Java8 Stream
什么是Stream
Java8 API添加了一个新的抽象称为流Stream,可以以一种声明的方式处理数据,给我们操作集合(Collection)提供了极大的便利。
Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。
stream可以由数组或集合创建,对流的操作分为两种
- 中间操作,每次返回一个新的流,可以有多个,类似MapReduce中的Map
- 终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值。类似MapReduce中的Reduce
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
Stream特性
-
stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
-
stream不会改变数据源,通常情况下会产生一个新的集合或一个值。
-
stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
Stream的创建
- 通过java.utiil.Collection.stream()方法用集合创建流
List<String> list = Arrays.asList("a", "b", "c");
//创建一个顺序流
Stream<String> stream = list.stream();
//创建一个并行流
Stream<String> parallelStream = list.parallelStream();
- 使用java.util.Arrays.stream(T[] array)方法用数组创建流
String[] arr = {"a", "b", "c"};
Stream stream = Arrays.stream(arr);
- 使用Stream的静态方法: of()、iterate()、generate()
Stream<String> stream1 = Stream.of("a", "b", "c");
Stream<String> stream2 = Stream.iterate("a", (x) -> x + "a").limit(4);
//stream2.forEach(System.out::println);
Stream<Double> stream3 = Stream.generate(Math::random).limit(3);
//stream3.forEach(System.out::println);
顺序流&并行流
Stream是顺序流,由主线程按顺序对流执行操作,而ParallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。
如果流中的数据量足够大,并行流可以加快处理速度。
除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流:
Optional<Integer> findFirst = list.stream().parallel().filter(x->x>6).findFirst();
Stream的使用
核心类Optional
Optional类是一个可以为null的容器对象,如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
遍历/匹配(foreach/find/match)
List<Integer> list = Arrays.asList(7,6,9,3,8,5,2,1,4);
//遍历输出符合条件的元素
list.stream().filter(x -> x > 6).forEach(System.out::println);
//匹配第一个
Optional<Integer> findFirst = list.stream().filter(x -> x > 6).findFirst();
System.out.println("匹配第一个值:" + findFirst.get());
//匹配任意(适用于并行流)
Optional<Integer> findAny = list.parallelStream().filter(x -> x > 6).findAny();
System.out.println("匹配任意一个值:" + findAny.get());
//是否包含符合特定条件的元素
boolean anyMatch = list.stream().anyMatch(x -> x > 6);
System.out.println("是否存在大于6的值:" + anyMatch);
结果输出:
7
9
8
匹配第一个值:7
匹配任意一个值:8
是否存在大于6的值:true
筛选(filter)
List<Integer> list = Arrays.asList(7,6,9,3,8,5,2,1,4);
//遍历输出符合条件的元素
list.stream().filter(x -> x > 6).forEach(System.out::println);
结果输出:
7
9
8
聚合(max/min/count)
List<String> list = Arrays.asList("admin", "winter", "test", "yfdyf", "supermarket");
Optional<String> max = list.stream().max(Comparator.comparing(String::length));
System.out.println("最长的字符串: " + max.get());
Optional<String> min = list.stream().min(Comparator.comparing(String::length));
System.out.println("最短的字符串: " + min.get());
long count = list.stream().filter(x -> x.length() > 5).count();
System.out.println("字符串长度大于5的个数: " + count);
结果输出:
最长的字符串: supermarket
最短的字符串: test
字符串长度大于5的个数: 2
映射(map/flatMap)
映射,可以将一个流的元素按照一定的映射规则映射到另一个流中。分为map和flatMap
-
map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
-
flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
