kafka学习笔记
初识 Kafka
什么是 Kafka
Kafka 是由 Linkedin 公司开发的,它是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统(类似于NSQ)。
Kafka 的基本术语
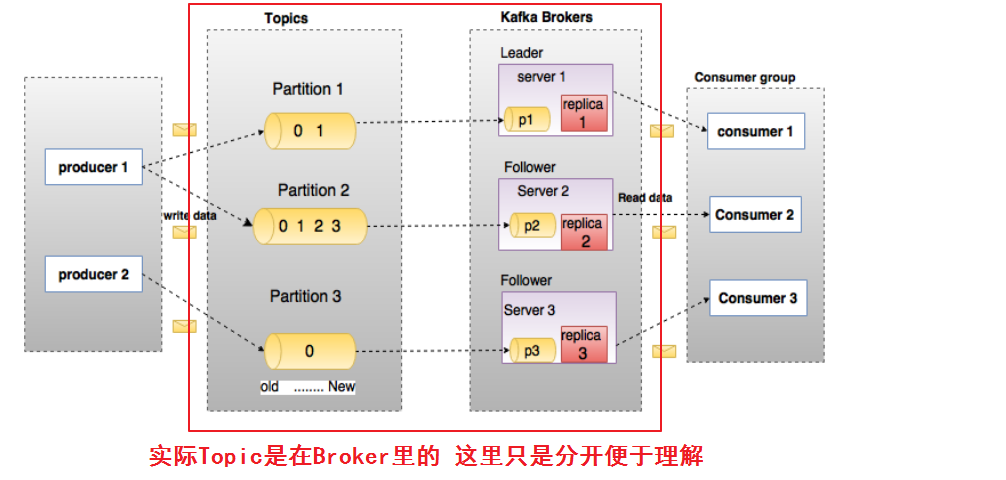
- 消息:Kafka 中的数据单元被称为消息,也被称为记录,可以把它看作数据库表中某一行的记录。
- 批次:为了提高效率, 消息会分批次写入 Kafka,批次就代指的是一组消息。
- 主题:消息的种类称为 主题(Topic),可以说一个主题代表了一类消息。相当于是对消息进行分类。主题就像是数据库中的表(例如web相关的可以设置肢体为“web_log”)。Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里
- 分区:主题可以被分为若干个分区(partition),同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性,单一主题中的分区有序,但是无法保证主题中所有的分区有序。(就是把一个主题的文件分成多少份。)
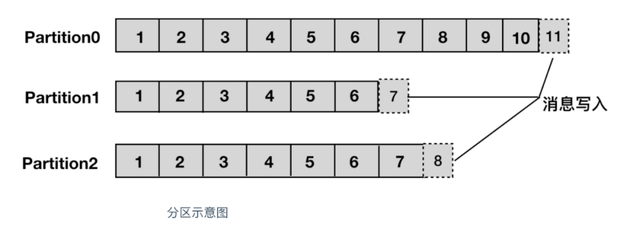
-
生产者:向主题发布消息的客户端应用程序称为生产者(Producer),生产者用于持续不断的向某个主题发送消息。
-
消费者:订阅主题消息的客户端程序称为消费者(Consumer),消费者用于处理生产者产生的消息。
-
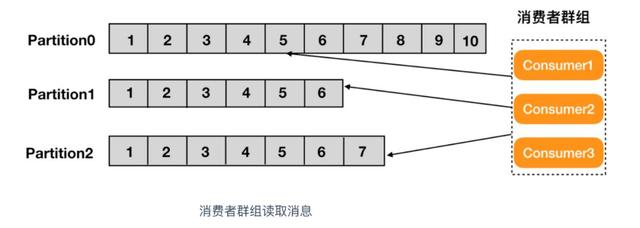
消费者群组:生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者,消费者群组(Consumer Group)指的就是由一个或多个消费者组成的群
-
偏移量:偏移量(Consumer Offset)是一种元数据,它是一个不断递增的整数值,用来记录消费者发生重平衡时的位置,以便用来恢复数据。
-
broker: 一个独立的 Kafka 服务器就被称为 broker,broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
-
broker 集群:broker 是集群 的组成部分,broker 集群由一个或多个 broker 组成,每个集群都有一个 broker 同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。
-
副本:Kafka 中消息的备份又叫做 副本(Replica),副本的数量是可以配置的,Kafka 定义了两类副本:领导者副本(Leader Replica) 和 追随者副本(Follower Replica),前者对外提供服务,后者只是被动跟随。
-
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
Kafka 的特性(设计原则)
- 高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒;
