python爬虫—学习笔记-2
python爬虫—学习笔记-2
ps:因为本人近一个月住院,文章为队友所著。
任务
获取豆瓣网站内容。
单页获取
网址:https://movie.douban.com/top250
获取网页信息
代码:
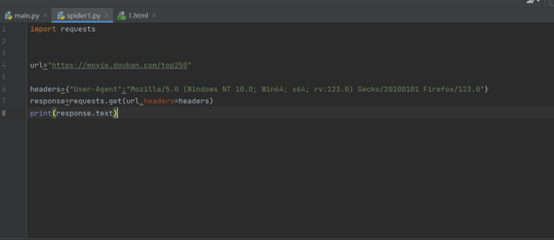
import requests
url="https://movie.douban.com/top250"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:123.0) Gecko/20100101 Firefox/123.0"}
response=requests.get(url,headers=headers)
print(response.text)
为了方便查看,获取的代码创建一个html网页放进其中。
获取第一页的电影名字
电影名字包含在
<span class="title">([^ ].*?)</span>
这个标签之中,所以需要
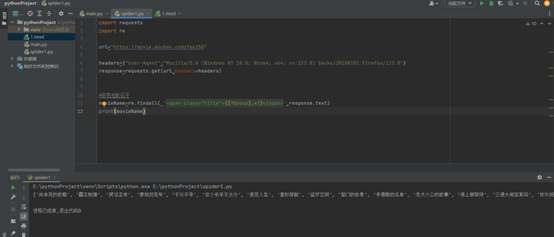
import requests
import re
url="https://movie.douban.com/top250"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:123.0) Gecko/20100101 Firefox/123.0"}
response=requests.get(url,headers=headers)
#获取电影名字
movieName=re.findall( '<span class="title">([^ ].*?)</span>',response.text)
print(movieName)
#^:意为除了
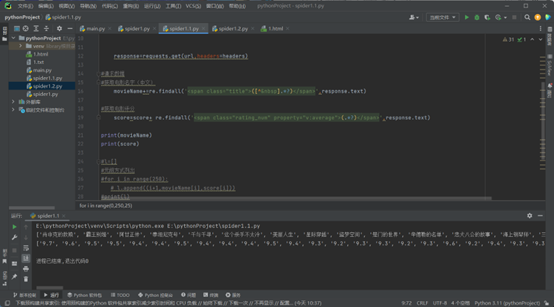
将电影名字与评分联系起来
多页获取
构建url
首页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
………………
最后一页:https://movie.douban.com/top250?start=250&filter=
可以看出其中存在一些关系
‘https://movie.douban.com/top250?start=‘+25的倍数+‘&filter= ’
所以url可以这样构建
url="https://movie.douban.com/top250?start=" + str(i) + "&filter="
import requests
import re
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}
movieName=[]
score=[]
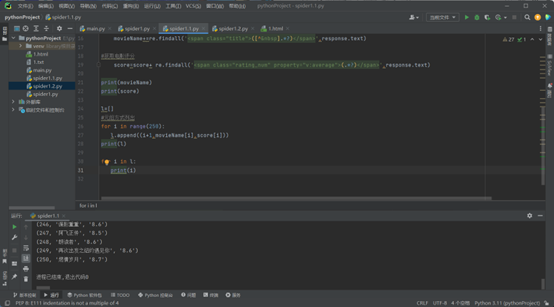
for i in range(0,250,25):
url="https://movie.douban.com/top250?start=" + str(i) + "&filter="
response=requests.get(url,headers=headers)
movieName+=re.findall('<span class="title">([^ ].*?)</span>',response.text)
score=score+ re.findall('<span class="rating_num" property="v:average">(.*?)</span>',response.text)
print(movieName)
print(score)
l=[]
for i in range(250):
l.append((i+1,movieName[i],score[i]))
print(l)
for i in l:
print(i)
import requests
import re
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0"}
movieName=[]
score=[]
for i in range(0,250,25):
url="https://movie.douban.com/top250?start=" + str(i) + "&filter="
response=requests.get(url,headers=headers)
movieName+=re.findall('<span class="title">([^ ].*?)</span>',response.text)
score=score+ re.findall('<span class="rating_num" property="v:average">(.*?)</span>',response.text)
print(movieName)
print(score)
l=[]
for i in range(250):
l.append((i+1,movieName[i],score[i]))
print(l)
for i in l:
print(i)
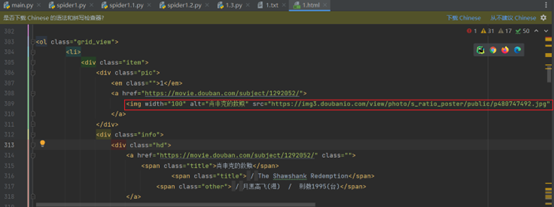
获取网页图片
首先找到图片所在的标签
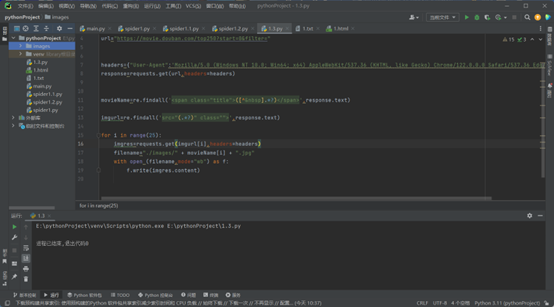
import requests
import re
url="https://movie.douban.com/top250?start=0&filter="
headers={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
response=requests.get(url,headers=headers)
movieName=re.findall('<span class="title">([^ ].*?)</span>',response.text)
imgurl=re.findall('src="(.*?)" class="">',response.text)
for i in range(25):
imgres=requests.get(imgurl[i],headers=headers)
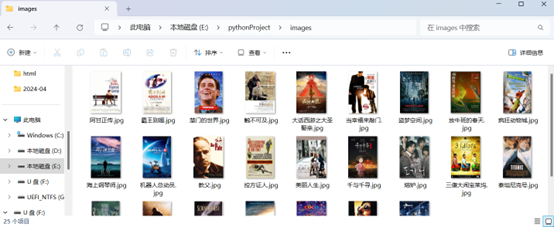
filename="./images/" + movieName[i] + ".jpg"
with open (filename,mode="wb") as f:
f.write(imgres.content)
注意:
获取图片时不应太平频繁 , 可以的话适当加上一个获取时间间隔 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号