
os模块 hashlib模块 random模块 logging模块 json模块
今日内容概要
-
-
hashlib模块
-
random模块
-
logging模块
-
今日内容详细
强调
'''在创建py文件的时候文件名一定不能跟模块名冲突'''
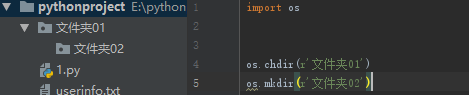
import os
# 创建文件夹
# os.mkdir(r'文件夹01') # 只能创建单级目录
# os.makedirs(r'文件夹02\文件夹03') # 可以创建多级目录
# os.makedirs(r'文件夹03')
![]()

# 删除文件夹
# os.rmdir(r'文件夹01')
# os.rmdir(r'文件夹02\文件夹03') # 默认只能删一级空目录
# os.removedirs(r'文件夹02\文件夹03\文件夹04') # 可以删除多级空目录
![]()

# 查看
# print(os.listdir()) # 查看指定路径下所有的文件及文件夹
# print(os.listdir('D:\\')) # 查看指定路径下所有的文件及文件夹
# print(os.getcwd()) # 查看当前所在的路径
# os.chdir(r'文件夹03') # 切换当前操作路径
# print(os.getcwd()) # 查看当前所在的路径
![]()

# 判别
# print(os.path.isdir(r'a.txt')) # 判断是否是文件夹
# print(os.path.isdir(r'文件夹03'))
# print(os.path.isfile(r'a.txt')) # 判断是否是文件
# print(os.path.isfile(r'文件夹03'))
# print(os.path.exists(r'a.txt')) # 判断当前路径是否存在
# print(os.path.exists(r'文件夹03'))
# 路径拼接
"""
不同的操作系统路径分隔符是不一样的
windows是 \
mac是 /
"""
# res = os.path.join('D:\\','a.txt') # 该方法可以针对不同的操作系统自动切换分隔符
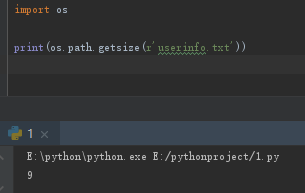
# 文件大小
print(os.path.getsize(r'a.txt')) # 字节数
![]()
加密模块
将明文数据按照一定的逻辑变成密文数据
一般情况下密文都是由数字字母随机组合而成
加密算法
将明文数据按照一定的逻辑(每个算法内部逻辑都不一样)
加密之后的密文不能反解密出明文
# 常见加密算法:md5 base64 hmac sha系列
"""算法生成的密文越长表示该算法越复杂"""
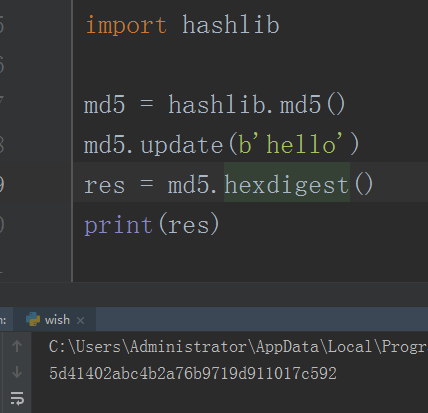
import hashlib
# 选择加密算法:一般情况下采用md5即可
# md5 = hashlib.md5()
# 将待加密的数据传入算法中
# md5.update(b'hello') # 数据必须是bytes类型(二进制)
# 获取加密之后的密文
# res = md5.hexdigest()
# print(res)
![]()
# 加盐处理:在对用户真实数据加密之前再往里添加额外的干扰数据
# 选择加密算法:一般情况下采用md5即可
# md5 = hashlib.md5()
# # 将待加密的数据传入算法中
# # 加盐
# md5.update('自己定制的盐'.encode('utf8'))
# md5.update(b'hello') # 数据必须是bytes类型(二进制)
# # 获取加密之后的密文
# res = md5.hexdigest()
# print(res)
# 动态加盐
# 选择加密算法:一般情况下采用md5即可
md5 = hashlib.md5()
