

CNN结构:用于检测的CNN结构进化-分离式方法
前言:
原文链接:基于CNN的目标检测发展过程 文章有大量修改,如有不适,请移步原文.
参考文章:图像的全局特征--用于目标检测
目标的检测和定位中一个很困难的问题是,如何从数以万计的候选窗口中挑选包含目标物的物体。只有候选窗口足够多,才能保证模型的 Recall。传统机器学习方法应用,使用全局特征+级联分类器的思路仍然被持续使用。常用的级联方法有haar/LBP特征+Adaboost决策树分类器级联检测 和HOG特征 + SVM分类器级联检测。
DPM方法为08年提出的一种可进行级联(2010)的图像目标检测方法,RBG阐述,“Deformable Part Models are Convolutional Neural Networks”(http://arxiv.org/abs/1409.5403),可以视为CNN检测方法的前驱。
目标检测的几个阶段:分类 、分类+定位 、多目标检测、语义分割
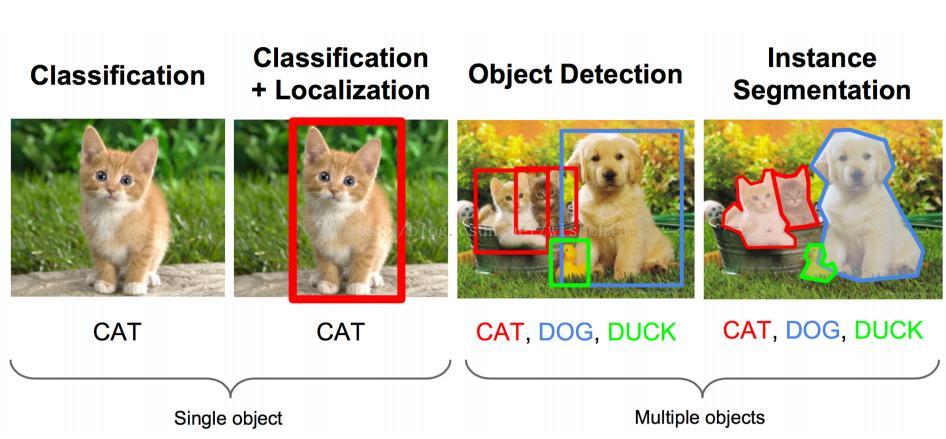
引言
图像的全局特征:HOG特征和DPM模型......
孔涛在知乎上这样写到。
目前,基于CNN的目标检测框架主要有两种:
一种是 one-stage ,例如 YOLO、SSD 等,这一类方法速度很快,但识别精度没有 two-stage 的高,其中一个很重要的原因是,利用一个分类器很难既把负样本抑制掉,又把目标分类好。
另外一种目标检测框架是 two-stage ,以 Faster RCNN 为代表,这一类方法识别准确度和定位精度都很高,但存在着计算效率低,资源占用大的问题。
预训练模型-用于分类的CNN
大多数模型并非一开始就设计网络结构,使用数据进行训练网络结构,而使用ImageNet上训练好的CNN结构。R-CNN文献paper给我们证明了一个理论,如果你不进行fine-tuning,也就是你直接把Alexnet模型使用于工程,类似于HOG、SIFT一样做特征提取,说明使用ImageNet训练过的CNN结构已经在特征提取方面达到了HOG的效果。
文章这样说:不针对特定的任务。然后把提取的特征用于分类,结果发现p5的精度竟然跟f6、f7差不多,而且f6提取到的特征还比f7的精度略高;如果你进行fine-tuning了,那么f7、f6的提取到的特征最会训练的svm分类器的精度就会飙涨。
Two-Stage方法
Two-Stage方法为Region proposal和CNN分离的方法,把检测问题分解为原始的寻找框和目标分类两步问题。先后出现R-CNN、SPP-NET、Fast R-CNN、Faster R-CNN、R-FCN、Mask RCNN。
Two-Stage方法主要问题是从大量框选取候选框问题,使用的方法有:objectness [1],selective search [39],category-independent object proposals [14], constrained parametric min-cuts (CPMC) [5], multi-scale combinatorial grouping [3], and Cires¸an et al. [6], who detect mitotic cellsby applying a CNN to regularly-spaced square crops, which are a special case of region proposals.
