python爬虫笔记——学习笔记—6
爬虫笔记——学习笔记—6
1.安装scrapy
打开此电脑

在桌面的上栏目输入cmd并打开
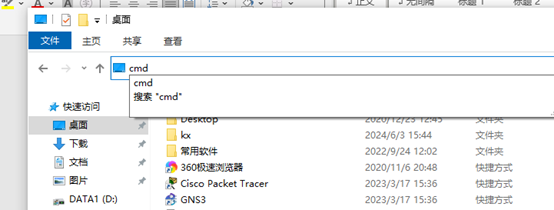
再命令框中升级python:python -m pip install –upgradepip
安装scrapy : pip install scrapy
安装完成后验证是否成功:scrapy -h

2.创建项目
继续创建项目:scrapy startproject +项目名

在终里面创建三个三方库:

在终端里面输入scrapy genspider 名称 网址

打开pycharm并添加本地解释器:
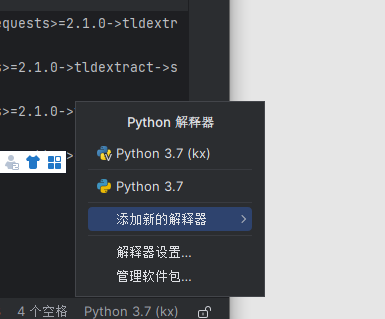
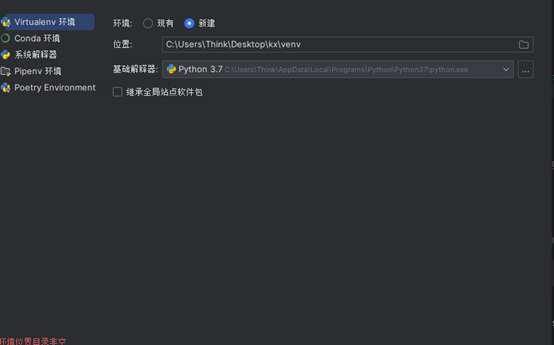
再sattings中添加UA欺骗

3.实现对豆瓣读书Top250榜单书名的爬取
在创建的book1中输入以下代码:
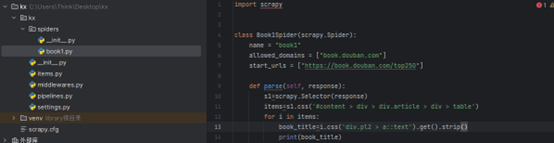
实现翻页代码:
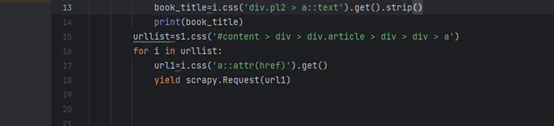
实现对所有的爬取
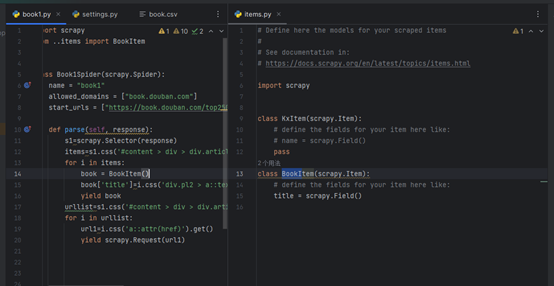
运行

结果
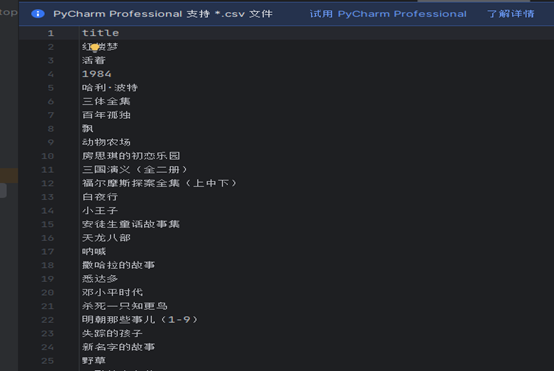
4.实现对电影名的爬取:
创建movie项目
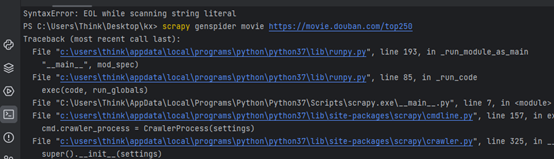
实现对所有的爬取
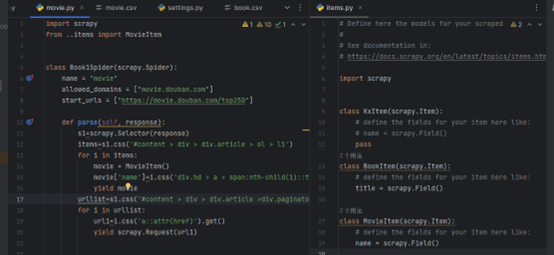
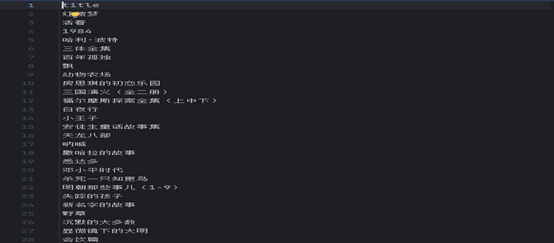
运行

结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号