python爬虫—学习笔记-1
python爬虫—学习笔记-1
ps:因为本人刚开始学习爬虫,这里是作为本人的学习笔记,见谅!
课前准备
下载模块
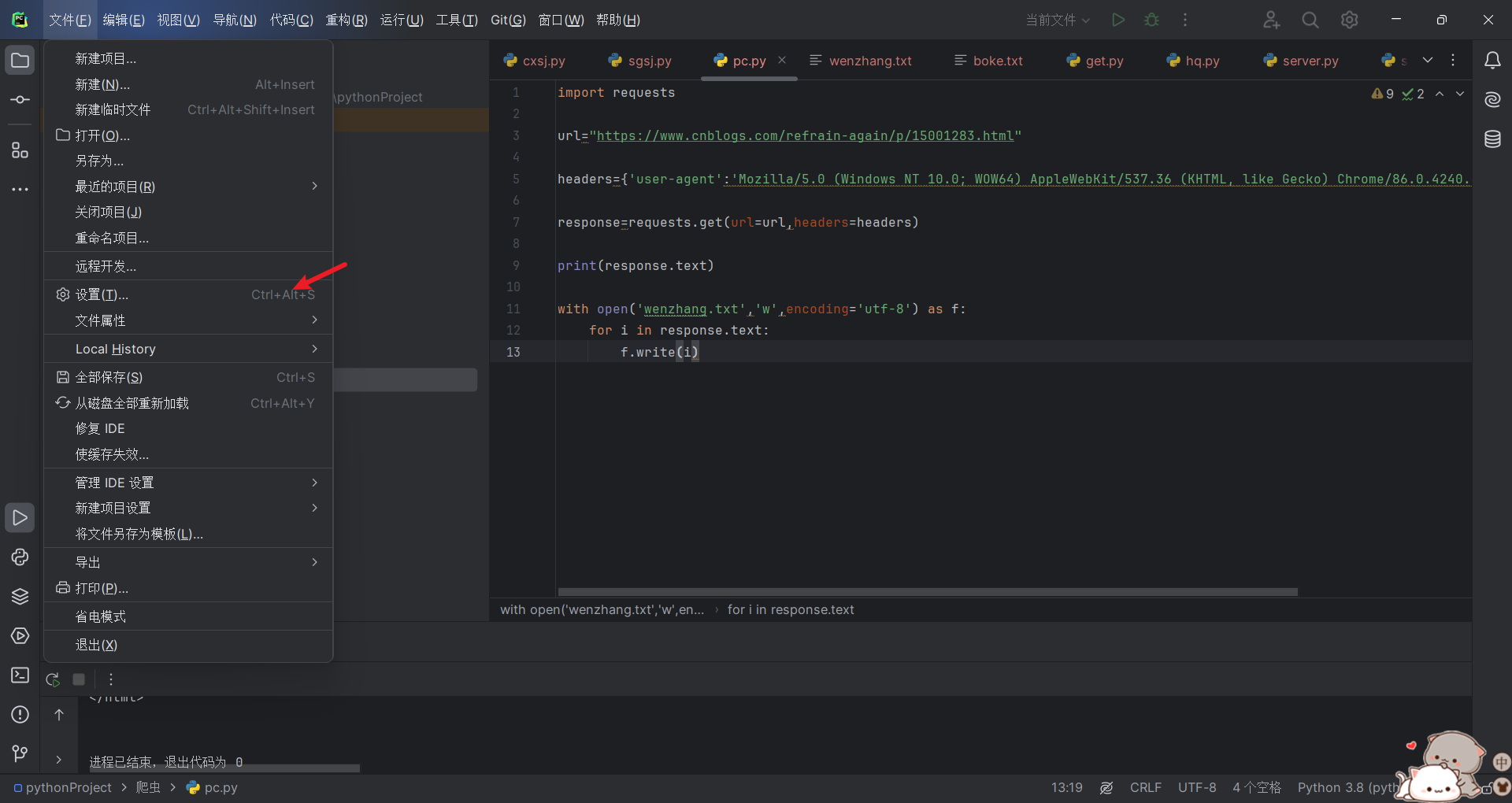
首先进入pycharm 点击设置
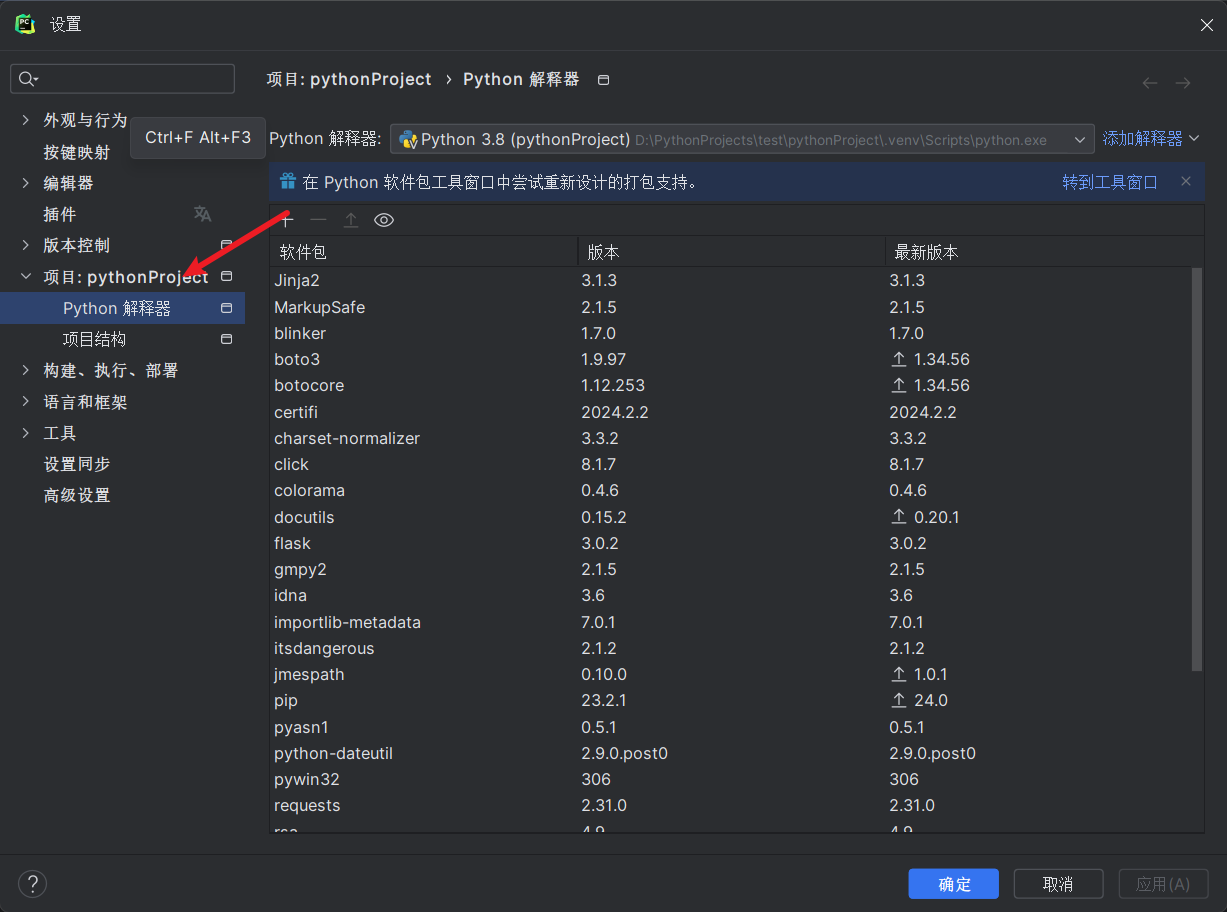
选择项目然后点击python解释器
点击加号下载requests模块和urllib3模块
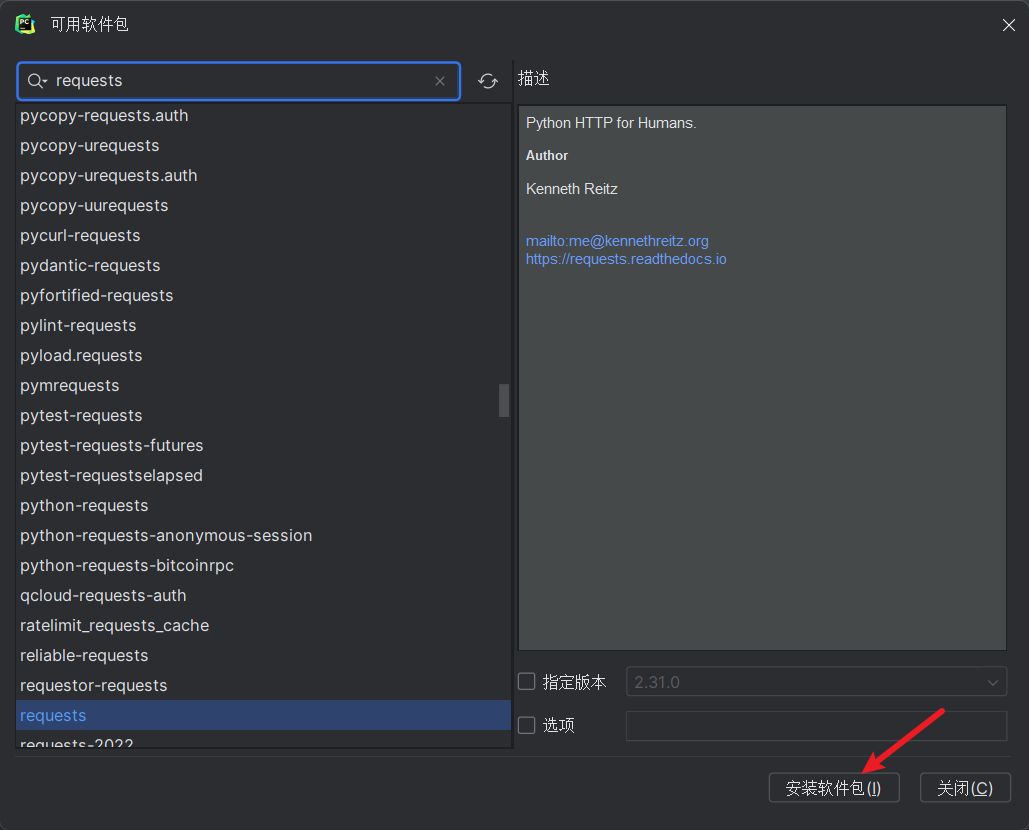
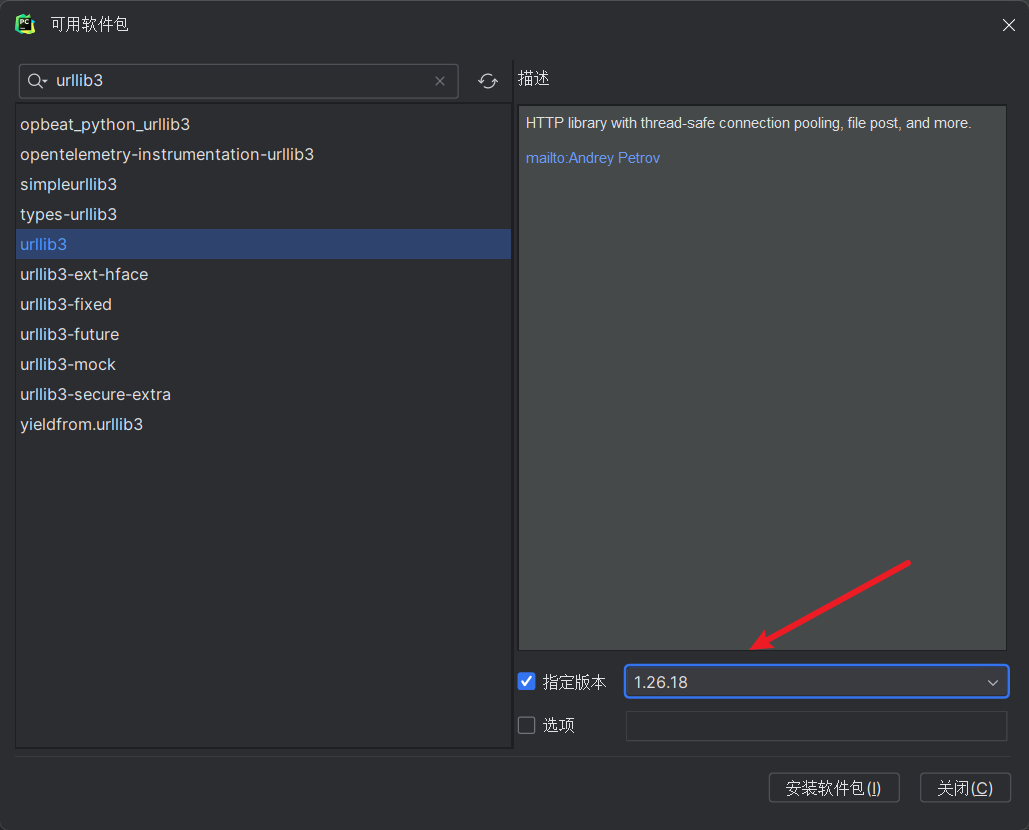