While R-CNN is agnostic to the particular region proposal method, we useselective search to enable a controlled comparison with prior detection work (e.g., [39, 41]).。R-CNN使用了selective search方法,下图为一个评测。
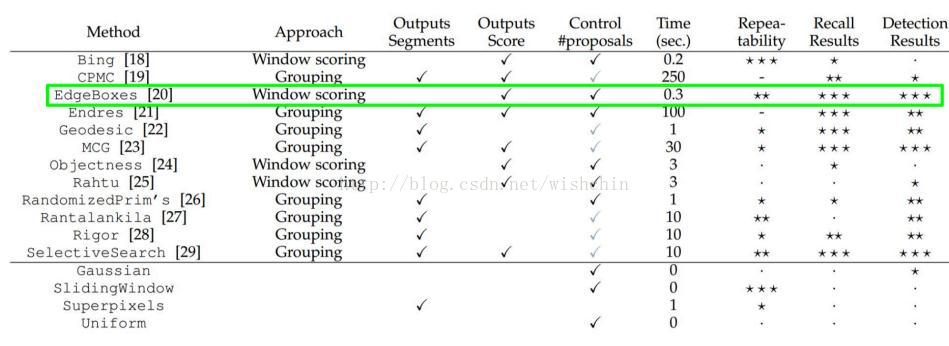
参考文章:基于CNN的目标检测发展过程
参考文章:基于R-CNN的物体检测 看一下即可
R-CNN方法
2014年CVPR上的经典paper:《Rich feature hierarchies for Accurate Object Detection and Segmentation》,这篇文章的算法思想又被称之为:R-CNN(Regions with Convolutional Neural Network Features),是物体检测领域曾经获得state-of-art精度的经典文献。
这篇paper的思想,改变了物体检测的总思路,现在好多文献关于深度学习的物体检测的算法,基本上都是继承了这个思想,比如:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》。
R-CNN的检测步骤:
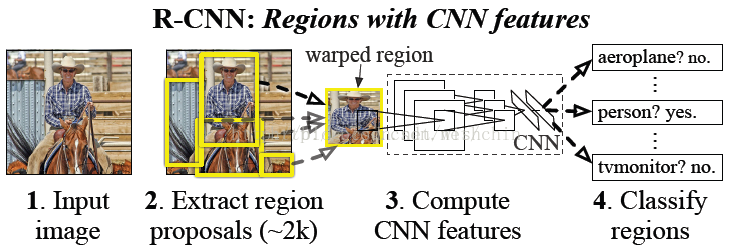
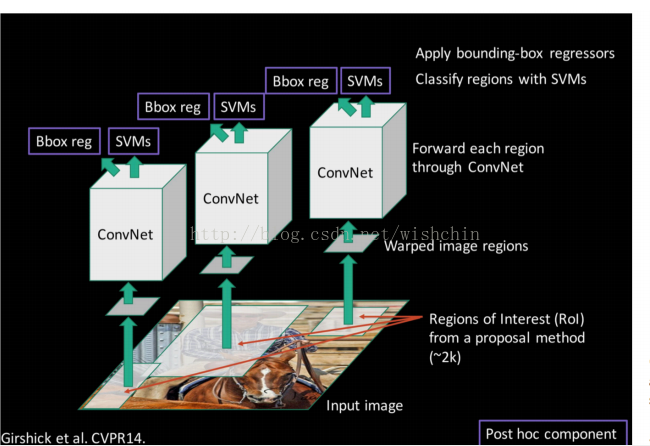
分别在选框和CNN两个步骤进行了优化。
步骤一:预训练(或者下载)一个分类模型(比如AlexNet);
步骤二:对该模型做fine-tuning: 将分类数从1000改为20;去掉最后一个全连接层(使用SVM分类);
步骤三:1.特征提取
• 提取图像的所有候选框(选择性搜索-selective search)
• 对于每一个区域:修正区域大小以适合CNN的输入,做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘
步骤四:2.训练一个SVM分类器(二分类)来判断这个候选框里物体的类别
• 每个类别对应一个SVM,判断是不是属于这个类别,是就是positive,反之nagative
步骤五:3.使用回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。
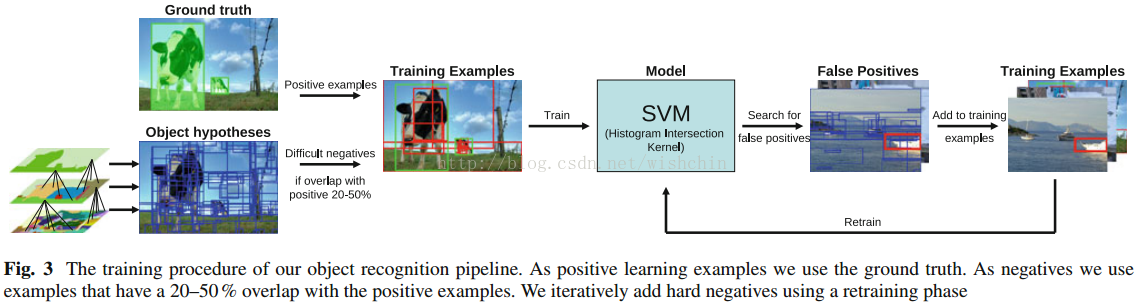
R-CNN使用精细调整选定框的方法实现了较高的检测性能。mAP和IOU都达到了一个很高的标准。
使用的selective search方法,参考:"Selective search for object recognition." International journal of computer vision, 104(2) (2013): 154-171.此文必看:selective search方法。
这一步可以看做是对图像的过分割,都是过分割,本文SS方法的过人之处在于预先划分的区域什么大小的都有(满足目标多尺度的要求),而且对过分割的区域还有一个合并的过程(区域的层次聚类),最后剩下的都是那些最可能的候选区域,然后在这些已经过滤了一遍的区域上进行后续的识别等处理,这样的话,将会大大减小候选区域的数目,提供了算法的速度。参考超像素分割聚类过程。
举例一般合并规则:
优先合并以下四种区域:
- 颜色(颜色直方图)相近的
- 纹理(梯度直方图)相近的
- 合并后总面积小的
- 合并后,总面积在其BBOX中所占比例大的
第三条,保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域。
例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。
不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh。
第四条,保证合并后形状规则。
上述四条规则只涉及区域的颜色直方图、纹理直方图、面积和位置。合并后的区域特征可以直接由子区域特征计算而来,速度较快例:左图适于合并,右图不适于合并。

SPP Net
SPP:Spatial Pyramid Pooling(空间金字塔池化)