# 将待加密的数据传入算法中
# 加盐
md5.update('不固定 随机改变'.encode('utf8'))
md5.update(b'hello') # 数据必须是bytes类型(二进制)
# 获取加密之后的密文
res = md5.hexdigest()
print(res)
随机数模块
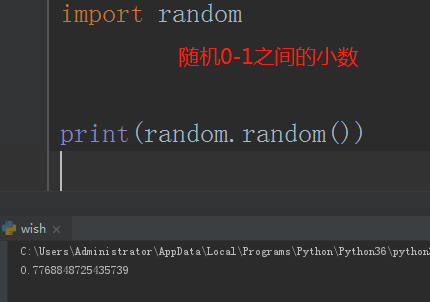
import random
# 随机返回0-1之间的小数
# print(random.random())
![]()
# 随机返回指定区间的整数 包含首尾
# print(random.randint(1,6)) # 掷色子
# 随机抽取一个
# print(random.choices(['一等奖','二等奖','谢谢回顾'])) # 抽奖
![]()
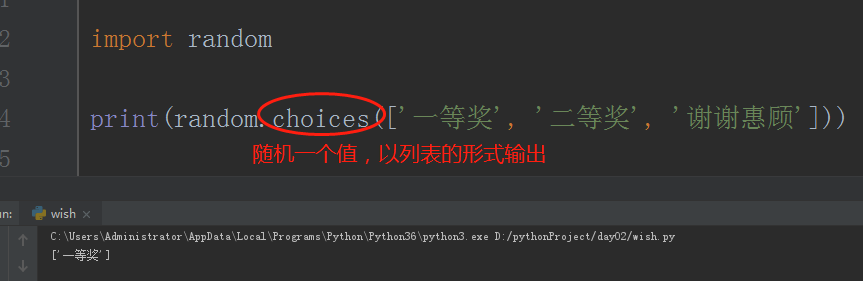
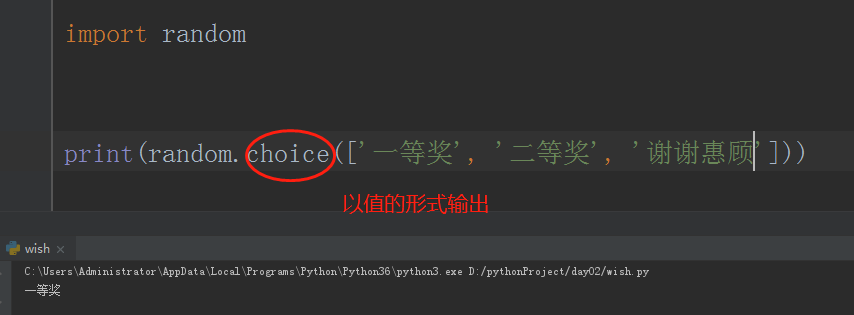
# print(random.choice(['一等奖','二等奖','谢谢回顾']))
![]()
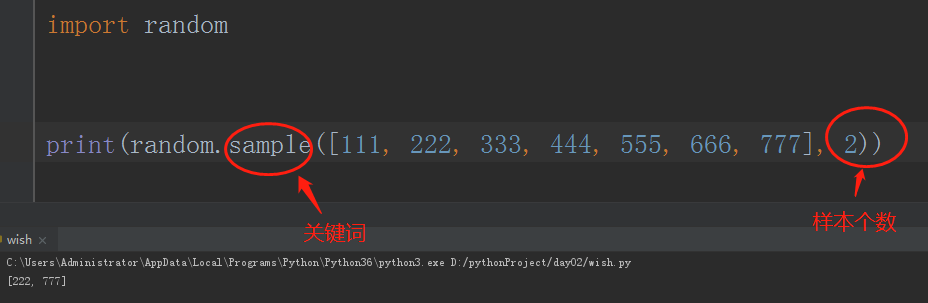
# 随机抽取指定样本个数
# print(random.sample([111, 222, 333, 444, 555, 666, 777], 2))
![]()
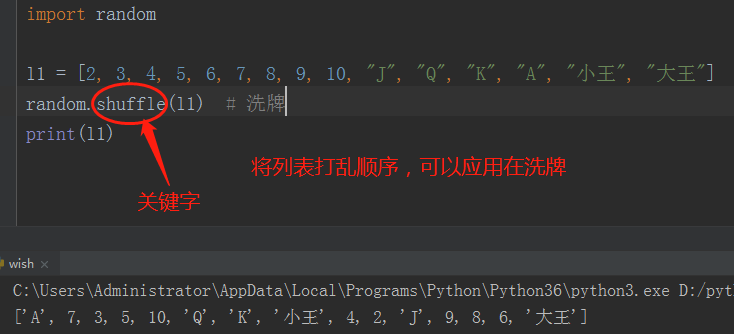
# 随机打乱元素
# l = [2, 3, 4, 5, 6, 7, 8, 9, 10, "J", "Q", "K", "A", "小王", "大王"]
# random.shuffle(l) # 洗牌
# print(l)
![]()
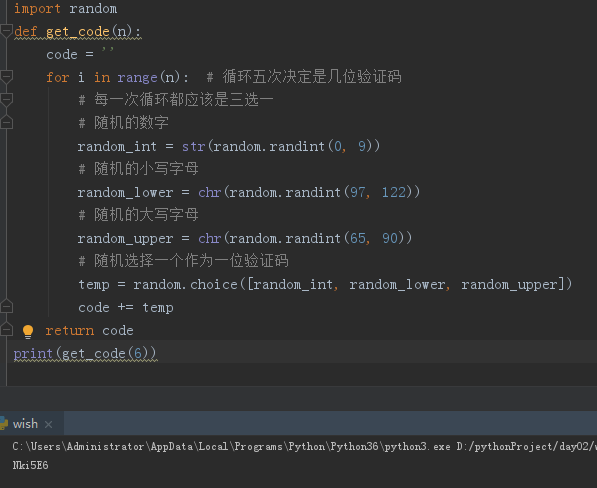
# 随机验证码
"""
产生一个五位数随机验证码(搜狗笔试题)
每一位都可以是数字\小写字母\大写字母
"""
def get_code(n):
code = ''
for i in range(n): # 循环五次决定是几位验证码
# 每一次循环都应该是三选一
# 随机的数字
random_int = str(random.randint(0, 9))
# 随机的小写字母
random_lower = chr(random.randint(97, 122))
# 随机的大写字母
random_upper = chr(random.randint(65, 90))
# 随机选择一个作为一位验证码
temp = random.choice([random_int, random_lower, random_upper])
code += temp
return code
print(get_code(5))
![]()
import logging
# 日志级别
# logging.debug('debug message')
# logging.info('info message')
# logging.warning('warning message')
# logging.error('error message')
# logging.critical('critical message')
# import logging
#
# file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',)
# logging.basicConfig(
# format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
