cookie与session
内容详细
cookie与session
cookie 与 session 的发明是专门用来解决http协议无状态的特点
http协议无状态>>>: 不保存用户端状态 """早期的网址不需要保存用户状态 所有人来访问都是相同的数据""" 随着时代的发展越来越多的网址需要保存用户状态
cookie:保存在客户端浏览器上面的键值对数据
# 用户第一次登录成功之后,浏览器会保存用户名和密码,之后访问网站都会自动保存该用户名和密码
session:保存在服务端上面的用户相关的数据
# 用户名第一次登录成功之后 服务端会返回给客户端一个随机字符串(有时候也可能是多个)
客户端浏览器保存改随机字符串之后访问网站都会带着该随机字符串
cookie和session是什么关系:session需要依赖cookie
# session需要依赖cookie 只要是涉及到用户登录都需要使用cookie 当然浏览器也可以拒绝保存数据
cookie实战
1.浏览器network选项中 请求体对应的关键字是Form Data
登录地址 http://www.aa7a.cn/user.php 请求体数据格式 username: 616564099@qq.com password: 123123 captcha: jv3d remember: 1 ref: http://www.aa7a.cn/user.php?act=logout act: act_login:
**写爬虫一定要先使用浏览器研究 再写代码**
1.研究登录数据提交给后端的url地址
2.研究登录post请求携带的请求体数据格式
3.模拟发送post请求
代码演示:1.模拟登录华华手机官网
import requests res = requests.post('http://www.aa7a.cn/user.php', data={ "username": "616564099@qq.com", "password": "lqz123", "captcha": "kuyb", "remember": 1, "ref": "http://www.aa7a.cn/user.php?act=logout", "act": "act_login" } # data参数携带请求体数据 )
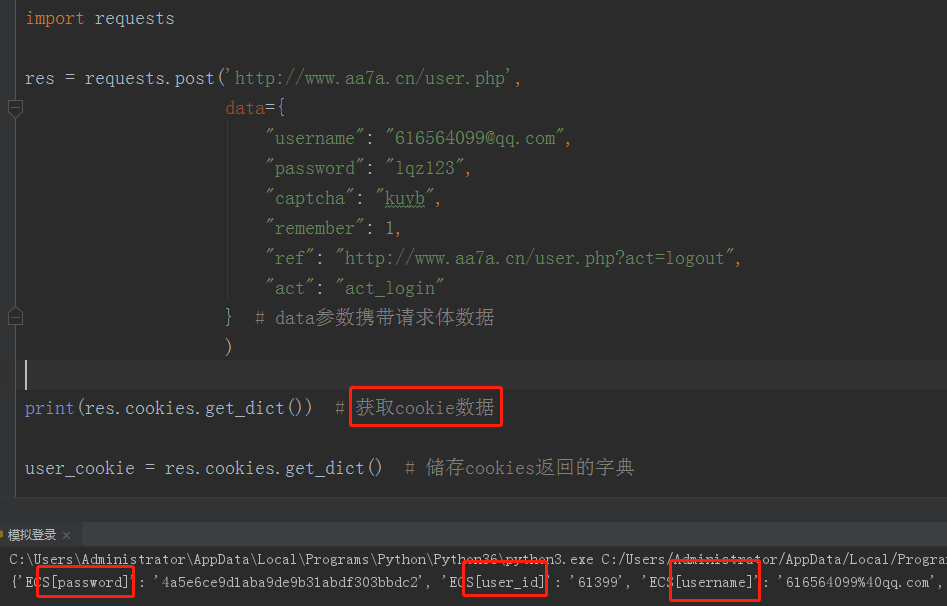
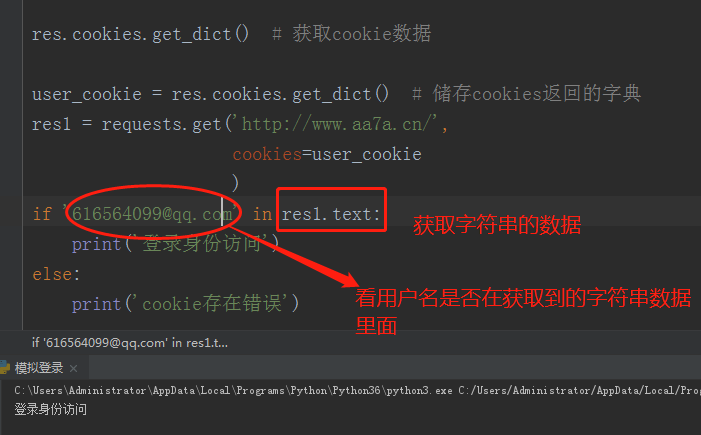
2.获取cookie数据
print(res.cookies.get_dict())# 获取cookie数据 user_cookie = res.cookies.get_dict() # 储存cookies返回的字典
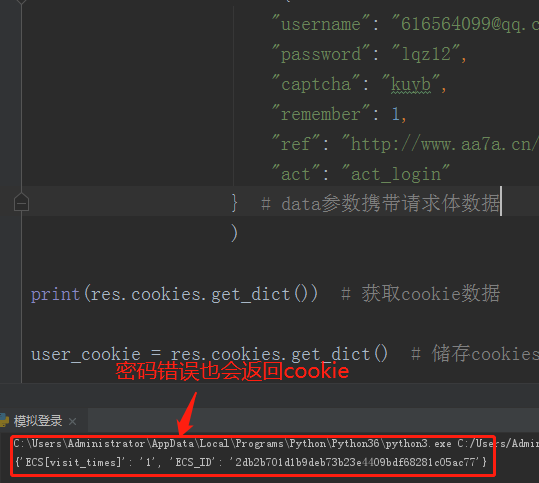
用户名或密码错误的情况下返回的cookie数据
{'ECS[visit_times]': '1', 'ECS_ID': '69763617dc5ff442c6ab713eb37a470886669dc2'}
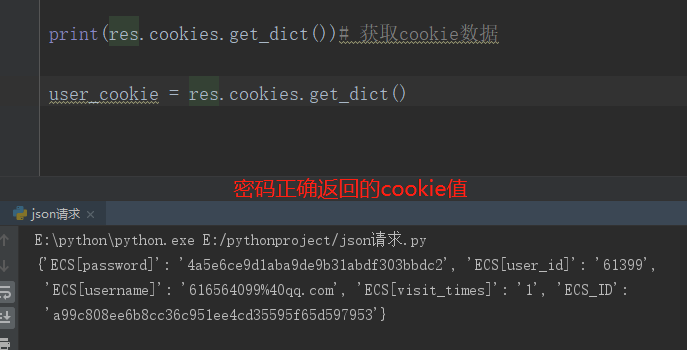
用户名和密码都正确的情况下返回的cookie数据
