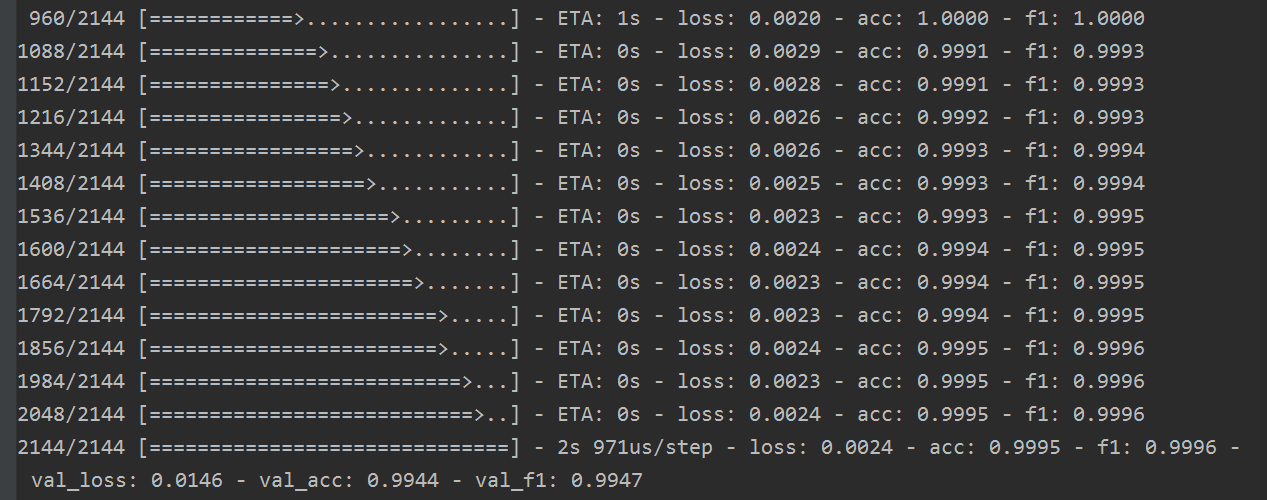
下图为损失函数在训练集合验证集中的变化:
效果不错。
下面我们直接更改数据集,看第二个只有方圆的数据集的效果如何。
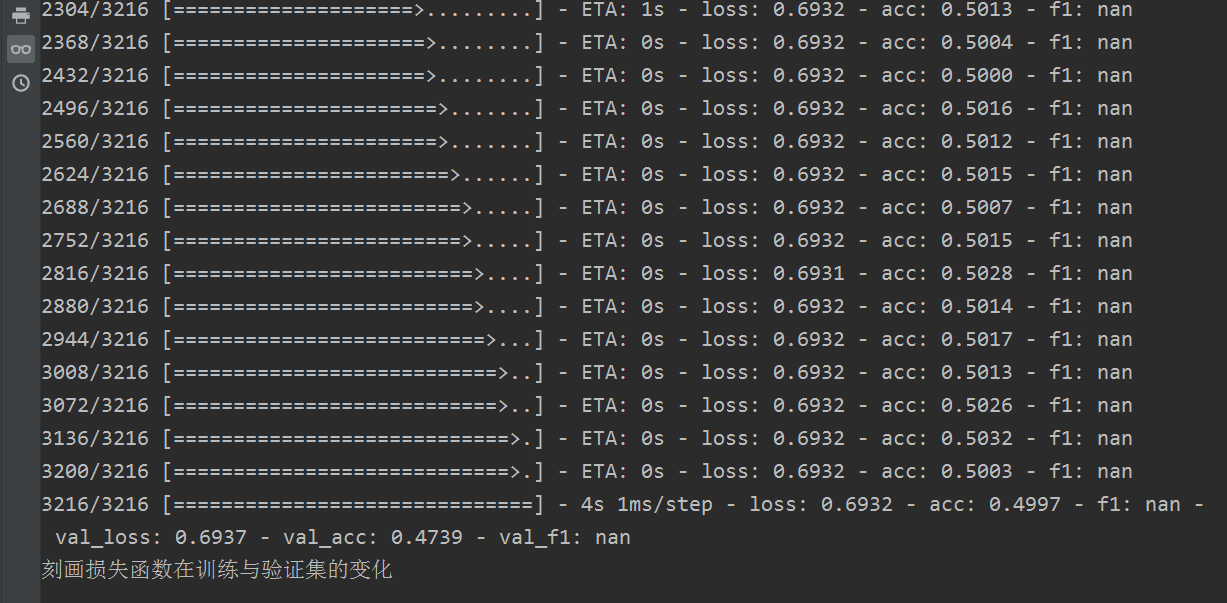
下图为刻画损失函数在训练与验证集的变化
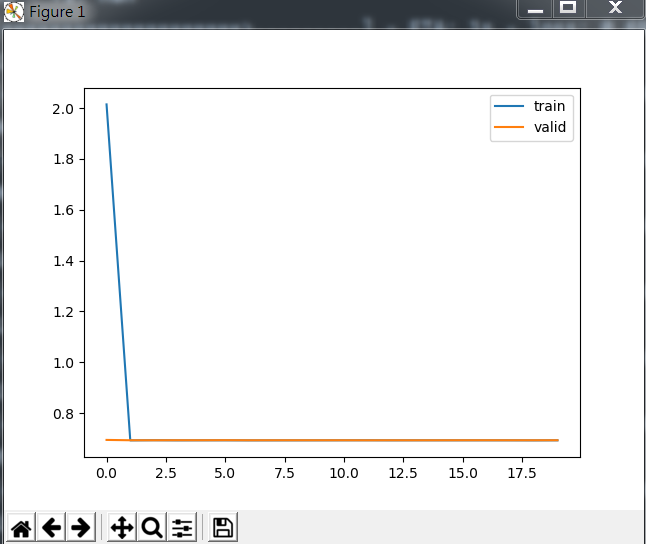
我们会发现效果极其的差,也就是很不好,loss迟迟降不下来,acc也上不去。所以我们需要对数据进行预处理。
7.1 对数据进行预处理
从上面两个训练的结果来看,第一个效果很好,第二个效果不好,这是为什么呢?虽然我们人眼很容易的区分了出来,但是机器却区分不开,所以当数据直接训练出问题的时候,我们则需要对数据进行预处理了。包括降噪等。
下面我们对图像进行预处理的过程如下:
- 1,利用中值滤波(median filter)进行降噪
- 2,利用阈值分割法(threshold segmentation)生成掩膜(binary mask)
- 3,利用形态闭合(morphology closing)来填充图中的小洞
下面来测试一下:
from skimage.restoration import (denoise_tv_chambolle, denoise_bilateral,
denoise_wavelet, estimate_sigma)
from scipy import ndimage, misc
import statistics
import scipy
def my_preprocessing(I,show_fig=False):
I_median=ndimage.median_filter(I, size=5)
mask=(I_median<statistics.mode(I_median.flatten()));
I_out=scipy.ndimage.morphology.binary_closing(mask,iterations=2)
if(np.mean(I_out[15:25,15:25].flatten())<0.5):
I_out=1-I_out
if show_fig:
fig= plt.figure(figsize=(8, 4))
plt.gray()
plt.subplot(2,4,1)
plt.imshow(I)
plt.axis('off')
plt.title('Image')
plt.subplot(2,4,2)
plt.imshow(I_median)
plt.axis('off')
plt.title('Median filter')
plt.subplot(2,4,3)
plt.imshow(mask)
plt.axis('off')
plt.title('Mask')
plt.subplot(2,4,4)
plt.imshow(I_out)
plt.axis('off')
plt.title('Closed mask')
fig.tight_layout()
plt.show()
return I_out
I_out=my_preprocessing(x_test[5],True);
结果如下:

