爬虫练习
数据的加载方式
1.常见的加载方式
朝服务器发请求 页面数据直接全部返回并加载 """ 如何验证数据是直接加载还是其他方式 浏览器空白处鼠标右键 点击查看网页源码 在源码界面搜索对应的数据 如果能收到就表示改数据是直接加载的(你可以直接发送相应请求获取)
2.内部js代码请求
先加载一个页面的框架 之后再朝各项数据的网址发送请求获取数据
如何查找关键性的数据来源 需要借助于浏览器的network检测核对内部请求
请求的数据一般都是json格式
爬取天气数据
1.拿到页面之后先分析数据加载方式
2.发现历史数据并不是直接加载的
统一的研究方向>>>:利用network查看
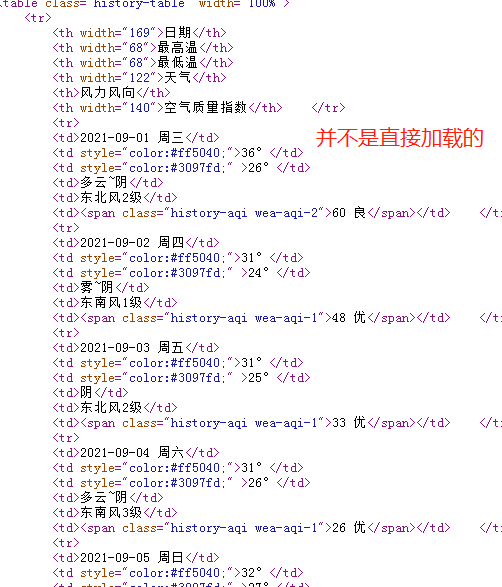
3.查找到可疑的网址并查看请求方式
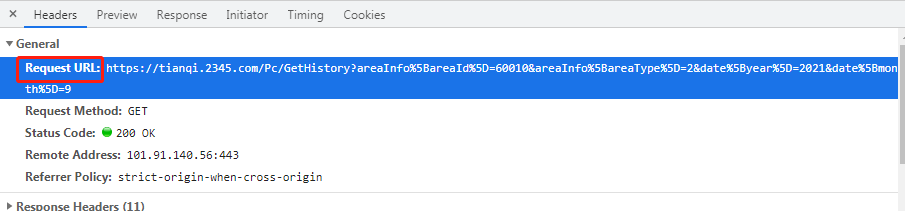
如果是get请求那么可以直接拷贝网址在浏览器地址栏访问
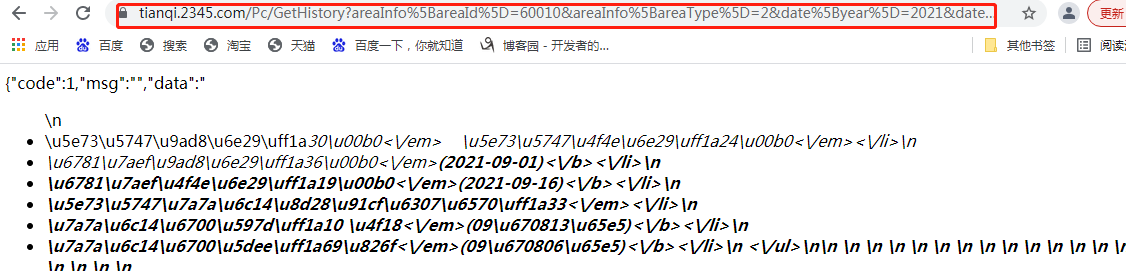
4.将请求获得的数据分析
https://www.bejson.com/
点击unicode转中文
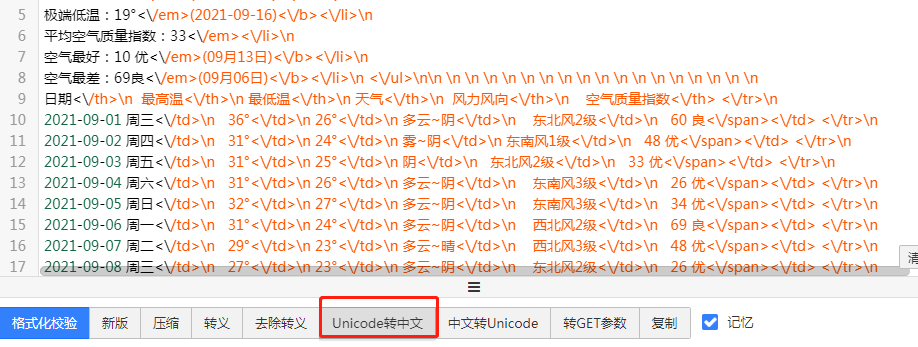
5.利用requests模块朝发现的地址发送get请求获取的json数据
6.可以研究历史天气数据的url找规律 即可爬取指定月份的数据
import requests import pandas res = requests.get( 'https://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=60010&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D=9') print(res.json()) # 反序列化成字典之后 比对一下数据在哪个键值对中 real_data_html = res.json().get('data')
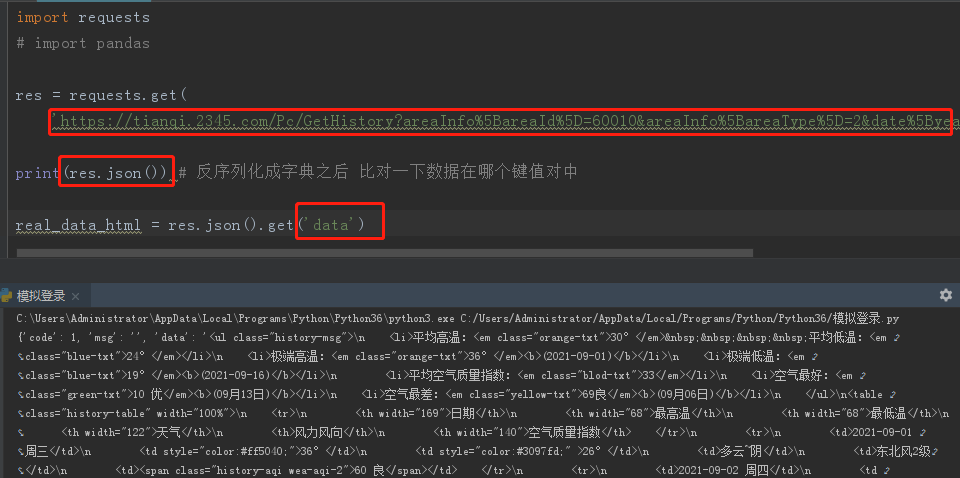