List<String> list = Arrays.asList("admin", "winter", "test", "yfdyf", "supermarket");
List<String> strList = list.stream().map(String::toUpperCase).collect(Collectors.toList());
System.out.println("每个元素大写: " + strList);
List<String> list2 = Arrays.asList("a-d-m-i-n", "w-i-n-t-e-r", "t-e-s-t");
List<String> strList2 = list2.stream().flatMap(s -> {
//将每个元素转换成一个stream
String[] split = s.split("-");
Stream<String> s2 = Arrays.stream(split);
return s2;
}).collect(Collectors.toList());
System.out.println("处理前集合: " + list2);
System.out.println("处理后集合:" +strList2);
结果输出:
每个元素大写: [ADMIN, WINTER, TEST, YFDYF, SUPERMARKET]
处理前集合: [a-d-m-i-n, w-i-n-t-e-r, t-e-s-t]
处理后集合:[a, d, m, i, n, w, i, n, t, e, r, t, e, s, t]
归约(reduce)
归约,也称缩减,是把一个流缩减成一个值,能实现对集合求和,求乘积和求最值操作。
List<Integer> list = Arrays.asList(1, 3, 2, 8, 11, 4);
//求和方式1
Optional<Integer> sum = list.stream().reduce((x, y) -> x + y);
//求和方式2
Optional<Integer> sum2 = list.stream().reduce(Integer::sum);
//求和方式3
Integer sum3 = list.stream().reduce(0, Integer::sum);
System.out.println("list求和: " + sum.get() + "," + sum2.get() + "," + sum3);
//求乘积
Optional<Integer> product = list.stream().reduce((x, y) -> x * y);
System.out.println("list求积: " + product.get());
//求最大值方式1
Optional<Integer> max = list.stream().reduce((x, y) -> x > y ? x : y);
//求最大值方式2
Integer max2 = list.stream().reduce(1, Integer::max);
System.out.println("list求最大值: " + max.get() + "," + max2);
结果输出:
list求和: 29,29,29
list求积: 2112
list求最大值: 11,11
收集(collect)
//demo 员工类
@Data
public class Person{
private String name; //姓名
private int salary; //薪资
private int age; //年龄
private String sex; //性别
private String area; //地区
public Person(String name, int salary, int age, String sex, String area) {
this.name = name;
this.salary = salary;
this.age = age;
this.sex = sex;
this.area = area;
}
}
归集(toList/toSet/toMap)
List<Person> personList = new ArrayList<>();
personList.add(new Person("Spring", 9999, 28, "male", "Chang Sha"));
personList.add(new Person("Summer", 7777, 25, "female", "Hang Zhou"));
personList.add(new Person("Autumn", 6666, 23, "female", "Shang Hai"));
personList.add(new Person("Winter", 8888, 26, "male", "Chang Sha"));
List<String> list = personList.stream().filter(p -> p.getAge() > 24).map(Person::getArea).collect(Collectors.toList());
System.out.println("age > 24 return area toList: " + list);
Set<String> set = personList.stream().filter(p -> p.getAge() > 24).map(Person::getArea).collect(Collectors.toSet());
System.out.println("age > 24 return area toSet: " + set);
Map<?, Person> map = personList.stream().filter(p -> p.getSalary() > 8000).collect(Collectors.toMap(Person::getName, p -> p));
System.out.println("salary >8000 return personMap: " + map);
结果输出:
age > 24 return area toList: [Chang Sha, Hang Zhou, Chang Sha]
age > 24 return area toSet: [Chang Sha, Hang Zhou]
salary >8000 return personMap: {Winter=Person(name=Winter, salary=8888, age=26, sex=male, area=Chang Sha), Spring=Person(name=Spring, salary=9999, age=28, sex=male, area=Chang Sha)}