- 高伸缩性:每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中;
- 持久性、可靠性:Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 我们知道它的数据能够持久存储;
- 容错性:允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作;
- 高并发:支持数千个客户端同时读写
Kafka 的使用场景
- 活动跟踪:Kafka 可以用来跟踪用户行为,比如我们经常回去淘宝购物,你打开淘宝的那一刻,你的登陆信息,登陆次数都会作为消息传输到 Kafka ,当你浏览购物的时候,你的浏览信息,你的搜索指数,你的购物爱好都会作为一个个消息传递给 Kafka ,这样就可以生成报告,可以做智能推荐,购买喜好等;
- 传递消息:Kafka 另外一个基本用途是传递消息,应用程序向用户发送通知就是通过传递消息来实现的,这些应用组件可以生成消息,而不需要关心消息的格式,也不需要关心消息是如何发送的;
- 度量指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
- 日志记录:Kafka 的基本概念来源于提交日志,比如我们可以把数据库的更新发送到 Kafka 上,用来记录数据库的更新时间,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等;
- 流式处理:流式处理是有一个能够提供多种应用程序的领域;
- 限流削峰:Kafka 多用于互联网领域某一时刻请求特别多的情况下,可以把请求写入Kafka 中,避免直接请求后端程序导致服务崩溃。
- 异步处理: 很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
Kafka 的消息队列
Kafka 的消息队列一般分为两种模式:点对点模式和发布订阅模式

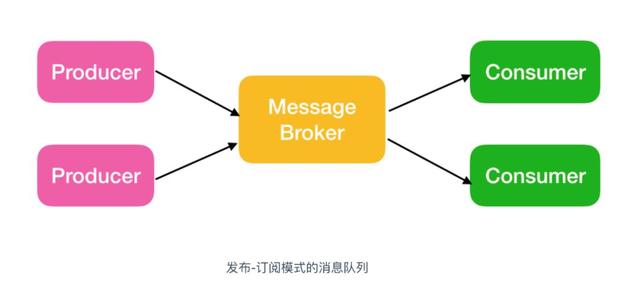
Kafka 系统架构

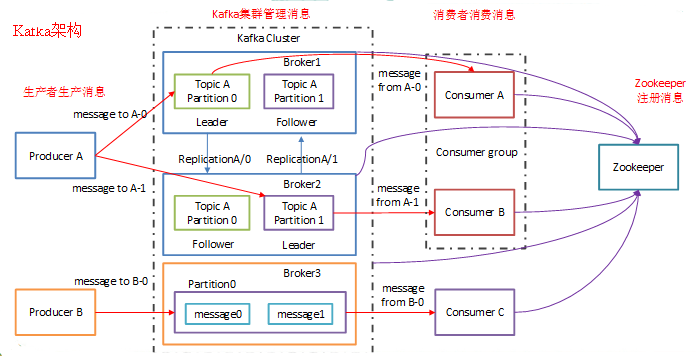
简单总结一下就是,每个topic会分为不同的partition(在集群中这可以提升系统吞吐量,因为不同的partition可以存储在不同节点),然后美个partition为了实现高可用会在不同的节点建立副本,并且之间会选举出leader和follower。
Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
Kafka的生产者和消费者相对于服务器端而言都是客户端。
Kafka Producer
kafka写入数据过程
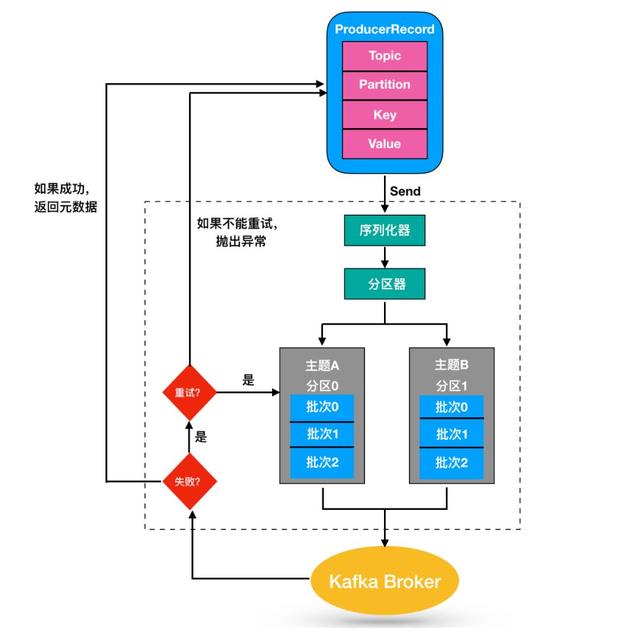
partition的选择策略
kafka的消息生产是有确认机制的,其次消息的发送到哪个分区的方式也是多样的,上面只是其中一种情况,这里也顺便讲讲生产者的分区策略:(分区原因,提高并行 和可扩展)
默认的分区策略有三种:
- 指定哪个分区
- 不指定分区,带有消息key.那么根据key的hash值对分区数取余得到分区去向
- 啥都不指定,默认随机生成一个小于分区数的值保存,每进一个消息就按保存的值+1进行分区分配 达到最高值开始轮询