# datefmt='%Y-%m-%d %H:%M:%S %p',
# handlers=[file_handler,],
# level=logging.ERROR
# )
#
# logging.error('你好')
# import time
# import logging
# from logging import handlers
#
# sh = logging.StreamHandler()
# rh = handlers.RotatingFileHandler('myapp.log', maxBytes=1024,backupCount=5)
# fh = handlers.TimedRotatingFileHandler(filename='x2.log', when='s', interval=5, encoding='utf-8')
# logging.basicConfig(
# format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
# datefmt='%Y-%m-%d %H:%M:%S %p',
# handlers=[fh,sh,rh],
# level=logging.ERROR
# )
#
# for i in range(1,100000):
# time.sleep(1)
# logging.error('KeyboardInterrupt error %s'%str(i))
import logging
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log',encoding='utf-8')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
d = {'username': 'jason', 'pwd': 123}
import json
# 简单的理解为
# 可以将其他数据类型转换成字符串
# 也可以将字符串转换成其他数据类型
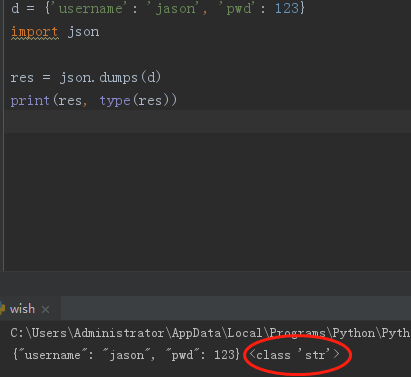
"""序列化:将其他数据类型转换成json格式的字符串"""
# res = json.dumps(d)
# print(res, type(res)) # {"username": "jason", "pwd": 123} <class 'str'>
# d1 = {"username": "jason", "pwd": 123}
# print(d1)
![]()
# 只有json格式字符串才会是双引号 双引号就是判断json格式字符串的重要依据
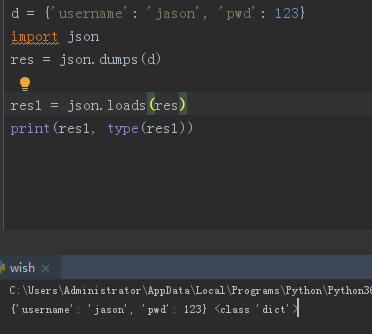
"""反序列化:将json格式字符串转换成对应的数据类型"""
# res1 = json.loads(res)
# print(res1, type(res1))
# {'username': 'jason', 'pwd': 123} <class 'dict'>
![]()
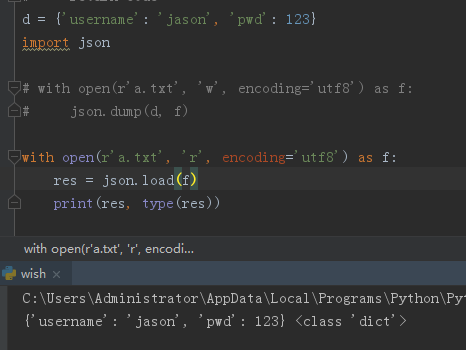
# with open(r'a.txt','w',encoding='utf8') as f:
# 文件序列化
# json.dump(d,f)
# with open(r'a.txt','r',encoding='utf8') as f:
# 文件反序列化
# res = json.load(f)
# print(res,type(res))
![]()
并不是所有的python数据都可以转json格式字符串
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号