统计(count/averaging)
Collectors提供了一系列用于数据统计的静态方法
-
计数:count
-
平均值:averagingInt、averagingLong、averagingDouble
-
最值:maxBy、minBy
-
求和:summingInt、summingLong、summingDouble
-
统计以上所有:summarizingInt、summarizingLong、summarizingDouble
List<Person> personList = new ArrayList<>();
personList.add(new Person("Spring", 9999, 28, "male", "Chang Sha"));
personList.add(new Person("Summer", 7777, 25, "female", "Hang Zhou"));
personList.add(new Person("Autumn", 6666, 23, "female", "Shang Hai"));
personList.add(new Person("Winter", 8888, 26, "male", "Chang Sha"));
//求总数
Long count = personList.stream().collect(Collectors.counting());
//求平均工资
Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
//求最高工资
Optional<Integer> max = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare));
//求工资之和
Integer sum = personList.stream().collect(Collectors.summingInt(Person::getSalary));
// 一次性统计所有信息
DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
System.out.println("员工总数: " + count);
System.out.println("员工平均工资: " + average);
System.out.println("员工最高工资: " + max.get());
System.out.println("员工工资总和: " + sum);
System.out.println("员工工资所有统计: " + collect);
结果输出:
员工总数: 4
员工平均工资: 8332.5
员工最高工资: 9999
员工工资总和: 33330
员工工资所有统计: DoubleSummaryStatistics{count=4, sum=33330.000000, min=6666.000000, average=8332.500000, max=9999.000000}
分组(partitioningBy/groupingBy)
List<Person> personList = new ArrayList<>();
personList.add(new Person("Spring", 9999, 28, "male", "Chang Sha"));
personList.add(new Person("Summer", 7777, 25, "female", "Hang Zhou"));
personList.add(new Person("Autumn", 6666, 23, "female", "Shang Hai"));
personList.add(new Person("Winter", 8888, 26, "male", "Chang Sha"));
//将员工按薪资是否高于8000分组
Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));
System.out.println("员工按薪资是否大于8000 分组情况:" + part);
//将员工按性别分组
Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getArea));
System.out.println("员工按性别 分组情况:" + group);
// 将员工先按性别分组,再按地区分组
Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));
System.out.println("员工按性别、地区 分组情况: "+ group2);
结果输出:
员工按薪资是否大于8000 分组情况:{false=[Person(name=Summer, salary=7777, age=25, sex=female, area=Hang Zhou), Person(name=Autumn, salary=6666, age=23, sex=female, area=Shang Hai)], true=[Person(name=Spring, salary=9999, age=28, sex=male, area=Chang Sha), Person(name=Winter, salary=8888, age=26, sex=male, area=Chang Sha)]}
员工按性别 分组情况:{Chang Sha=[Person(name=Spring, salary=9999, age=28, sex=male, area=Chang Sha), Person(name=Winter, salary=8888, age=26, sex=male, area=Chang Sha)], Shang Hai=[Person(name=Autumn, salary=6666, age=23, sex=female, area=Shang Hai)], Hang Zhou=[Person(name=Summer, salary=7777, age=25, sex=female, area=Hang Zhou)]}
员工按性别、地区 分组情况: {female={Shang Hai=[Person(name=Autumn, salary=6666, age=23, sex=female, area=Shang Hai)], Hang Zhou=[Person(name=Summer, salary=7777, age=25, sex=female, area=Hang Zhou)]}, male={Chang Sha=[Person(name=Spring, salary=9999, age=28, sex=male, area=Chang Sha), Person(name=Winter, salary=8888, age=26, sex=male, area=Chang Sha)]}}