kafka的副本同步策略
那么生产者数据可靠性的保证又是如何进行的呢,这里就讲下消息的可靠性保证,
在kafka中,生产者与kafka直接是存在ack确认的,类似我们的tcp三次握手,这里类比只进行一次握手来确认消息已经发送到kafka了,即生产者发送消息到kafka,kafka的leader将会返回一个Ack来告诉生产者消息已经到了,如果生产者没有接受到ack,则过一段时间,生产者会重新发送来确保消息有效。
那么Leader什么时候返回这个ack呢,这里又设计到kafka的副本同步策略,这里也粗略将一下
常见的副本同步策略一般来说有两种,
1:确保集群中半数以上的设备已经同步完成 就默认同步完成。 即你要保证有n台有效 你至少得准备2n+1台设备
2:确保集群中所有的设备已经同步完成,才默认同步完成。 即你要保证有n台失效时有效,你至少得准备n+1台
由于成本原因,kafka默认选的第一中方案,但是由于某种故障,方案2中若n台副本同步过程中,有一台挂掉了,那么久会造成其永远达不到同步的条件。所以kafka这里又有了ISR(同步副本)分区同步策略。
Leader什么时候返回这个ack呢?
ack确认方式:(配置文件中可以设置值来指定使用哪种 0-第一种 1-第二种 -1-第三种)
- leader收到消息就返回ack,数据还未保存---缺陷:若leader挂了,就基本丢失数据了,但速度较快
- leader收到消息并且写入了,即leader有一份后返回ack---缺陷:若leader挂了,并且还未同步副本,也容易丢失数据,速度一般
- leader等待副本同步完成后返回ack---缺陷:若速度最慢,但是保证了数据的可靠性,但有可能造成数据重复
(数据重复情况:若leader和副本已经同步,但ack还未返回,此时leader挂了,新的leder选举出来后又收到生产者重复的消息)
那么至此生产者的分区策略大概就是这样了,生产者通过分区策略来保障数据的可靠性
Consumer Group
使用Consumer high level API时,同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
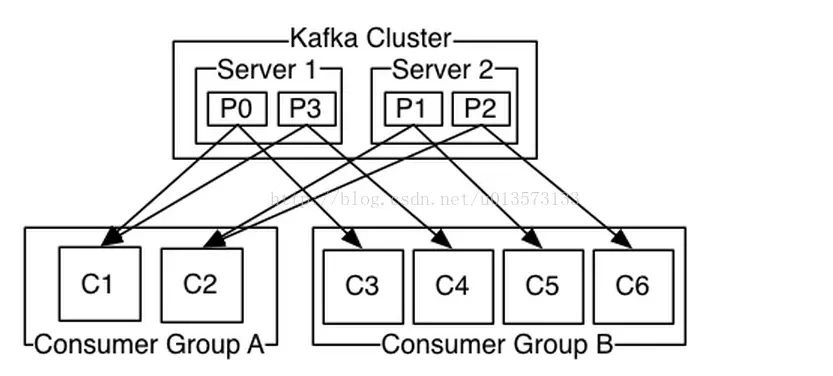
Kafka的设计理念之一就是同时提供离线处理和实时处理。根据这一特性,可以使用Storm这种实时流处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理,还可以同时将数据实时备份到另一个数据中心,只需要保证这三个操作所使用的Consumer属于不同的Consumer Group即可。
消费者的再平衡
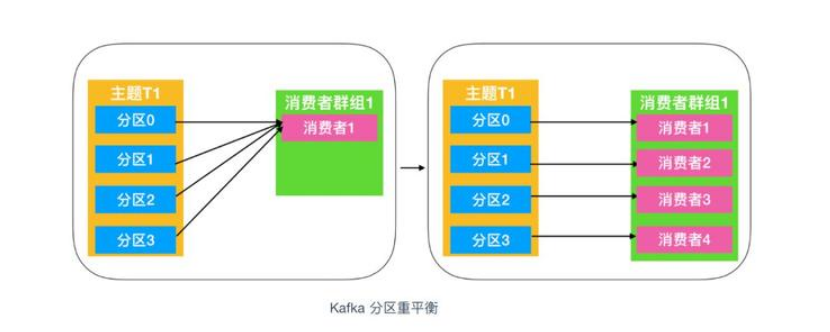
重平衡非常重要,它为消费者群组带来了高可用性 和 伸缩性,我们可以放心的添加消费者或移除消费者,不过在正常情况下我们并不希望发生这样的行为。在重平衡期间,消费者无法读取消息,造成整个消费者组在重平衡的期间都不可用。另外,当分区被重新分配给另一个消费者时,消息当前的读取状态会丢失,它有可能还需要去刷新缓存,在它重新恢复状态之前会拖慢应用程序。
FAQ
kafka为什么速度如此之快?