后期再学 目前了解
df1 = pandas.read_html(real_data_html)[0] df1.to_excel(r'qianqi.xlsx')
爬取百度翻译
1.在查找单词的时候页面是在动态变化的
2.并且针对单词的详细翻译结果数据是动态请求获取的
3.打开network之后输入英文查看内部请求变化
sug请求频率固定且较高
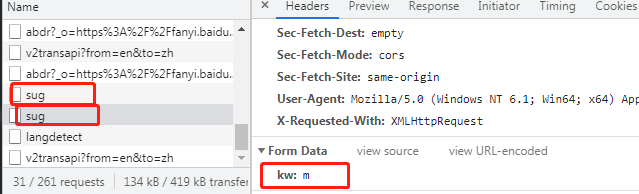
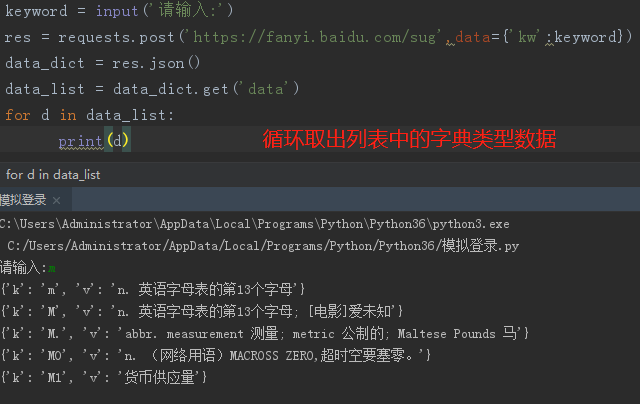
4.研究sug请求发现每次输入的单词都会朝固定的一个网址发送post请求

并且请求体携带了改单词数据
import requests keyword = input('请输入你需要查询的单词>>>:') res = requests.post('https://fanyi.baidu.com/sug', data={'kw': keyword} ) data_dict = res.json() data_list = data_dict.get('data') for d in data_list: print(d)
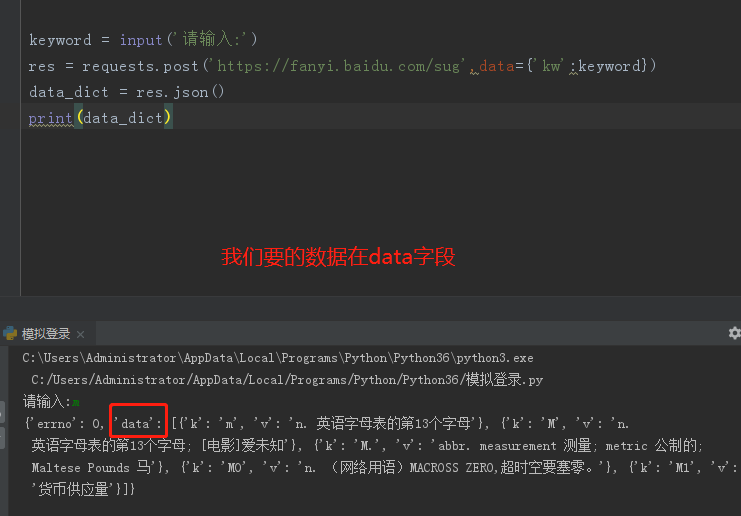
爬取药品许可证
需求:爬取药品企业生产许可证详细信息
1.先明确是否需要爬取页面数据 如果需要则先查看数据的加载方式
2.通过network查看得知数据是动态加载的 网页地址只会加载一个外壳
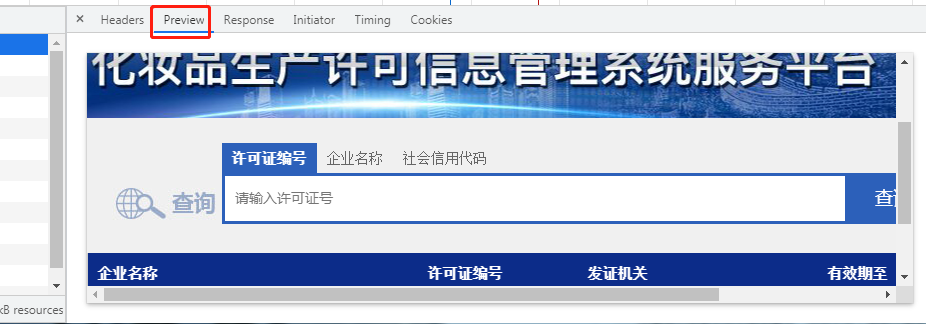
3.通过network点击fetch/xhr筛选动态获取数据的地址和请求方式
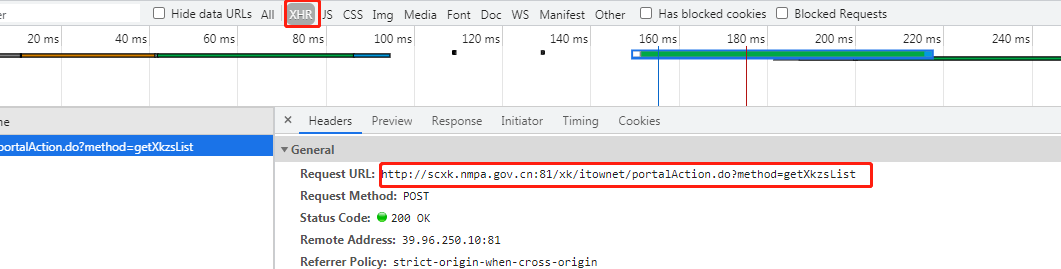
4.利用requests模块发送相应请求获取数据
5.利用浏览器点击详情页找到我们需要的数据
发送请求的URL:http://scxk.nmpa.gov.cn:81/xk/itownet/portal/dzpz.jsp?id=911d4f256300476abb78012427d38c9d