连接(joining)
List<String> list = Arrays.asList("A", "B", "C");
String string = list.stream().collect(Collectors.joining("-"));
System.out.println("拼接后的字符串:" + string);
结果输出:
拼接后的字符串:A-B-C
排序(sorted)
-
sorted():自然排序,流中的元素需实现Comparable接口
-
sorted(Comparator com):Comparator排序器自定义排序
List<Person> personList = new ArrayList<>();
personList.add(new Person("Spring", 9999, 28, "male", "Chang Sha"));
personList.add(new Person("Summer", 7777, 25, "female", "Hang Zhou"));
personList.add(new Person("Autumn", 6666, 23, "female", "Shang Hai"));
personList.add(new Person("Winter", 8888, 26, "male", "Chang Sha"));
//按工资升序(自然排序)
List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资升序排序: " + newList);
//按工资降序
List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed()).map(Person::getName).collect(Collectors.toList());
System.out.println("按工资降序排序: " + newList2);
//先按工资再按年龄升序排序
List<String> newList3 = personList.stream().sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName).collect(Collectors.toList());
System.out.println("先按工资再按年龄升序排序: " + newList3);
//先按工资再按年龄降序排序(自定义排序)
List<String> newList4 = personList.stream().sorted((p1, p2) -> {
if(p1.getSalary() == p2.getSalary()) {
return p2.getAge() - p1.getAge();
} else {
return p2.getSalary() - p1.getSalary();
}
}).map(Person::getName).collect(Collectors.toList());
System.out.println("先按工资再按年龄降序排序: " + newList4);
结果输出:
按工资升序排序: [Autumn, Summer, Winter, Spring]
按工资降序排序: [Spring, Winter, Summer, Autumn]
先按工资再按年龄升序排序: [Autumn, Summer, Winter, Spring]
先按工资再按年龄降序排序: [Spring, Winter, Summer, Autumn]
提取/组合(concat/distinct/limit/skip)
String[] arr1 = {"a", "b", "c", "d"};
String[] arr2 = {"d", "e", "f", "g"};
Stream<String> stream1 = Stream.of(arr1);
Stream<String> stream2 = Stream.of(arr2);
//合并两个流并去重
List<String> newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
System.out.println("流合并: " + newList);
//限制从流中获取前5个数据
List<String> collect = newList.stream().limit(5).collect(Collectors.toList());
System.out.println("从合并的流中取出前5个数据: " + collect);
//跳过前5个数据
List<String> collect2 = newList.stream().skip(5).collect(Collectors.toList());
System.out.println("从合并的流中跳过前5个数据:" + collect2);
结果输出:
流合并: [a, b, c, d, e, f, g]
从合并的流中取出前5个数据: [a, b, c, d, e]
从合并的流中跳过前5个数据:[f, g]
Stream源码解析
1. 基本介绍
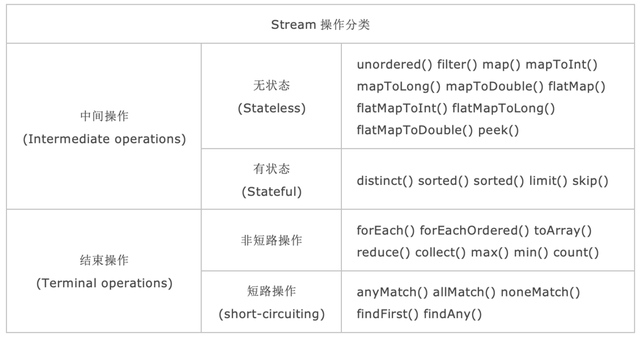
Stream中的操作可以分为两大类:中间操作(Intermediate operations)与结束操作(Terminal operations),中间操作只是对操作进行了记录,只有结束操作才会触发实际的计算(即惰性求值),这也是Stream在迭代大集合时高效的原因之一。中间操作又可以分为无状态(Stateless)操作与有状态(Stateful)操作,前者是指元素的处理不受之前元素的影响;后者是指该操作只有拿到所有元素之后才能继续下去。结束操作又可以分为短路(short-circuiting)与非短路操作,前者是指遇到某些符合条件的元素就可以得到最终结果;而后者是指必须处理所有元素才能得到最终结果。
之所以要进行如此精细的划分,是因为底层对每一种情况的处理方式不同。
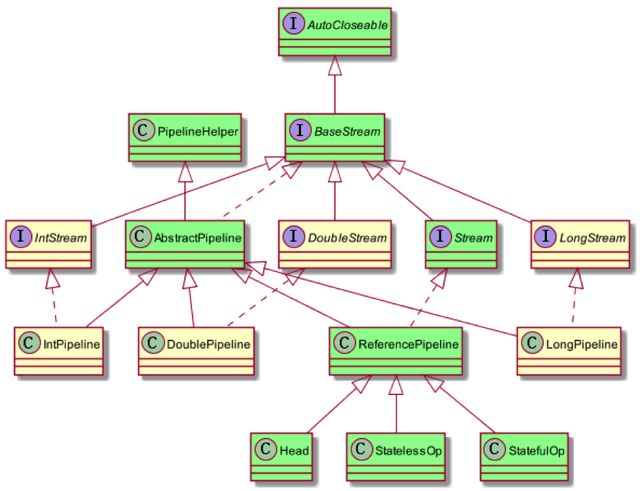
BaseStream:定义了流的迭代、并行、串行等基本特性
Stream:定义了map、filter、flatmap等用户关注的常用操作
PipelineHelper用于执行管道流中的操作以及捕获输出类型、并行度等信息
