
项目开发时,一般都会有到项目测试数据的准备操作,以前都是基于PHP代码自主编写sql语句,然后循环的插入到数据库中里面,当当我们接触过laravel数据库后,就可以很方便的完成项目的测试数据准备。
但在这个过程中计算用到laravel框架多少还是有有到问题,因为大家一般可能都是基于 php artisan db:seed 来进行数据填充,但随着项目的代码量越来越大,db:seed 的运行时间会变得越来越长,有些项目多达几分钟甚至几十分钟。
只有当 db:seed 运行起来很快的时候,才能完全利用数据填充工具带来的便利,而不是最后变成累赘。 所以今天我们分享到的内容就是面对大量假数据需要填充的时候我们应该如何来做到改善
方案一:
模型工厂
避免使用 create 方法
在使用 模型工厂函数 来书写假数据插入逻辑时,要注意避免使用 create 方法,因为每一次就是一条 SQL 语句。
factory(\App\Models\User::class)->times(300)->create();以下截图是一个使用 factory 辅助函数的例子,插入 300 条数据,总共执行了 602 条 SQL 语句,总执行时长为 23.91 秒。
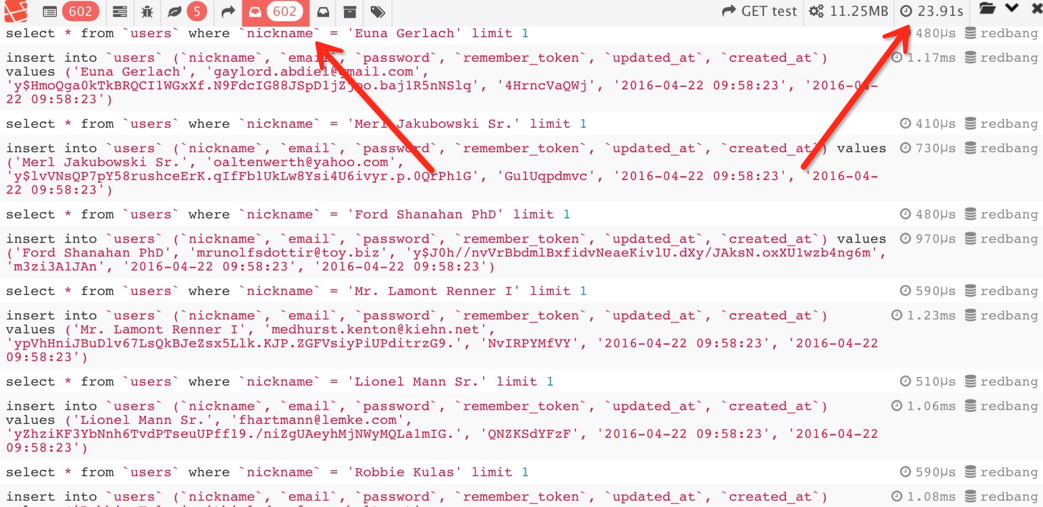
轻轻松松运行时间就累积起来了,你能想象运行一次
db:seed 要半个小时是什么感觉么?通过上图大家可以发现每天插入都会查询一遍然后在做一次添加,也就是大量测试数据添加的时候,我们对于数据库的IO操作非常的多,一般在面对大量的测试数据时,都是基于把单条的插入转化为批量的数据插入。进而提升到数据填充时间
正确的做法:使用 make 方法,在make里面方法里创建模型但不会将它们保存至数据库
$users = factory(\App\Models\User::class)->times(1000)->make();
\App\Models\User::insert($users->toArray());
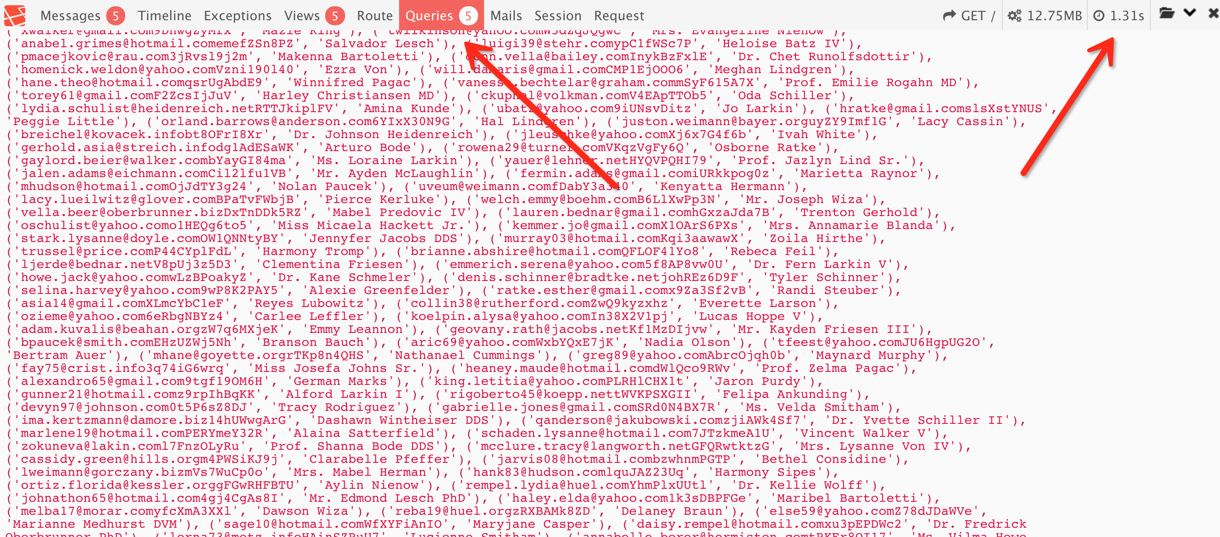
普通方式
使用 DB:insert,直接,快速,一步到位: $faker = Faker::create(); $users = User::lists('id'); $datas = []; foreach (range(1, 1000) as $index) { $datas[] = [ 'user_id' => $faker->randomElement($users), 'title' => $faker->sentence(), 'description' => $faker->text(), 'created_at' => Carbon::now()->toDateTimeString(), 'updated_at' => Carbon::now()->toDateTimeString(), ]; } DB::table('topics')->insert($datas);
只有 db:seed 运行起来很快的时候,你才可以随时随地,想 seed 就 seed。 看看源码,看看流程你就知道啦。
想要详细的获取测试源码、交流项目开发的技术问题。可以加入技术交流群进行探讨


 浙公网安备 33010602011771号
浙公网安备 33010602011771号