当我们对图像进行处理,我们发现想很明显,就只是做了中值滤波效果都出来了。这下加入数据预处理,我们来看看所有的效果,包括上一篇是方还是圆的文章中,我们做了中值滤波加二值化,效果很好,这一篇我们加了掩膜,这里做一个测试,我想看看中值滤波加二值化在此篇文章中的效果如何,并且看看掩膜对于上一篇文字中的数据的效果如何呢?
代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.ndimage import median_filter
import statistics
from scipy import ndimage
def loadData(trainFile, show_fig=False):
train = pd.read_csv(trainFile)
data = np.array(train.iloc[0, 1:-1])
origin_data = np.reshape(data, (40, 40))
# 做了中值滤波
median_filter_data = np.array(median_filter(origin_data, size=(3, 3)))
# 二值化
# binary_data = np.array((origin_data > 127) * 256)
binary_data = np.array((origin_data > 1) * 256)
# 利用阈值分割法生成掩膜
mask = (median_filter_data < statistics.mode(median_filter_data.flatten()))
# 利用形态闭合来填充图中的小洞
binary_closing_data = ndimage.morphology.binary_closing(mask, iterations=2)
if(np.mean(binary_closing_data[15:25, 15:25].flatten()) < 0.5):
binary_closing_data = 1-binary_closing_data
if show_fig:
# fig = plt.figure(figsize=(8, 4))
plt.subplot(1, 5, 1)
plt.gray()
plt.imshow(origin_data)
plt.axis('off')
plt.title('origin photo')
plt.subplot(1, 5, 2)
plt.imshow(median_filter_data)
plt.axis('off')
plt.title('median filter photo')
plt.subplot(1, 5, 3)
plt.imshow(binary_data)
plt.axis('off')
plt.title('binary photo')
plt.subplot(1, 5, 4)
plt.imshow(mask)
plt.axis('off')
plt.title('mask photo')
plt.subplot(1, 5, 5)
plt.imshow(binary_closing_data)
plt.axis('off')
plt.title('binary_closing photo')
if __name__ == '__main__':
trainFile = 'dataout/train.csv'
loadData(trainFile, True)
对于上一节的数据效果如下:

对于上一节的数据,做二值处理,效果就很明显了,再加上掩膜,很明显画蛇添足了。
我们看这一节的效果:

对于此节的数据,做掩膜效果明显,但是单纯的二值处理,效果根本不好。
所以这里得出一个结论,就是对于不同的数据集要做不同的处理,具体如何处理呢?这是个玄学问题。我会继续寻找其规律,找到了必定写出来。
7.2 模型训练
好了,下面就测试测试,测试数据的时候,我们就不需要使用掩膜对第一个数据进行处理了,从处理图片就可以看出效果一点也不好,而使用二值对第一个数据处理,在之前的博文里面全部分析过,这里不再赘述了。
所以这里测试的是使用掩膜对这篇博文的数据做二值分类,看效果如何。
代码如下:
# _*_coding:utf-8_*_
from keras.callbacks import TensorBoard
from keras.layers import Dense, Dropout, MaxPooling2D, Flatten, Convolution2D
from keras.models import Sequential
from keras import backend as K
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from scipy.ndimage import median_filter
import matplotlib.pyplot as plt
import scipy
from scipy import ndimage, misc
import statistics
def load_train_test_data(train, test):
np.random.shuffle(train)
# train = train[:, :-1]
labels = train[:, -1]
test = np.array(test)
# print(train.shape, test.shape, labels.shape) # (6000, 1600) (5191, 1600) (6000,)
data, data_test = data_modify_suitable_train(train, True), data_modify_suitable_train(test, False)
# print(data.shape, data_test.shape)
# train = train.reshape([train.shape[0], 40, 40])
# test = test.reshape([test.shape[0], 40, 40])
# data, data_test = batch_preprocessing(train), batch_preprocessing(test)
# # print(data.shape, data_test.shape) # (6000, 40, 40) (5191, 40, 40)
# 注意这里需要添加一个维度
data, data_test = np.expand_dims(data, 3), np.expand_dims(data_test, 3)
# print(data.shape, data_test.shape)
train_x, test_x, train_y, test_y = train_test_split(data, labels, test_size=0.33) # test_size=0.7
return train_x, train_y, test_x, test_y, data_test
def data_test(train, test):
np.random.shuffle(train)
train = train[:, :-1]
labels = train[:, -1]
test = np.array(test)
# print(train.shape, test.shape, labels.shape) # (6000, 1600) (5191, 1600) (6000,)
train = train.reshape([train.shape[0], 40, 40])
test = test.reshape([test.shape[0], 40, 40])
data = my_preprocessing(train[1])
all_data = batch_preprocessing(data_set=train)
# data = data_modify_suitable_train(train, True)
print(data.shape, type(data)) # (40, 40) <class 'numpy.ndarray'>
print(all_data.shape, type(all_data))
plt.gray()
plt.imshow(all_data[1])
plt.axis('off')
plt.title('origin photo')
def my_preprocessing(I, show_fig=False):
I_median = ndimage.median_filter(I, size=5)
mask = (I_median < statistics.mode(I_median.flatten()))
I_out = scipy.ndimage.morphology.binary_closing(mask, iterations=2)
if (np.mean(I_out[15:25, 15:25].flatten()) < 0.5):
I_out = 1 - I_out
if show_fig:
fig = plt.figure(figsize=(8, 4))
plt.gray()
plt.subplot(2, 4, 1)
plt.imshow(I)
plt.axis('off')
plt.title('Image')
plt.subplot(2, 4, 2)
plt.imshow(I_median)
plt.axis('off')
plt.title('Median filter')
plt.subplot(2, 4, 3)
plt.imshow(mask)
plt.axis('off')
plt.title('Mask')
plt.subplot(2, 4, 4)
plt.imshow(I_out)
plt.axis('off')
plt.title('Closed mask')
fig.tight_layout()
plt.show()
return I_out
def batch_preprocessing(data_set):
zero_data = np.zeros_like(data_set)
data_n = data_set.shape[0]
for i in range(data_n):
zero_data[i] = my_preprocessing(data_set[i])
return zero_data
def data_modify_suitable_train(data_set=None, type=True):
if data_set is not None:
data = []
if type is True:
np.random.shuffle(data_set)
# data = data_set[:, 0: data_set.shape[1] - 1]
data = data_set[:, 0: -1]
print(data.shape)
else:
data = data_set
data = np.array([np.reshape(i, (40, 40)) for i in data])
print('data', data.shape)
# median_data = np.array([median_filter(i, size=(5, 5)) for i in data])
# print('median', median_data.shape)
# mask = (median_data < statistics.mode(median_data.flatten()))
# print('mask', mask.shape)
# res_data = ndimage.morphology.binary_closing(mask, iterations=2)
# if (np.mean(res_data[15:25, 15:25].flatten()) < 0.5):
# res_data = 1 - res_data
# print('res_data', res_data.shape)
zero_data = np.zeros_like(data)
data_n = data.shape[0]
for i in range(data_n):
zero_data[i] = my_preprocessing(data[i])
return zero_data
# data = np.array([(i > 10) * 100 for i in data])
# data = np.array([np.reshape(i, (i.shape[0], i.shape[1], 1)) for i in res_data])
# data = np.array([np.reshape(i, (i.shape[0], i.shape[1])) for i in res_data])
# return data
def f1(y_true, y_pred):
def recall(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
precision = precision(y_true, y_pred)
recall = recall(y_true, y_pred)
return 2 * ((precision * recall) / (precision + recall))
def built_model():
model = Sequential()
model.add(Convolution2D(filters=8,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Convolution2D(filters=16,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Flatten())
model.add(Dense(units=128,
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=1,
activation='sigmoid'))
# 完成模型的搭建后,使用.compile方法来编译模型
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', f1])
model.summary()
return model
def built_model_plus():
n_filter = 32
# 序贯模型是多个网络层的线性堆叠,也就是“一条道走到黑”
model = Sequential()
# 通过 .add() 方法一个个的将 layer加入模型中
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=n_filter,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
# final layer using softmax
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', f1])
model.summary()
return model
def train_models(train, test, batch_size=64, epochs=20, model=None):
train_x, train_y, test_x, test_y, t = load_train_test_data(train, test)
# print(train_x.shape, train_y.shape, test_x.shape, test_y.shape, t.shape)
if model is None:
model = built_model_plus()
history = model.fit(train_x, train_y,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
print("刻画损失函数在训练与验证集的变化")
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='valid')
plt.legend()
plt.show()
# ##### 注意这个t
pred_prob = model.predict(t, batch_size=batch_size, verbose=1)
pred = np.array(pred_prob > 0.5).astype(int)
score = model.evaluate(test_x, test_y, batch_size=batch_size)
print('score is %s' % score)
print("刻画预测结果与测试结果")
return pred
if __name__ == '__main__':
trainFile = 'dataout/train.csv'
testFile = 'dataout/test.csv'
submitfile = 'dataout/sample_submit.csv'
train = pd.read_csv(trainFile)
test = pd.read_csv(testFile)
train = np.array(train.drop('id', axis=1))
test = np.array(test.drop('id', axis=1))
# print(train.shape, test.shape) # (6000, 1601) (5191, 1600)
# load_train_test_data(train, test)
# data test
# data_test(train, test)
# load_train_test_data(train, test)
# print('over')
pred = train_models(train, test)
# submit = pd.read_csv('dataout/sample_submit.csv')
# submit['y'] = pred
# submit.to_csv('my_CNN_prediction.csv', index=False)
训练结果如下(这个是build_model_plus):

下图为损失函数在训练与验证集的变化:
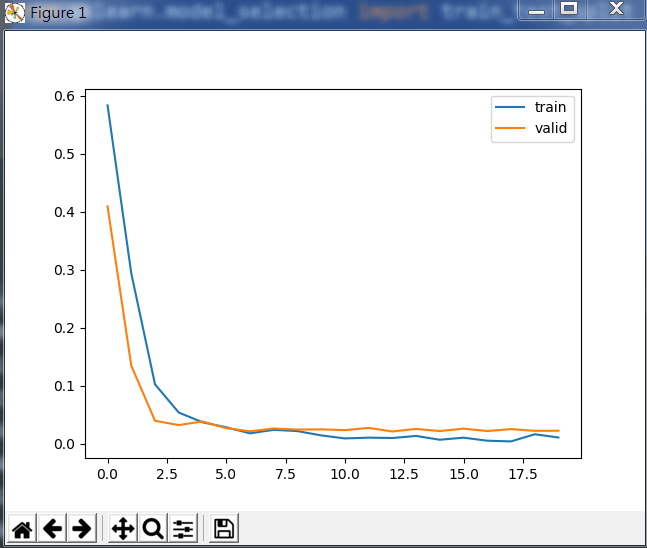
下面是 (build_model)的效果:
下图为损失函数在训练与验证集的变化:

效果不如上一个好。所以我们采用plus的模型。
下面我们做两分类模型,阈值设置为0.3和0.7,代码如下:
# ##### 注意这个t
pred_prob = model.predict(t, batch_size=batch_size, verbose=1)
# pred = np.array(pred_prob > 0.5).astype(int)
# score = model.evaluate(test_x, test_y, batch_size=batch_size)
# print('score is %s' % score)
# print("刻画预测结果与测试结果")
for i in range(pred_prob.shape[0]):
if pred_prob[i][0] > 0.7:
pred_prob[i][0] = 1
elif pred_prob[i][0] < 0.3:
pred_prob[i][0] = 0
else:
pred_prob[i][0] = 2
return pred_prob.astype(int)
结果如下:
![]()
讲道理,效果让我意想不到啊,还是很不错的。
8,三分类来做
测试了两分类,下面就实验一下triplet 。
8.1 知识储备
这里学习一下 sklearn.preprocessing.MultiLabelBinarizer 函数。
参考地址:https://blog.csdn.net/kancy110/article/details/75094179
多标签二值化:klearn.preprocessing.MultiLabelBinarizer(classes=None, sparse_output=False) classes_属性:若设置classes参数时,其值等于classes参数值,否则从训练集统计标签值
测试1,当classes采用默认值,classes_属性值从训练集中统计标签值。
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
mlb.fit_transform([(1,2), (3, 4), (5, 6), (7, )])
Out[4]:
array([[1, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 1, 0],
[0, 0, 0, 0, 0, 0, 1]])
mlb.classes_
Out[5]: array([1, 2, 3, 4, 5, 6, 7])
测试2,设置classes参数,classes_属性值等于classes参数值
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer(classes=[2,3,4,5,6])
mlb.fit_transform([(1,2), (3, 4), (5, 6), (7, )])
D:\anaconda3\envs\python36\lib\site-packages\sklearn\preprocessing\label.py:951: UserWarning: unknown class(es) [1, 7] will be ignored
.format(sorted(unknown, key=str)))
Out[8]:
array([[1, 0, 0, 0, 0],
[0, 1, 1, 0, 0],
[0, 0, 0, 1, 1],
[0, 0, 0, 0, 0]])
mlb.classes_
Out[9]: array([2, 3, 4, 5, 6])
8.2 数据处理
数据处理我们这里和上面一样,首先是中值滤波降噪,利用阈值分割法生成掩膜,利用形态闭合来填充图中的小洞。上面都有过程,这里不再赘述。
我们说的要人工从测试集中挑选了训练集中并未出现过的标签的几个样本,加入训练集中,这里采用五个。
首先需要找到五个异常的样本,后面我们可以增加到10个。
测试集的下标是从0开始的,我们就从第一个开始,找10个。


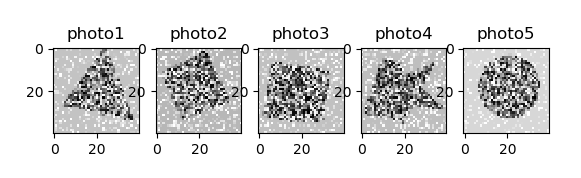

我这都是按照顺序找的,分别是0, 1, 4, 10, 13。
还有作者找的五个异形分别是 4949, 4956, 4973, 4988:

这里附上,我的检查代码
import pandas as pd
import matplotlib.pyplot as plt
def seek_abnormal(testFile, show_fig=True):
data = pd.read_csv(testFile)
data1 = np.array(data.iloc[0:, 1:])
# print(data1.shape) # (5191, 1600)
# data2 = np.array(data)
# data2 = data2[0:, 1:]
photo1 = np.reshape(data1[949], (40, 40))
photo2 = np.reshape(data1[956], (40, 40))
photo3 = np.reshape(data1[973], (40, 40))
photo4 = np.reshape(data1[974], (40, 40))
photo5 = np.reshape(data1[988], (40, 40))
if show_fig:
plt.subplot(1, 5, 1)
plt.gray()
plt.imshow(photo1)
plt.title('photo1')
plt.subplot(1, 5, 2)
plt.gray()
plt.imshow(photo2)
plt.title('photo2')
plt.subplot(1, 5, 3)
plt.gray()
plt.imshow(photo3)
plt.title('photo3')
plt.subplot(1, 5, 4)
plt.gray()
plt.imshow(photo4)
plt.title('photo4')
plt.subplot(1, 5, 5)
plt.gray()
plt.imshow(photo5)
plt.title('photo5')
if __name__ == '__main__':
testFile = 'dataout/test.csv'
# 查找异形图片
seek_abnormal(testFile)
下面需要将异形数据加入到训练集中,代码如下:
# 人工从测试集中挑选训练集中并未出现过的标签样本,加入训练集中
def add_other_sample_func(train_prc, labelMat, test_prc):
# 五个异形在原数据中对应的下标
# 手动查看测试集中的图像,并且增加了五个异性,放入训练集中
num_anno = 5
anno_inx = np.array([4949, 4956, 4973, 4974, 4988])
# anno_idx = np.array([4000, 4001, 4004, 4010, 4013])
anno_inx = anno_inx[::-1]
anno_inx_add = anno_inx[:num_anno] # array([4988, 4974, 4973, 4956, 4949])
x_train_prc_anno = train_prc
y_train_anno = labelMat.reshape([-1, 1])
x_add = test_prc[anno_inx_add]
y_add = np.ones([num_anno, 1])*2
'''
array([[2.],
[2.],
[2.],
[2.],
[2.]])
'''
# 对异形进行过采样
# for i in range(4000/num_anno):
for i in range(800):
x_train_prc_anno = np.append(x_train_prc_anno, x_add, axis=0)
y_train_anno = np.append(y_train_anno, y_add, axis=0)
x_train_prc_anno, y_train_anno = shuffle(x_train_prc_anno, y_train_anno, random_state=0)
mlb1 = MultiLabelBinarizer()
y_train_mlb = mlb1.fit_transform(y_train_anno)
return x_train_prc_anno, y_train_mlb, test_prc
8.3 数据增广
在数据样本较小时,我们也会进行数据增广。那我们采用的时Keras中的图片生成器ImageDataGenerator。

用以生成一个batch的图像数据,支持实时数据提升。训练时该函数会无限生成数据,直到达到规定的epoch次数为止。
参数:


方法如下:

使用 .flow() 的例子
而本文中生成数据的代码如下(类似于上面):
datagen = ImageDataGenerator(
rotation_range=180, # 整数,数据提升时图片随机转动的角度
width_shift_range=0.1, # 浮点数,图片宽度的某个比例,数据提升时图片水平便宜的幅度
height_shift_range=0.1, # 浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度
horizontal_flip=True # 布尔值,进行随机水平翻转
)
# 训练模型的同时进行数据增广
# flow(self, X, y batch_size=21, shuffle=True, seed=None,save_to_dir=None, save_prefix='' save_format='jpeg')
# 接收 numpy数组和标签为参数,生成经过数据提升或标准化后的batch数据,并在一个无线循环中不断的返回 batch数据
history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=len(x_train) / batch_size, epochs=epochs,
class_weight=class_weight,
validation_data=datagen.flow(x_train, y_train,
batch_size=batch_size),
validation_steps=1)
8.4 模型训练
卷积神经网络(CNN)一般包括卷积层,池化层,全连接层,有时候为了防止过拟合,我们也会加入dropout层。
此代码为标杆模型的代码:
from keras.callbacks import TensorBoard
from keras.layers import Dense, Dropout, MaxPooling2D, Flatten, Convolution2D
from keras.models import Sequential
from keras.optimizers import Adam
from keras import backend as K
from keras.preprocessing.image import ImageDataGenerator
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import statistics
from scipy import ndimage
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.utils import shuffle
SEED = 0
tf.random.set_random_seed(SEED)
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1,
inter_op_parallelism_threads=1)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
def load_DateSet(TrainFile, TestFile):
traindata = pd.read_csv(TrainFile)
testdata = pd.read_csv(TestFile)
dataMat_origin, testMat_origin = np.array(traindata.drop('id', axis=1)), np.array(testdata.drop('id', axis=1))
dataMat, labelMat, testMat = dataMat_origin[:, 0:-1], dataMat_origin[:, -1], testMat_origin
# print(dataMat.shape, labelMat.shape, testMat.shape)
# 将矩阵转化为(40, 40) 的格式
dataMat = np.array([np.reshape(i, (40, 40)) for i in dataMat])
testMat = np.array([np.reshape(i, (40, 40)) for i in testMat])
# return dataMat_origin, testMat_origin, dataMat, labelMat, testMat
return dataMat, labelMat, testMat
def my_preprocessing(I, show_fig=False):
# data = np.array([ndimage.median_filter(i, size=(3, 3)) for i in data])
# data = np.array([i > 10]*100 for i in data)
I_median = ndimage.median_filter(I, size=5)
mask = (I_median < statistics.mode(I_median.flatten()))
I_out = ndimage.morphology.binary_closing(mask, iterations=2)
if (np.mean(I_out[15:25, 15:25].flatten()) < 0.5):
I_out = 1 - I_out
if show_fig:
fig = plt.figure(figsize=(8, 4))
plt.gray()
plt.subplot(1, 4, 1)
plt.imshow(I) # 原图
plt.axis('off')
plt.title('Image')
plt.subplot(1, 4, 2)
plt.imshow(I_median) # 中值滤波处理
plt.axis('off')
plt.title("Median filter")
plt.subplot(1, 4, 3)
plt.imshow(mask) # 添加掩膜
plt.axis('off')
plt.title('Mask')
plt.subplot(1, 4, 4)
plt.imshow(I_out) # 形态闭合处理
plt.axis('off')
plt.title('Closed mask')
fig.tight_layout()
plt.show()
return I_out
# return I_median
def batch_preprocessing(dataMat, labelMat, testMat):
train_prc = np.zeros_like(dataMat)
test_prc = np.zeros_like(testMat)
for i in range(dataMat.shape[0]):
train_prc[i] = my_preprocessing(dataMat[i])
for i in range(testMat.shape[0]):
test_prc[i] = my_preprocessing(testMat[i])
# print("over ...")
return train_prc, labelMat, test_prc
# 人工从测试集中挑选训练集中并未出现过的标签样本,加入训练集中
def add_other_sample_func(train_prc, labelMat, test_prc):
# 五个异形在原数据中对应的下标
# 手动查看测试集中的图像,并且增加了五个异性,放入训练集中
num_anno = 5
anno_inx = np.array([4949, 4956, 4973, 4974, 4988])
anno_inx = anno_inx[::-1]
anno_inx_add = anno_inx[:num_anno] # array([4988, 4974, 4973, 4956, 4949])
x_train_prc_anno = train_prc
y_train_anno = labelMat.reshape([-1, 1])
x_add = test_prc[anno_inx_add]
y_add = np.ones([num_anno, 1])*2
# 对异形进行过采样
# for i in range(4000/num_anno):
for i in range(800):
x_train_prc_anno = np.append(x_train_prc_anno, x_add, axis=0)
y_train_anno = np.append(y_train_anno, y_add, axis=0)
x_train_prc_anno, y_train_anno = shuffle(x_train_prc_anno, y_train_anno, random_state=0)
mlb1 = MultiLabelBinarizer()
y_train_mlb = mlb1.fit_transform(y_train_anno)
return x_train_prc_anno, y_train_mlb, test_prc
def built_model():
n_filter = 32
# 序贯模型是多个网络层的线性堆叠,也就是“一条道走到黑”
model = Sequential()
# 通过 .add() 方法一个个的将 layer加入模型中
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
input_shape=(40, 40, 1),
activation='relu'))
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=n_filter,
kernel_size=(5, 5),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(filters=n_filter,
kernel_size=(3, 3),
activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
# final layer using softmax
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0003),
metrics=['accuracy'])
model.summary()
return model
def train_model(x_train, y_train, x_test, batch_size=64, epochs=20, model=None,
class_weight={0: 1., 1: 1., 2: 10.}):
if np.ndim(x_train) < 4:
x_train = np.expand_dims(x_train, 3)
x_test = np.expand_dims(x_test, 3)
if model is None:
model = built_model()
datagen = ImageDataGenerator(
rotation_range=180, # 整数,数据提升时图片随机转动的角度
width_shift_range=0.1, # 浮点数,图片宽度的某个比例,数据提升时图片水平便宜的幅度
height_shift_range=0.1, # 浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度
horizontal_flip=True # 布尔值,进行随机水平翻转
)
# 训练模型的同时进行数据增广
# flow(self, X, y batch_size=21, shuffle=True, seed=None,save_to_dir=None, save_prefix='' save_format='jpeg')
# 接收 numpy数组和标签为参数,生成经过数据提升或标准化后的batch数据,并在一个无线循环中不断的返回 batch数据
history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=len(x_train) / batch_size, epochs=epochs,
class_weight=class_weight,
validation_data=datagen.flow(x_train, y_train,
batch_size=batch_size),
validation_steps=1)
print("Loss on training and testing")
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='valid')
plt.legend()
plt.show()
pred_prob_train = model.predict(x_train, batch_size=batch_size, verbose=1)
pred_train = np.array(pred_prob_train > 0.5).astype(int)
pred_prob_test = model.predict(x_test, batch_size=batch_size, verbose=1)
pred_test = np.array(pred_prob_test > 0.5).astype(int)
y_test_hat = pred_test[:, 1] + pred_test[:, 2] * 2
y_train_hat = pred_train[:, 1] + pred_train[:, 2] * 2
return y_train_hat, y_test_hat, history
if __name__ == '__main__':
trainFile = 'dataout/train.csv'
testFile = 'dataout/test.csv'
submitfile = 'dataout/sample_submit.csv'
epochs = 100
# 考虑到异性并不多,所以设置如下权重,来解决非平衡下的分类
class_weight = {0: 1., 1: 1., 2: 10.}
dataMat, labelMat, testMat = load_DateSet(trainFile, testFile)
# 数据预处理
# I_out = my_preprocessing(testMat[5], True)
train_prc, labelMat, test_prc = batch_preprocessing(dataMat, labelMat, testMat)
x_train_prc_anno, y_train_mlb, test_prc = add_other_sample_func(train_prc, labelMat, test_prc)
y_train_hat, y_test_hat, hisory = train_model(x_train_prc_anno, y_train_mlb, test_prc,
epochs=epochs, batch_size=64, class_weight=class_weight)
# 提交结果,查看精度
submit = pd.read_csv(submitfile)
submit['y'] = y_test_hat
submit.to_csv('my_cnn_prediction3.csv', index=False)
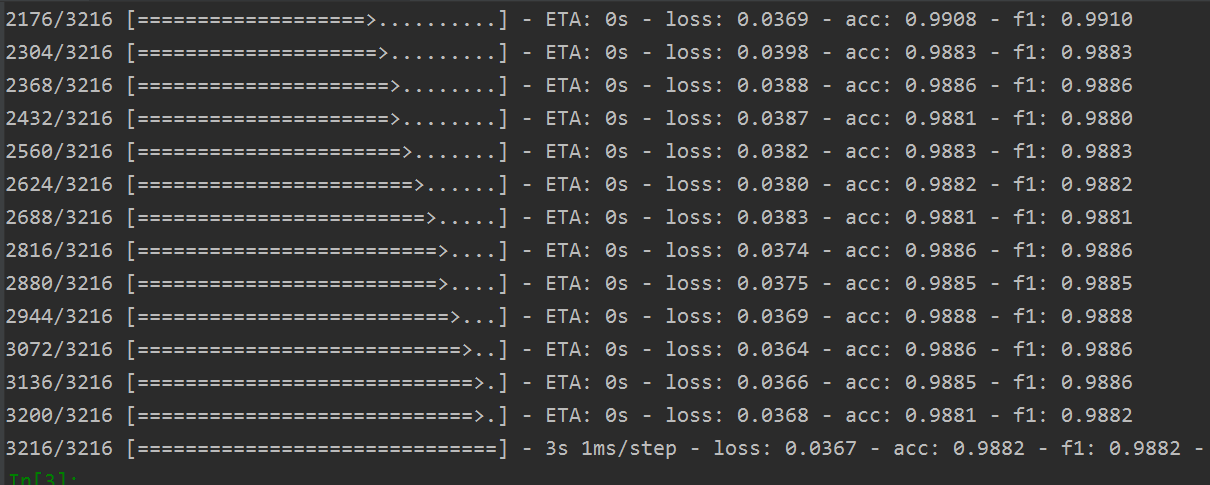
损失函数在训练和验证集的变化如下:
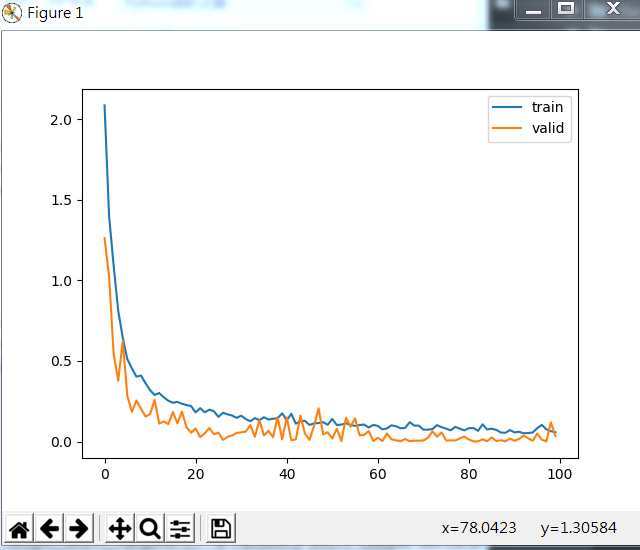
其训练结果如下: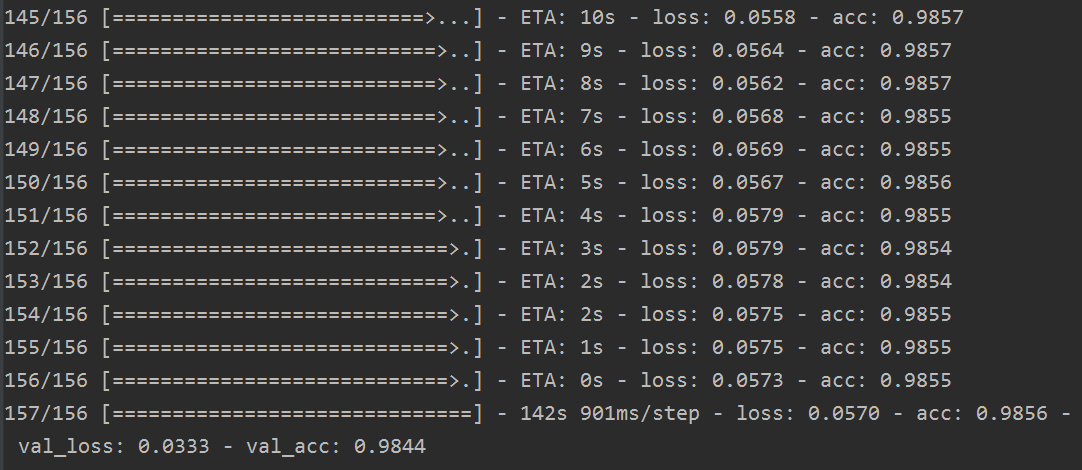
其代码的结果为:
![]()
再跑一边,提交的结果是:

看来模型训练这块是有点玄学问题哈。
我将标杆模型中的增强数据改为我增加的五个异形,损失函数在训练和验证集的变化如下:
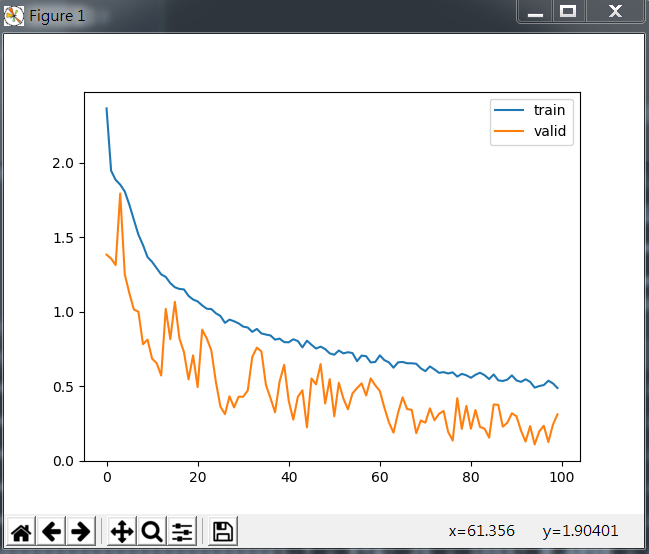
其训练结果如下:
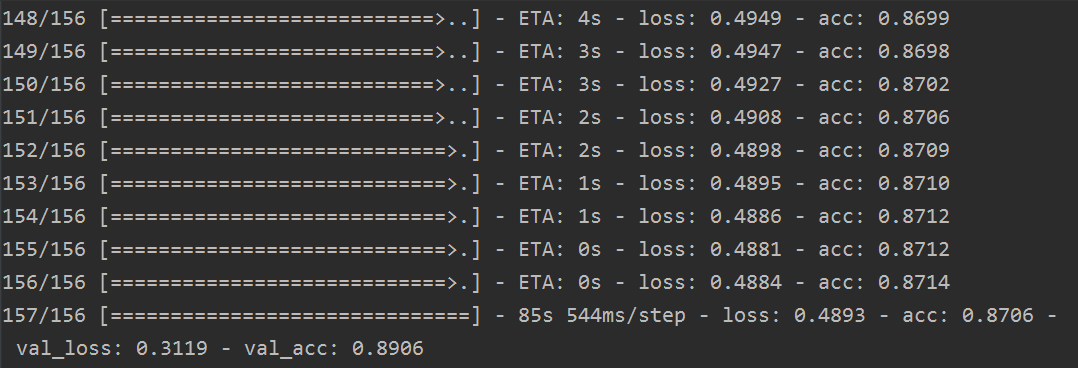
提交的结果如下:

从结果来看,效果不是很好,按理说,明明是异形数据的扩增,为什么效果反而不好呢?我仔细找了一下原因,发现 [4000, 4001, 4004, 4010, 4013] 的图片如下:

根本就不是异形,真的是我的失误。
下面我将 0,1, 4, 10, 13 的图片展示如下(这个才是我找出来的异形):

下面将这几个异形重写写入,进行代码训练,其损失函数在验证集合测试集的变化如下:
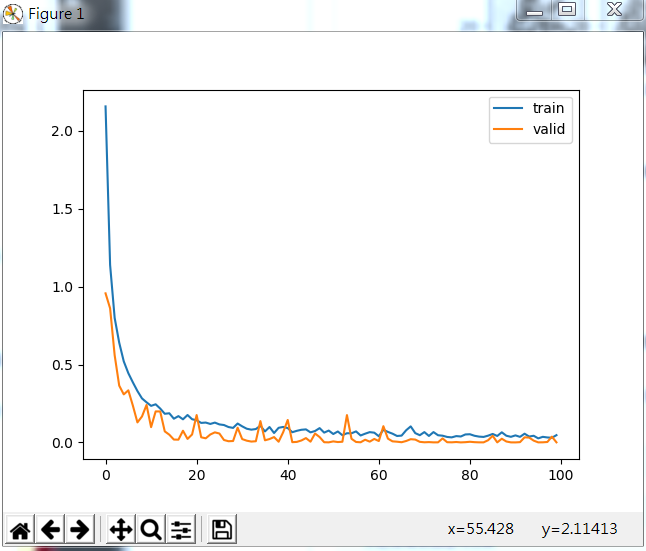
部分训练结果如下:
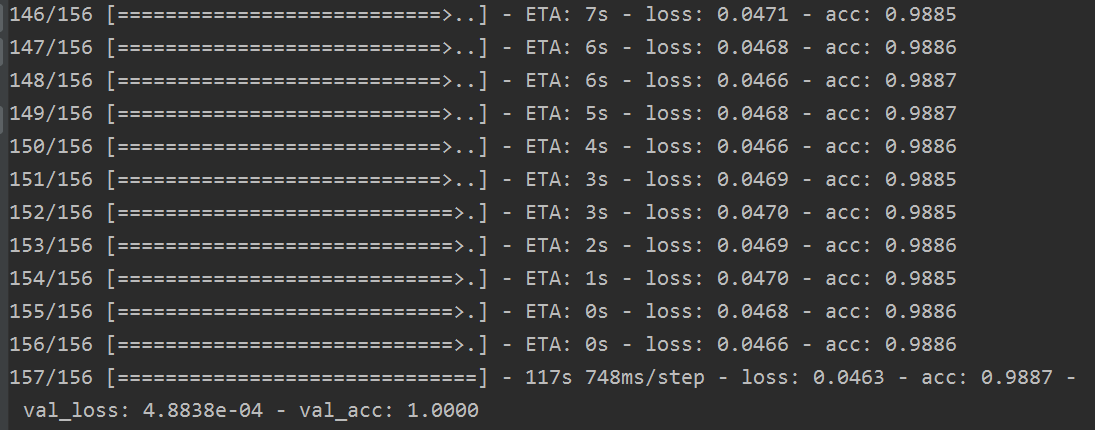
这时候提交的结果还没下来,但是单从loss和acc上,我感觉比标杆模型的结果好点。
结果如下:

果然,增强了,可以可以。
我将异形样本增强,增加到10个,也就是将原标杆的异形和我找的异形合并,增加异形样本量,再对数据进行扩增,看看效果。这里代码我在原代码基础上修改了,这里不再贴代码了。
直接看训练集和测试集的损失图:
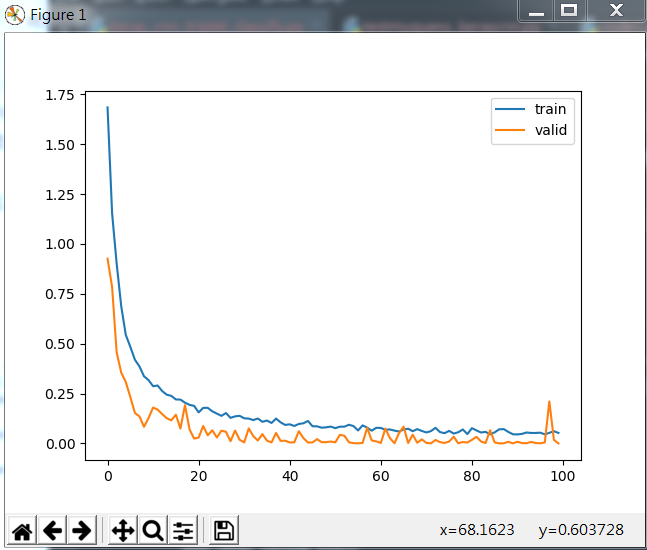
部分训练结果:
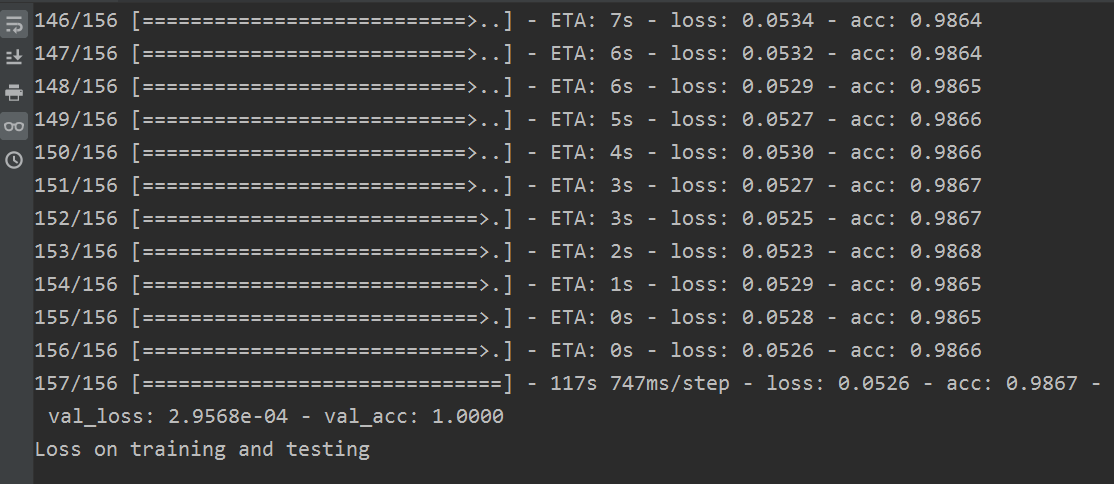
结果如下:

都第二名了,试试冲一下第一名。那么提高的的方面肯定有几个方面:
- 1就是增加数据预处理的方式,使得特征更加明显,但是这种我还没有想出来更好的
- 2就是给修改模型,增加卷积层,或者使用VGG,ResNet等网络,但是这种网络太大了,我也就不试了。
- 3,就是做三分类的时候,增加异常样本,我再试着加10个异常样本吧。
从上面继续,21开始: 23 27


2444

2524 2533 2554
4413 4533
2938
936
随机找了10个。分别是:
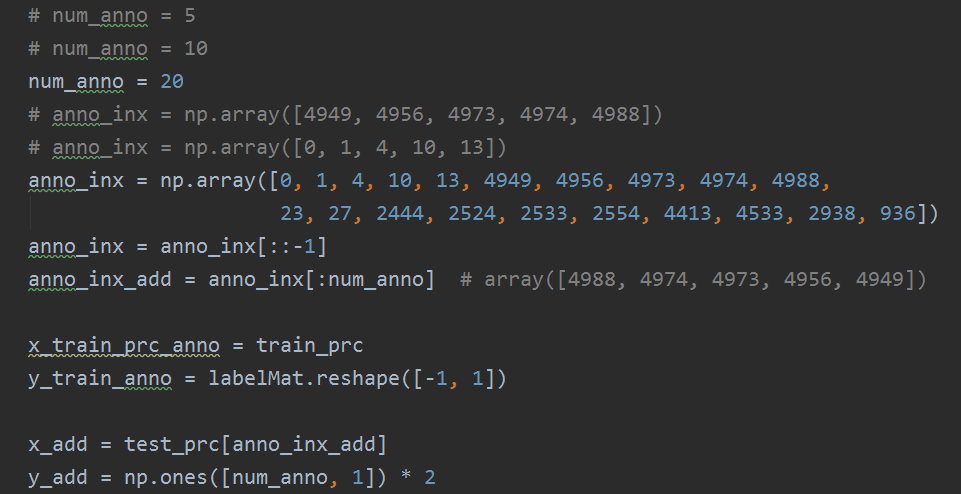

训练集和测试集的损失图如下:
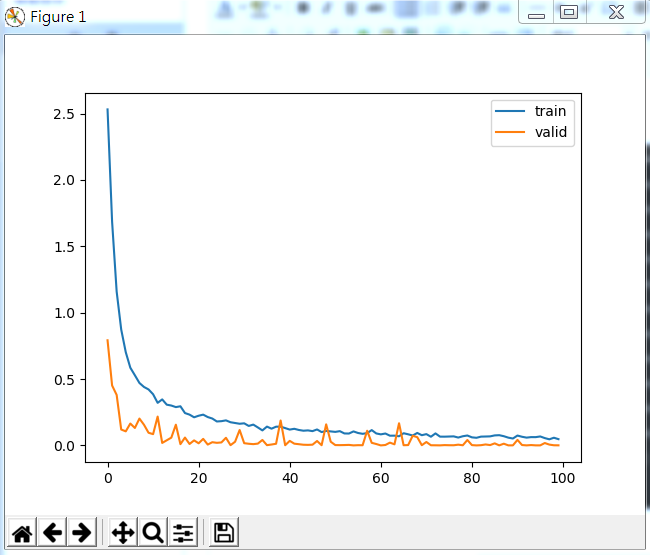
部分训练过程如下:
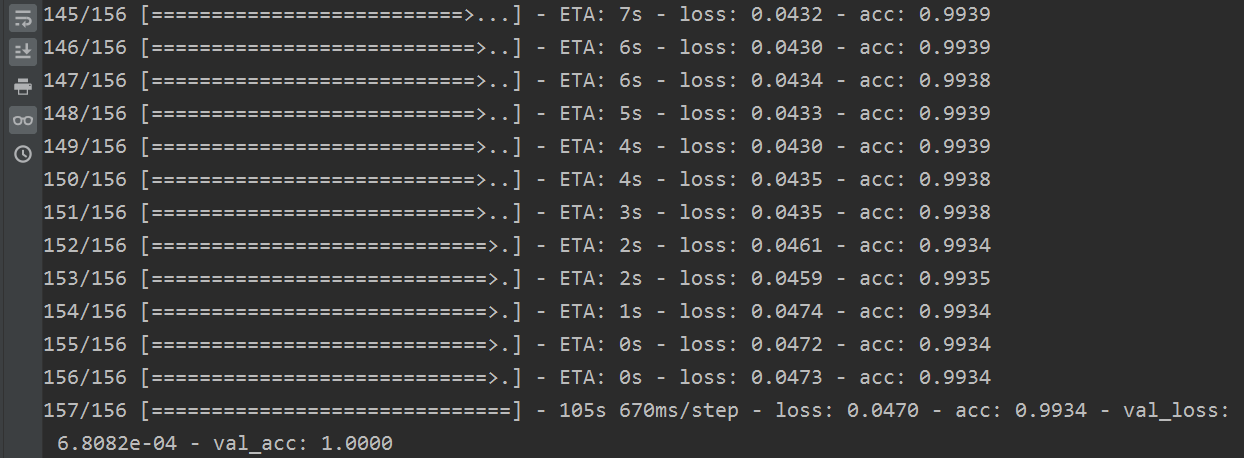
结果如下:

准确率确实有所提高,如果还想再提高,当然可以对模型进行修改,这里就不做了,掌握了方法就不再浪费时间了。
完整代码,请移步小编的GitHub
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/sofasofa-learn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号