Head、StatelessOp、StatefulOp为ReferencePipeline中的内部子类,用于描述流的操作阶段
2. Stream()
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
//返回了一个由Head实现的Stream,三个参数分别代表流的数据源、特性组合、是否并行
return new ReferencePipeline.Head<>(spliterator, StreamOpFlag.fromCharacteristics(spliterator),parallel);
}
Head(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
ReferencePipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
ReferencePipeline.Head的构造方法为调用父类ReferencePipeline的构造方法,ReferencePipeline的构造方法又调用了父类AbstractPipeline的构造方法
AbstractPipeline
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
this.previousStage = null;//上一个stage指向null
this.sourceSpliterator = source;
this.sourceStage = this;//源头stage指向自己
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
此处构造函数,构造出了一个前一个节点为空,头节点指向自己,后一个节点暂未指定的双端链表。
即,stream函数返回了一个由类实现的管道流,且该管道流为一个双端链表,的头节点。
3. 无状态的中间操作(filter、map、flatmap等)
以filter为例
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
//入参不能为空
Objects.requireNonNull(predicate);
//构建了一个StatelessOp对象,即无状态的中间操作
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
//覆写了父类的opWrapSink方法
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
StatelessOp最终调用的构造方法和ReferencePipeline.Head调用的构造方法一致,都是调用的AbstractPipeline的构造方法,不过第一个参数传入的是this,也就是将上一步创建的对象传入,作为该构造对象的previousStage。
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
//previousStage的指针指向该创建对象
previousStage.nextStage = this;
//上一个stage指向上一步创建的对象
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;//源头stage与previousStage保持一致
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
再来看看map操作
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
可以看到与filter方法一样,都是创建了一个StagellessOp对象,重写了opWrapSink方法。
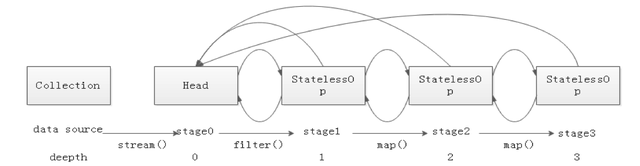
调用一系列中间操作后会形成如下所示的双链表结构:
4. 终结操作(collect等)
以collect为例
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) {
A container;
//并行模式
if (isParallel()
&& (collector.characteristics().contains(Collector.Characteristics.CONCURRENT))
&& (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {
container = collector.supplier().get();
BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator();
forEach(u -> accumulator.accept(container, u));
}
//串行模式
else {
container = evaluate(ReduceOps.makeRef(collector));
}
return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)
? (R) container
: collector.finisher().apply(container);
}
以串行模式为例,往下走
public static <T, I> TerminalOp<T, I>
makeRef(Collector<? super T, I, ?> collector) {
Supplier<I> supplier = Objects.requireNonNull(collector).supplier();
BiConsumer<I, ? super T> accumulator = collector.accumulator();
BinaryOperator<I> combiner = collector.combiner();
class ReducingSink extends Box<I>
implements AccumulatingSink<T, I, ReducingSink> {
@Override
public void begin(long size) {
state = supplier.get();
}
@Override
public void accept(T t) {
accumulator.accept(state, t);
}
@Override
public void combine(ReducingSink other) {
state = combiner.apply(state, other.state);
}
}