6.由于我们需要爬取详情页的数据所以要验证数据的加载方式
7.详情页核心数据也是动态加载的 发现是post请求并携带了一个id参数
import requests res = requests.post('http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList', data={ 'on': 'true', 'page': 1, 'pageSize': 15, 'productName': '', 'conditionType': 1, 'applyname': '', 'applysn': ''}) # data_dict = res.json() # data_list = data_dict.get('list') # 上述两步合成一步 data_list = res.json().get('list')
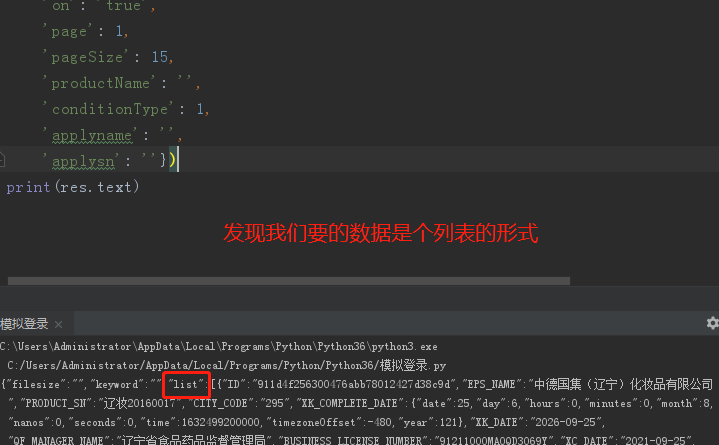
# 循环获取格式id值 for d in data_list: # 字段取值 获取id值 ID = d.get("ID") # 发送网络请求 res1 = requests.post('http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById', data={'id':ID} ) # 获取数据结果 data_dict = res1.json() '''结合实际需求 保存相应的数据 文件操作 数据库'''
深入研究
1.多页数据如何获取(思路非常重要)
1.先点击页码查看url的变化
如果数据变化url不变 那么数据肯定是动态加载的
如果数据变化url也变 那么数据可能是直接加载也可能是动态
2.针对上述案例 数据是动态加载 所以需要研究每一次点击页码内部请求
3.研究请求体参数得知数据页由page控制
4.写一个for循环即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号