因为urllib3模块需要制定版本这里选择1.26.18版本下载。
试爬百度
创建一个python文档—>spider
首先引用requests模块,因为下文还没有使用所以没有高亮显示
import requests
这里先介绍一下下面使用到的名词的意思:
url:URL 代表着是统一资源定位符(Uniform Resource Locator)。URL 无非就是一个给定的独特资源在 Web 上的地址。理论上说,每个有效的 URL 都指向一个唯一的资源。这个资源可以是一个 HTML 页面,一个 CSS 文档,一幅图像,等等。
requests:响应。requests是一个Python第三方库,用于发送HTTP请求。
response:回答,应答。在Python中使用requests库发送HTTP请求并获取response
进入正文代码:
url = 'https://www.baidu.com/'
response=requests.get(url=url)
print(response.text)
爬下来后会发现编码格式有问题,并且文案也没有换行

这里有两种解决方案:
1.修改编码格式;
2.使用UA欺骗(user-agent伪造)
这里介绍第二种:
首先来到网页,F12使用管理员工具,选择网络,找到第一个网址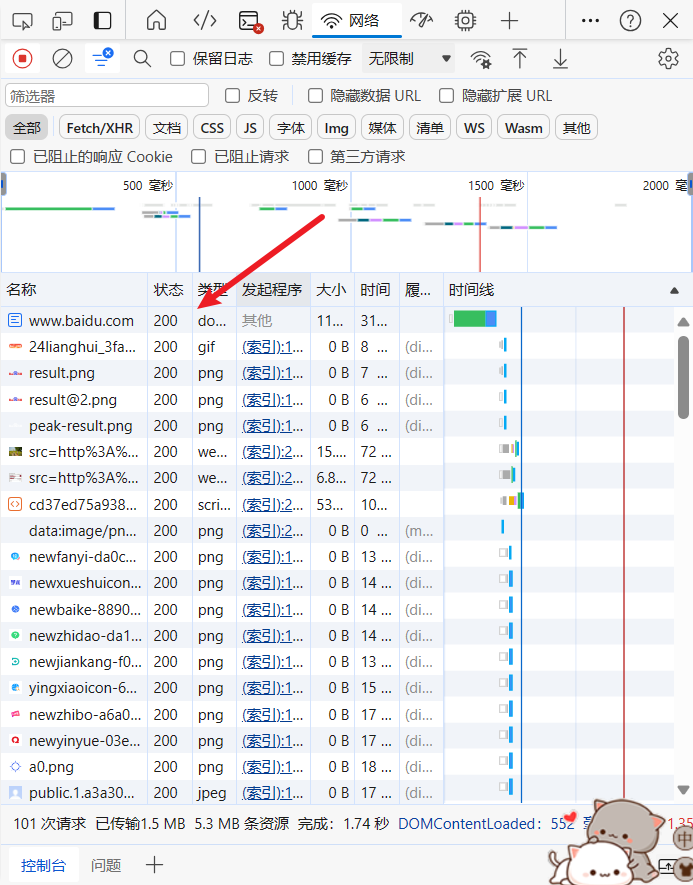
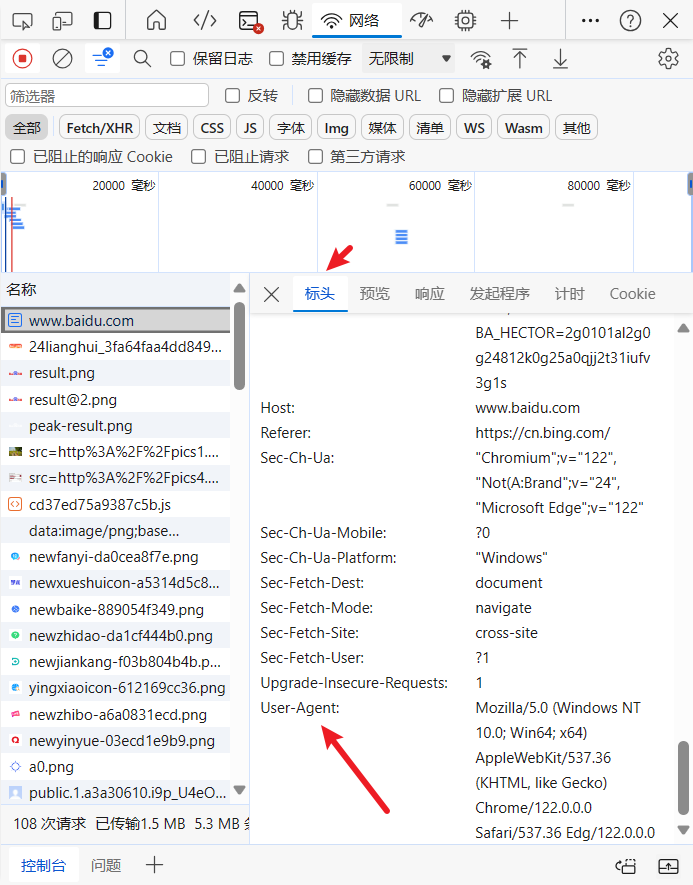
单机选择标头,找到user-agent
添加到代码
import requests
url = 'https://www.baidu.com/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
response=requests.get(url=url,headers=headers)
print(response.text)
这里补充一下字典:
字典(dict):字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值key:value对用冒号: 分割,每个键值对之间用逗号,分割,整个字典包括在花括号{}中,格式如下;
d = {key1 : value1, key2 : value2}
dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict。
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
这样我们就爬取到了百度网页。
那么怎么爬取我需要的文字呢?