return new ReduceOp<T, I, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
@Override
public int getOpFlags() {
return collector.characteristics().contains(Collector.Characteristics.UNORDERED)
? StreamOpFlag.NOT_ORDERED
: 0;
}
};
}
ReduceOps.makeRef(collector)会构造一个TerminalOp对象,传入evaluate方法。
以串行模式为例,evaluate方法会调用TerminalOp.evaluateSequential方法,再调用
PipelineHelper.wrapAndCopyInto方法,最终调用AbstarctPipeline中的copyInto方法,最终实现流水线的启动。
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
//无短路操作
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());//通知开始遍历
spliterator.forEachRemaining(wrappedSink);//依次处理每个元素
wrappedSink.end();//通知结束遍历
}
//有短路操作
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
该方法从数据源Spliterator中获取元素,推入Sink进行处理,如果有短路操作,在每个元素处理后会通过Sink.cancellationRequested()判断是否立即返回。
总结:
前面的中间操作只是做了一系列的准备工作,并没有真正执行,真正的迭代是由结束操作来触发的。
5. Sink
Stream中使用Stage的概念来描述一个完整的操作,将具有先后顺序的各个Stage连到一起,就构成了整个流水线。
很多Stream操作会需要一个回调函数(Lambda表达式),因此一个完整的操作是<数据来源,操作,回调函数>构成的三元组。
stage只是解决了操作记录的问题,要想让流水线起到应有的作用我们需要一种将所有操作叠加到一起的方案。你可能会觉得这很简单,只需要从流水线的head开始依次执行每一步的操作(包括回调函数)就行了。这听起来似乎是可行的,但是你忽略了前面的Stage并不知道后面Stage到底执行了哪种操作,以及回调函数是哪种形式。换句话说,只有当前Stage本身才知道该如何执行自己包含的动作。这就需要有某种协议来协调相邻Stage之间的调用关系。
而通过上文的collect源码,可以推测,Sink将在Stream中扮演该角色。
interface Sink<T> extends Consumer<T> {
//开始遍历元素之前调用该方法,通知Sink做好准备,size代表要处理的元素总数,如果传入-1代表总数未知或者无限
default void begin(long size) {}
//所有元素遍历完成之后调用,通知Sink没有更多的元素了。
default void end() {}
//如果返回true,代表这个Sink不再接收任何数据
default boolean cancellationRequested() {
return false;
}
//还有一个继承自Consumer的方法,用于接收管道流中的数据
//void accept(T t);
...
}
注意上文collect源码中,collect操作在调用copyInto方法时,传入了一个名为wrappedSink的参数,就是一个Sink对象,由AbstractPipeline.wrapSink方法构造而来。
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for (@SuppressWarnings("rawtypes")
AbstractPipeline p = AbstractPipeline.this; p.depth > 0; p = p.previousStage) {
// 自本身stage开始,不断调用前一个stage的opWrapSink,直到头节点
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
onWrapSink()方法的作用是将当前操作与下游Sink结合成新的Sink,只要从流水线的最后一个Stage开始,不断调用上一个Stage的onWrapSink()方法直到头节点,就可以得到一个代表了流水线上所有操作的Sink。
而onWrapSink()方法,正是在上文中间操作中,重写的方法。
每个Stage都会将自己的操作封装到一个Sink里,前一个Stage只需调用后一个Stage的accept()方法即可,并不需要知道其内部是如何处理的。当然对于有状态的操作,Sink的begin()和end()方法也是必须实现的。比如Stream.sorted()
是一个有状态的中间操作,其对应的Sink.begin()方法可能会创建一个盛放结果的容器,而accept()方法负责将元素添加到该容器,最后end()负责对容器进行排序。对于短路操作,Sink.cancellationRequested()也是必须实现的,比如Stream.findFirst()是短路操作,只要找到一个元素,cancellationRequested()就应该返回true,以便调用者尽快结束查找。Sink的四个接口方法常常相互协作,共同完成计算任务。实际上Stream API内部实现的的本质,就是如何重载Sink的这四个接口方法。
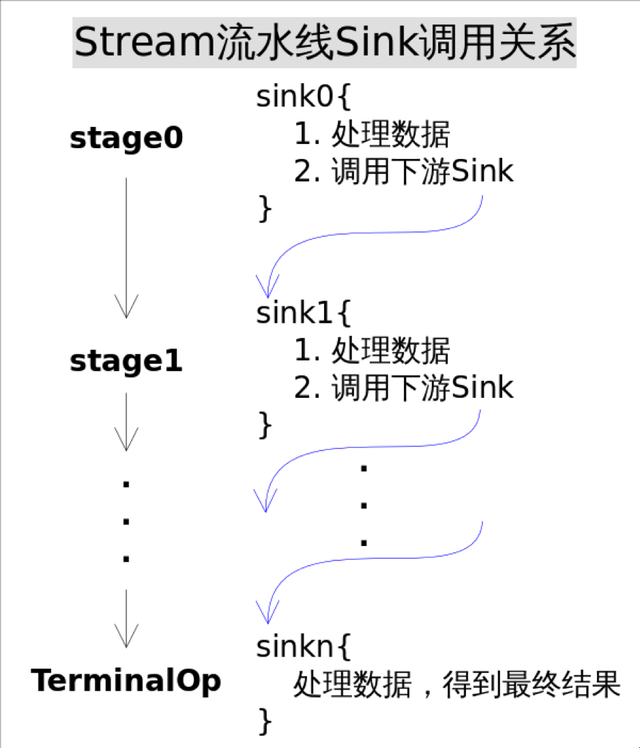
有了Sink对操作的包装,Stage之间的调用问题就解决了,执行时只需要从流水线的head开始对数据源依次调用每个Stage对应的Sink.{begin(), accept(), cancellationRequested(), end()}方法就可以了。
以sorted方法为例,sorted一种可能封装的Sink代码如下:
// Stream.sort()方法用到的Sink实现
class RefSortingSink<T> extends AbstractRefSortingSink<T> {
private ArrayList<T> list;// 存放用于排序的元素
RefSortingSink(Sink<? super T> downstream, Comparator<? super T> comparator) {
super(downstream, comparator);
}
@Override
public void begin(long size) {
...