Kafka 实现了零拷贝原理来快速移动数据,避免了内核之间的切换。Kafka 可以将数据记录分批发送,从生产者到文件系统(Kafka 主题日志)到消费者,可以端到端的查看这些批次的数据。
批处理能够进行更有效的数据压缩并减少 I/O 延迟,Kafka 采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费,更多关于磁盘寻址的了解,请参阅 程序员需要了解的硬核知识之磁盘 。
总结一下其实就是四个要点:
- 顺序读写;
- 零拷贝;
- 消息压缩;
- 分批发送。
kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证, 其次采用的零拷贝技术直接将文件管理交予操作系统也是性能较高的一个原因)。
go语言操作kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有高性能、持久化、多副本备份、横向扩展等特点。本文介绍了如何使用Go语言发送和接收kafka消息。
sarama
Go语言中连接kafka使用第三方库:github.com/Shopify/sarama。
下载及安装
go get github.com/Shopify/sarama
注意事项
sarama v1.20之后的版本加入了zstd压缩算法,需要用到cgo,在Windows平台编译时会提示类似如下错误:
Copy# github.com/DataDog/zstd
exec: "gcc":executable file not found in %PATH%
所以在Windows平台请使用v1.19版本的sarama。
连接kafka发送消息
package main
import (
"fmt"
"github.com/Shopify/sarama"
)
// 基于sarama第三方库开发的kafka client
func main() {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // 发送完数据需要leader和follow都确认
config.Producer.Partitioner = sarama.NewRandomPartitioner // 新选出一个partition
config.Producer.Return.Successes = true // 成功交付的消息将在success channel返回
// 构造一个消息
msg := &sarama.ProducerMessage{}
msg.Topic = "web_log"
msg.Value = sarama.StringEncoder("this is a test log")
// 连接kafka
client, err := sarama.NewSyncProducer([]string{"192.168.1.7:9092"}, config)
if err != nil {
fmt.Println("producer closed, err:", err)
return
}
defer client.Close()
// 发送消息
pid, offset, err := client.SendMessage(msg)
if err != nil {
fmt.Println("send msg failed, err:", err)
return
}
fmt.Printf("pid:%v offset:%v\n", pid, offset)
}
连接kafka消费消息
package main
import (
"fmt"
"github.com/Shopify/sarama"
)
// kafka consumer
func main() {
consumer, err := sarama.NewConsumer([]string{"127.0.0.1:9092"}, nil)
if err != nil {
fmt.Printf("fail to start consumer, err:%v\n", err)
return
}
partitionList, err := consumer.Partitions("web_log") // 根据topic取到所有的分区
if err != nil {
fmt.Printf("fail to get list of partition:err%v\n", err)
return
}
fmt.Println(partitionList)
for partition := range partitionList { // 遍历所有的分区
// 针对每个分区创建一个对应的分区消费者
pc, err := consumer.ConsumePartition("web_log", int32(partition), sarama.OffsetNewest)
if err != nil {
fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err)
return
}
defer pc.AsyncClose()
// 异步从每个分区消费信息
go func(sarama.PartitionConsumer) {
for msg := range pc.Messages() {
fmt.Printf("Partition:%d Offset:%d Key:%v Value:%v", msg.Partition, msg.Offset, msg.Key, msg.Value)
}
}(pc)
}
}
kafaka简单操作
1)启动kafka内置的zookeeper
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
2)kafka服务启动 ,成功不关闭页面
.\bin\windows\kafka-server-start.bat .\config\server.properties
3)创建topic测试主题kafka,成功不关闭页面
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
4)创建生产者产生消息,不关闭页面
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
5)创建消费者接收消息,不关闭页面
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
参看文章:go操作kafka
http://kafka.apachecn.org/documentation.html#producerapi
https://blog.csdn.net/github_38482082/article/details/82112641

 浙公网安备 33010602011771号
浙公网安备 33010602011771号