说起来你可能不信,一个正则就能让页面卡死
某个阳光明媚的下午,我正悠闲的品着刚买的滇红,测试小姐姐突然急匆匆的找到我:
“快看一下群里,文章编辑器出问题了!”
我手中的滇红瞬间不香了,抓了抓所剩无几的头发,开始了漫长的 Debug 环节
经过排查,发现问题的根源居然是一段正则表达式...
一、问题重现
// 在浏览器控制台中运行下面的代码
// 放心,不会卡死的
const reg = /^<del>(.|\s)*<\/del>$/;
const str = '<del>hello world! hello world! hello world! hello world! hello world! hello world! hello world! hello world! hello world! hello world! hello world! </del><ins>hello wrold!</ins>';
start = Date.now();
const res = reg.test(str);
end = Date.now();
console.log('耗时:' + (end - start));
上面就是出问题的正则,但是字符串更加复杂(不然一执行代码,浏览器就崩溃了)
这段正则本身的目的是为了匹配 <del> 标签的内容。由于 . 不包含换行符,所以用 (.|\s)* 来指代内容
而由于 . 和 \s 有重合的部分,再加上或运算符 | 和贪婪匹配 * ,让正则表达式的运算量指数级增加,最终呈现出页面崩溃的结果
二、正则引擎
为了解释这个问题,就得了解正则表达式的工作原理
正则有两种工作方式:用文本去匹配正则(DFA)、正则去匹配文本(NFA)
举个例子:
/ja(cket|vate|vascr)/.test('javascript')
如果是 DFA,会用字符串去匹配,过程是这样的:

在匹配到第三个字符 v 的时候,会有三个备选分支,但 cket 分支不满足规则,被排除。
所以在匹配第四个字符 a 的时候,只有两个备选分支,直到第五个字符 s,排除掉 vate 分支,最后只剩下一个备选分支 vascr,最终完成匹配。
而对于 NFA,是用正则来匹配文本:

在匹配到 ja 之后,会先匹配 cket 分支,发现 c 不匹配,返回上一个节点。
返回节点之后会进入下一个分支,即 vate 分支,直到匹配到 t 才会不匹配,然后返回上一节点。
由于上一节点 a 并没有别的分支,所以继续返回,直到返回最开始的 ja 节点,进入最后一个 vascr 分支,最后完成匹配。
从这两个分析可以看出, DFA 在用文本来匹配正则的时候,会逐渐排除不满足条件的备选项。
而 NFA 会匹配每个分支,如果分支不匹配,则回到上一个节点,进入当前节点的另一个分支继续匹配。
也就是说 NFA 就像是在走迷宫,遇到岔路的时候,先选择第一条路走到头。如果走不通,则返回岔路口,进入下一条路继续探索。这个返回岔路口的过程叫做回溯。
所以 DFA 引擎的效率比 NFA 更高,但很可惜的是,JavaScript 的正则的引擎是 NFA 类型。
三、回溯
上面已经提到,NFA 在匹配某一个分支失败时,会返回节点,尝试另一条分支,这种行为被称作回溯。
如果只是上面举的简单例子,回溯并不会造成严重的性能问题,可如果是有多个备选状态,再加上贪婪匹配,这个过程就很恐怖了。
比如这样一个正则:
/(.*)+\d/.test('abcd')
这里的 .* 可以匹配任意字符(\n除外)任意次数,再加上贪婪特性,第一次匹配时 .* 会直接吃掉 abcd ,然后匹配 \d 失败,进行第一次回溯:
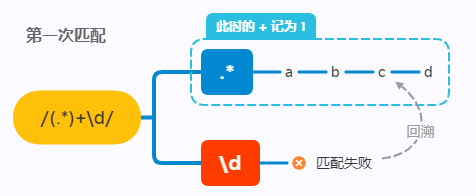
然后 .* 将 d 吐出来,本身只匹配 abc。但由于 + 的原因, .* 会进行第二次匹配,然后 \d 匹配失败,再次回溯:

第三次匹配的时候, + 重新记为 1, .* 依然为 abc,剩下一个 d 交给 \d 匹配。由于 \d 需要匹配数字,所以匹配失败,继续回溯:
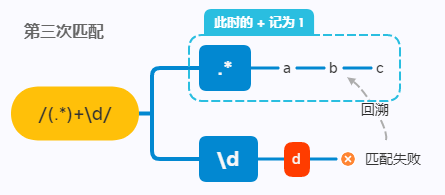
以此类推,正则会在经过很多次回溯之后,才会得出匹配失败的结论
四、优化方案
由于回溯机制的存在,我们在写正则的时候一定要牢记:
尽可能的减少备选分支的数量。
比如上例的正则: /(.*)+\d/ ,这里的 + 和 * 存在重复匹配
如果我们最终的期望是匹配 test1、hello123 这种以数字结尾,总长度不小于 2 的字符串
将正则表达式改为 /.+\d/ 就能满足我们的需求
而在文章一开始提到的线上暴雷的正则: /^<del>(.|\s)*<\/del>$/
其实也是因为 . 和 \s 有重合的匹配规则,改为 (.|\n) 即可
另外,如果我们能预期目标字符串的构成,将备选分支更少的规则写在前面,这样正则就能更早的返回结果
所以调整备选分支的顺序也是一个优化方案
最后,在可以选择的情况,使用 DFA 才能从根本上解决问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号