{ 'ECS[password]': '4a5e6ce9d1aba9de9b31abdf303bbdc2', 'ECS[user_id]': '61399', 'ECS[username]': '616564099%40qq.com', 'ECS[visit_times]': '1', 'ECS_ID': 'e18e2394d710197019304ce69b184d8969be0fbd' }
使用cookie访问官网(代码实战)
res1 = requests.get('http://www.aa7a.cn/', cookies=user_cookie ) if'616564099@qq.com' in res1.text: print('登录身份访问') else: print('cookie存在错误')
获取大数据
stream参数:一点一点的取,比如下载视频是,如果视频是特别的大
用response.content然后一下子写到文件中是不合理的
import requests response = requests.get('xxx网址', stream=True) with open('b.mp4','wb')as f: for line in response.iter_content(): # 一行行读取数据 f.write(line)
json格式
json格式的数据有一个非常显著的特征>>>:双引号
在网络爬虫领域 其实内部有很多数据都是采用的json格式
**前后端数据交互一般使用的都是json格式**
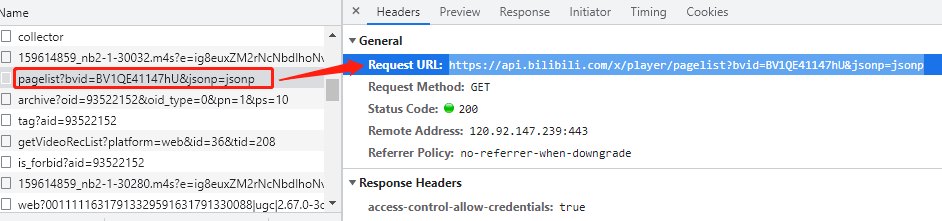
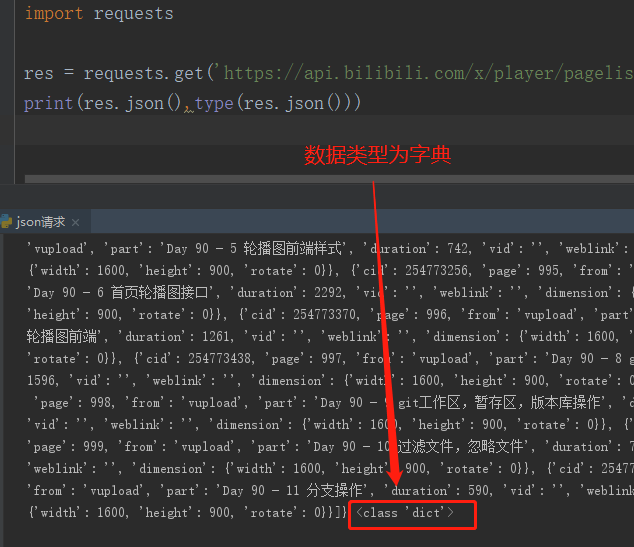
import requests res = requests.get('https://api.bilibili.com/x/player/pagelist?bvid=BV1QE41147hU&jsonp=jsonp') print(res.json()) # 可以直接将json格式字符串转换成python对应的数据类型
SSL相关报错(苹果电脑常见)
百度搜索解决
IP代理池
有很多网站针对客户端IP地址访问该网站的次数不能超过30次超过了就封禁该IP地址
针对该防爬措施该如何解决
IP代理池 里面有很多IP地址每次访问从中随机挑选一个
代理设置:先发送请求给代理,然后由代理帮忙发送(封ip是常见的事情)
import requests proxies={ 'http':'114.99.223.131:8888', 'http':'119.7.145.201:8080', 'http':'175.155.142.28:8080', } respone=requests.get('https://www.12306.cn', proxies=proxies)
Cookie代理池
有很多网站针对客户端的cookie也存在防爬措施
比如一分钟之内同一个cookie访问该网站的次数不能超过30次超过了就封禁该cookie
针对该防爬措施如何解决
cookie代理池 里面有很多cookie每次访问从中随机挑选一个
respone=requests.get('https://www.12306.cn', cookies={})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号