梨视频多页数据爬取思路
梨视频多页数据爬取思路
先来研究多页的思路:
我们先复制一个主页的数据然后打开网页源代码,ctr+F查找

所以我们就可以试着给该页面地址发送请求看能不能拿到数据
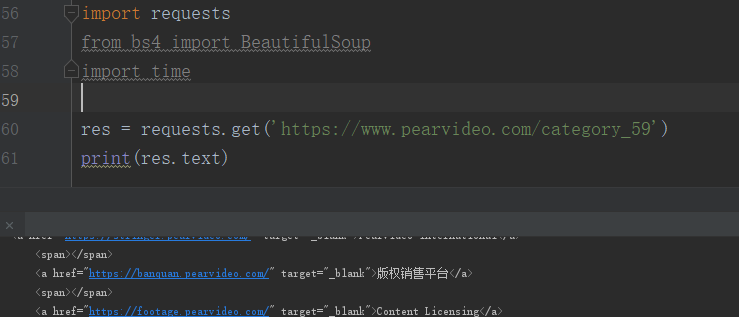
发现可以拿到
因为本题只需要我们爬取视频数据即可,所以我们要先获取所有的详情页的地址链接
通过研究详情页发现地址规律是后面加上一个video_...

并且我们发现了这个video和主页的a标签中的video是一样的

那我们可以大胆地猜测详情页的地址是固定的url加上video_....
所以我们要获取a标签中href的video id
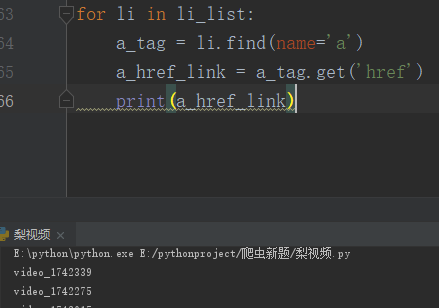
然后我们拼接地址,然后尝试一下能不能进入详情页
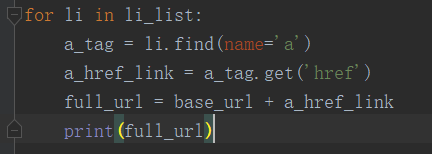
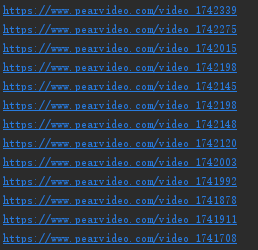
研究发现详情页视频数据并不是直接加载的 也就意味着朝上述地址发送get请求没有丝毫作用
所以我们需要通过fetch来查找动态加载数据地址

并且我们还发现了在preview里有一个可疑地址是.mp4的
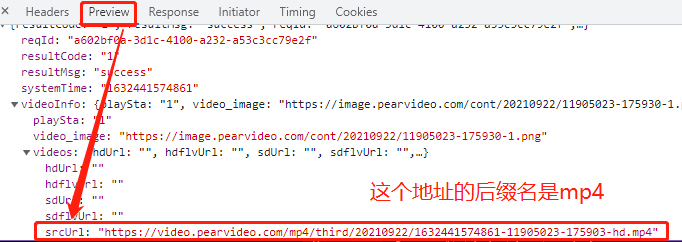
但是发现这个地址并不是真正的地址,在浏览器中输入这个地址
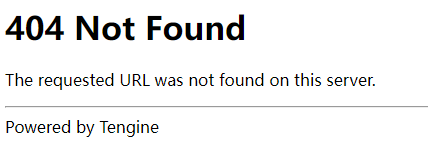
通过network查找发现了视频真实的地址

两个地址进行比对发现其中只有systemTime的部分不一样,并且应该是cont-xxxx
梨视频官网还做了一个防爬措施,只需要把它加到请求头中即可

我们需要给详情页的动态加载数据地址发送请求获取到srcUrl和systemTime

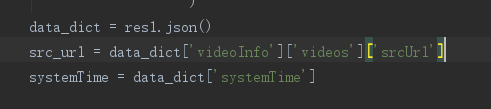
接着就需要我们自己替换出真实的地址

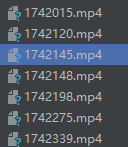
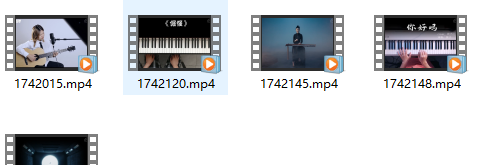
然后就可以向这个地址发get请求了, 利用os模块创建文件夹并且写入文件夹中

然后我们会神奇的发现,视频数据就真的被我们爬下来了
多页爬取:
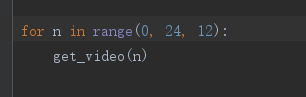
我们通过研究发现梨视频这个网站的动态加载是通过检测鼠标滚轮滚到底部以后,浏览器会发送一个请求
每次请求的地址start都比前前一个地址大12 可以猜测12是内容个数,所以应该是一个等差数列

那我就可以用%s给start的值占位让它每次都加12,然后for循环发送请求

 浙公网安备 33010602011771号
浙公网安备 33010602011771号