// 创建一个存放排序元素的列表
list = (size >= 0) ? new ArrayList<T>((int) size) : new ArrayList<T>();
}
@Override
public void end() {
list.sort(comparator);// 只有元素全部接收之后才能开始排序
downstream.begin(list.size());
if (!cancellationWasRequested) {// 下游Sink不包含短路操作
list.forEach(downstream::accept);// 2. 将处理结果传递给流水线下游的Sink
} else {// 下游Sink包含短路操作
for (T t : list) {// 每次都调用cancellationRequested()询问是否可以结束处理。
if (downstream.cancellationRequested())
break;
downstream.accept(t);// 2. 将处理结果传递给流水线下游的Sink
}
}
downstream.end();
list = null;
}
@Override
public void accept(T t) {
list.add(t);// 1. 使用当前Sink包装动作处理t,只是简单的将元素添加到中间列表当中
}
}
上述代码完美的展现了Sink的四个接口方法是如何协同工作的:
begin():告诉Sink参与排序的元素个数,方便确定中间结果容器的大小
accept():将元素添加到中间结果当中,最终执行时调用者会不断调用该方法,直到遍历所有元素。
end():告诉Sink所有元素遍历完毕,启动排序步骤,排序完成后将结果传递给下游的Sink
如果下游Sink是短路操作,将结果传递给下游时不断询问下游cancellationRequested()是否可以结束处理。
6. 结果收集
流水线上所有操作都执行后,用户所需要的结果(如果有)在哪里?
首先要说明的是不是所有的Stream结束操作都需要返回结果,有些操作只是为了使用其副作用(Side-effects),比如使用Stream.forEach()方法将结果打印出来就是常见的使用副作用的场景(事实上,除了打印之外其他场景都应避免使用副作用),对于真正需要返回结果的结束操作结果存在哪里呢?这种需要分情况讨论:
对于返回boolean或者Optional的操作的操作,由于值返回一个值,只需要在对应的Sink中记录这个值,等到执行结束时返回就可以了。
对于归约操作,最终结果放在用户调用时指定的容器中(容器类型通过收集器指定)。collect(),reduce(),max(),min()都是归约操作,虽然max()和min()也是返回一个Optional,但事实上底层是通过调用reduce()方法实现的。
对于返回是数组的情况,在最终返回数组之前,结果其实是存储在一种叫做Node的数据结构中的。Node是一种多叉树结构,元素存储在树的叶子当中,并且一个叶子节点可以存放多个元素。这样做是为了并行执行方便。
7. 并行流
由上文可知,可通过parallel()方法,将顺序流转换成并行流。parallel()方法的实现很简单,只是将源stage的并行标记值设为true。在结束操作通过evaluate方法启动管道流时,会根据并行标记来判断。如果并行标记为true则会通过ReduceTask来执行并发任务。
public <P_IN> R evaluateParallel(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
ReduceTask是ForkJoinTask的子类,其实Stream的并行处理都是基于Fork/Join框架的,相关类与接口的结构如下图所示:
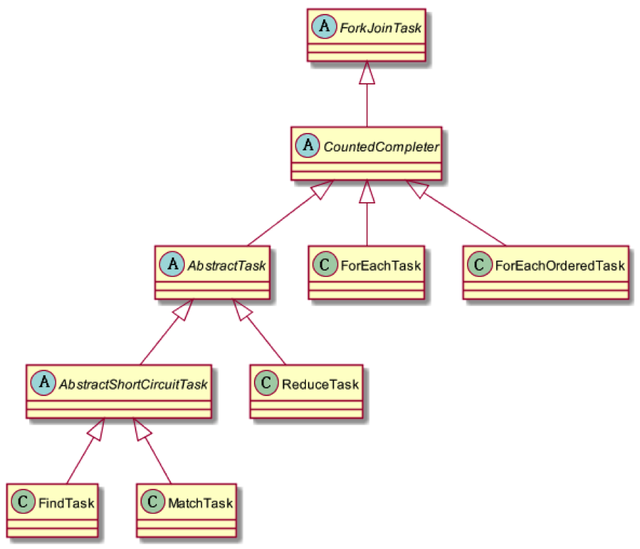
fork/join框架是jdk1.7引入的,可以以递归方式将并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。它是ExecutorService接口的一个实现,它把子任务分配线程池(ForkJoinPool)中的工作线程。要把任务提交到这个线程池,必须创建RecursiveTask