我们来到刚爬取到的内容出 ctrl+f搜索***
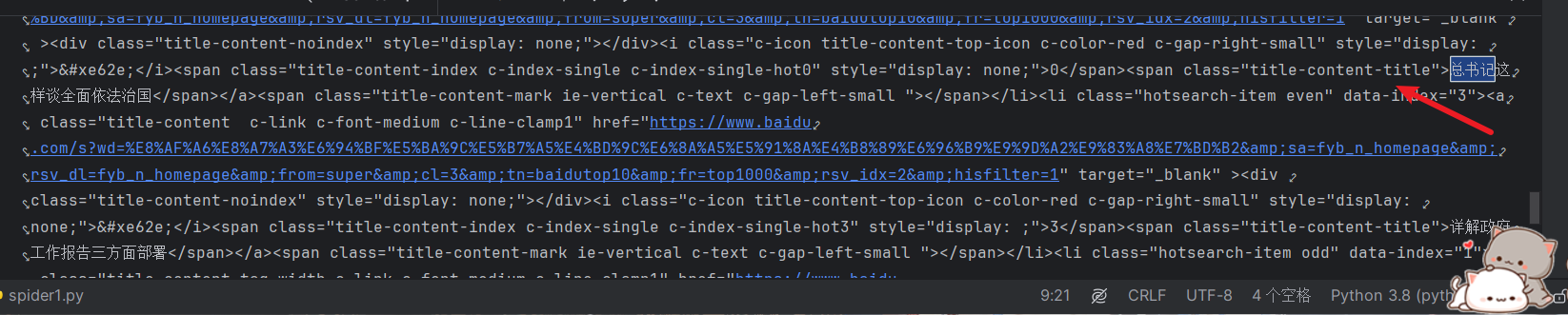
我们先将这句代码copy下来
然后我们需要用到正则表达式,以及正则表达式的模块 re
import requests
import re
url = 'https://www.baidu.com/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
response=requests.get(url=url,headers=headers)
t=re.findall('<span class="title-content-title">(.*?)</span>',response.text)
#这里用到了我们刚copy的代码 将中间的文字换做正则表达式的(.*?)
#“.*?” 表示非贪心算法,表示要精确的配对。 网上就找到这个解释-.-
下面我们将刚爬取到的文字放入一个记事本中,
#我们打开一个记事本,例如test.txt,指定写入 write 'w' , 编码格式指定utf-8
with open('test.txt','w',encoding='utf-8') as f:
for i in t:
f.write(i)
f.write("\n")
#这里\n代表换行
这里总汇一下
import requests
import re
url='https://www.baidu.com/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0'}
response=requests.get(url=url,headers=headers)
#print(response.text)
t=re.findall('<span class="title-content-title">(.*?)</span>',response.text)
print(t)
with open('test.txt','w',encoding='utf-8') as f:
for i in t:
f.write(i)
f.write("\n")
最后我们爬取到的文案:
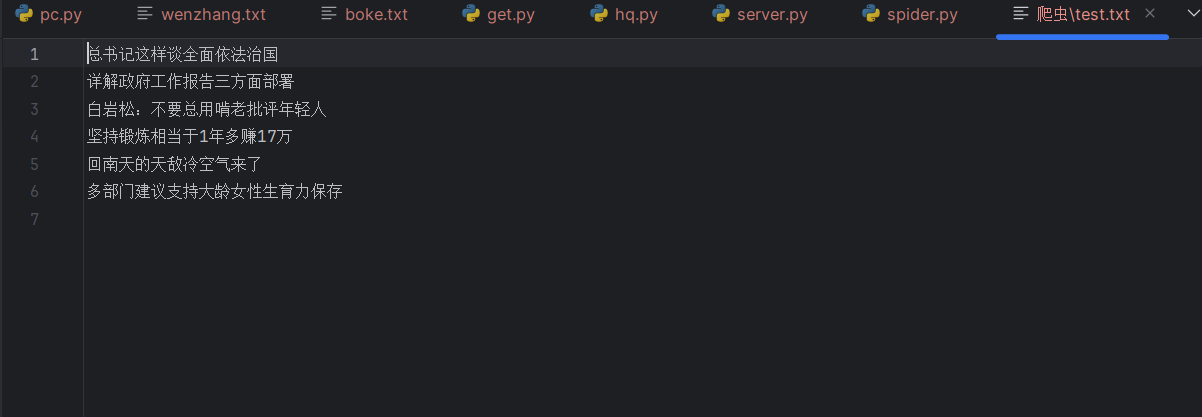
感谢观看,如有错误请指正,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号