参考文章:SPP-Net:CNNs添加一尺度不变特征-神经元层
它的特点有两个:
1. 结合空间金字塔方法实现CNNs的对尺度输入的可变性; 2. 只对原图提取一次卷积特征。
空间金字塔池化:一般CNN后接全连接层或者分类器,他们都需要固定的输入尺寸,因此不得不对输入数据进行crop或者warp,这些预处理会造成数据的丢失或几何的失真。SPP Net的第一个贡献就是将金字塔思想加入到CNN,实现了数据的多尺度输入。
一次性卷积特征提取:在R-CNN中,每个候选框先resize到统一大小,然后分别作为CNN的输入,这样是很低效的。
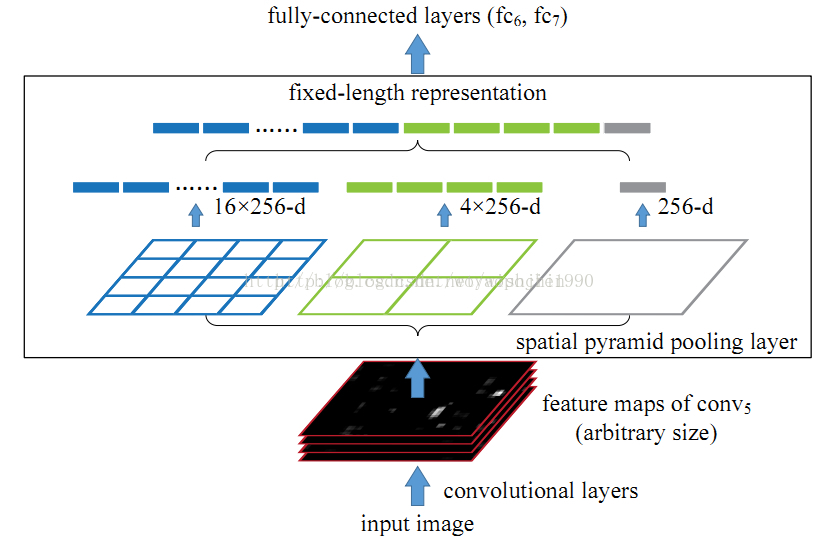
所以SPP Net根据这个缺点做了优化:只对原图进行一次卷积得到整张图的feature map,然后找到每个候选框zaifeature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层。节省了大量的计算时间,比R-CNN有一百倍左右的提速。
RCNN的缺点:一、没有共享卷积运算;二、即使使用了selective search等预处理步骤来提取潜在的bounding box作为输入,但是RCNN仍会有严重的速度瓶颈,原因也很明显,就是计算机对所有region进行特征提取时会有重复计算,Fast-RCNN正是为了解决这个问题诞生的。
Fast R-CNN 和Faster R-CNN
R-CNN的进阶版Fast R-CNN就是在RCNN的基础上采纳了SPP Net方法,对RCNN作了改进,使得性能进一步提高。成功的让人们看到了Region Proposal+CNN这一框架实时检测的希望,原来多类检测真的可以在保证准确率的同时提升处理速度,也为后来的Faster-RCNN做下了铺垫。
Faster R-CNN的主要贡献是设计了提取候选区域的网络RPN,代替了费时的选择性搜索,使得检测速度大幅提高。加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了。此外RPN网络和识别网络共享卷积层,加快数据forward速度。做这样的任务的神经网络叫做Region Proposal Network(RPN)。
具体做法:
• 将RPN放在最后一个卷积层的后面;
• RPN直接训练得到候选区域。怎么训练?
具体方案还要好好看看论文:Faster R-CNN Towards Real-Time Object Detection with Region Proposal Networks。
算法总结:
RCNN:
1. 在图像中选择约1000-2000个候选框 (使用selective search);2. 每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取 ;3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类 ;4. 对于属于某一特征的候选框,用回归器进一步调整其位置。
Fast RCNN:
添加SPP层,
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索);2. 对整张图片输进CNN,得到feature map;3. 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层;4. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类 ;5. 对于属于某一特征的候选框,用回归器进一步调整其位置。
Faster RCNN:
1. 对整张图片输进CNN,得到feature map;2. 卷积特征输入到RPN,得到候选框的特征信息;3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类 ;4. 对于属于某一特征的候选框,用回归器进一步调整其位置。
值得注意的是,尽管RPN与fast rcnn 共享卷积层,但是在模型训练的过程中,需要反复训练RPN网络和fast rcnn 网络(两个网络的核心卷积层是共享的),不能有所偏颇,网络共享主要作用还是推进forward的速度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号