对于ReduceTask来说,任务分解的实现定义在其父类AbstractTask的compute()方法当中:
public void compute() {
Spliterator<P_IN> rs = spliterator, ls; // right, left spliterators
long sizeEstimate = rs.estimateSize();
long sizeThreshold = getTargetSize(sizeEstimate);
boolean forkRight = false;
@SuppressWarnings("unchecked") K task = (K) this;
while (sizeEstimate > sizeThreshold && (ls = rs.trySplit()) != null) {
K leftChild, rightChild, taskToFork;
task.leftChild = leftChild = task.makeChild(ls);
task.rightChild = rightChild = task.makeChild(rs);
task.setPendingCount(1);
if (forkRight) {
forkRight = false;
rs = ls;
task = leftChild;
taskToFork = rightChild;
}
else {
forkRight = true;
task = rightChild;
taskToFork = leftChild;
}
taskToFork.fork();
sizeEstimate = rs.estimateSize();
}
task.setLocalResult(task.doLeaf());
task.tryComplete();
}
该方法先调用当前splititerator 方法的estimateSize 方法,预估这个分片中的数据量,根据预估的数据量获取最小处理单元的阈值,即当数据量已经小于这个阈值的时候进行计算,否则进行fork 将任务划分成更小的数据块,进行求解。
这里面有个很重要的参数LEAF_TARGET,用来判断是否需要继续分割成更小的子任务,默认为parallelism*4(ForkJoinPool.getCommonPoolParallelism() << 2),parallelism是并发度的意思,默认值为cpu 数 – 1,可以通过java.util.concurrent.ForkJoinPool.common.parallelism设置, 如果当前分片大小仍然大于处理数据单元的阈值,且分片继续尝试切分成功,那么就继续切分,分别将左右分片的任务创建为新的Task,并且将当前的任务关联为两个新任务的父级任务(逻辑在makeChild 里面)。
先后对左右子节点的任务进行fork,对另外的分区进行分解。同时设定pending 为1,这代表一个task 实际上只会有一个等待的子节点(被fork)。当任务已经分解到足够小的时候退出循环,尝试进行结束。调用子类实现的doLeaf方法,完成最小计算单元的计算任务,并设置到当前任务的localResult中。
然后调用tryComplete方法进行最终任务的扫尾工作,如果该任务pending值不等于0,则原子的减1,如果已经等于0,说明任务都已经完成,则调用onCompletion回调,如果该任务是叶子任务,则直接销毁中间数据结束;如果是中间节点会将左右子节点的结果进行合并。
最后检查这个任务是否还有父级任务了,如果没有则将该任务置为正常结束,如果还有则尝试递归的去调用父级节点的onCompletion回调,逐级进行任务的合并。
并行流的实现本质上就是在ForkJoin上进行了一层封装,将Stream 不断尝试分解成更小的split,然后使用fork/join 框架分而治之。
参考资料
Java8 Stream:2万字20个实例,玩转集合的筛选、归约、分组、聚合
好文推荐:JAVA进阶之Stream实现原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号