使用faster-rcnn.pytorch训练自己数据集(完整版)
引言
最近在实验室复现faster-rcnn代码,基于此项目成功测试源码数据集后,想使用自己的数据集爽一下。
本文主要介绍如何跑通源代码并“傻瓜式”训练自己的数据集~之前的此类博客都是介绍如何在原作者的caffe源码下进行数据集训练,那么本文针对目前形势一片大好的pytorh版faster-rcnn源码进行训练新的数据集,废话不多说,Lets go!
faster-rcnn pytorch代码下载
pytorch0.4.0版源码:https://github.com/jwyang/faster-rcnn.pytorch.git
pytorch1.0.0版源码:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0
具体配置此代码作者已在ReadMe介绍的很清楚,当然会有一些坑。
我复现代码的环境是python3.6+cuda10.1+Ubuntu16.04+Pytorch1.2。
配置环境及训练过程:
Tips:不要以为拿过代码以后,就可以直接跑demo!除非你的/models里面有训练好的模型。此处说的模型不是指Vgg或Resnet在分类数据集ImageNet下训好的Transfer模型,而是指的是在目标检测集VOC或COCO下进行fine-tune的模型。对于VOC2007数据集,训练好后该模型大概1个G,所以代码作者没有上传到github,要不你就自己训练,要不你就跟训好的人要,不过建议你自己训练,跑trainval_net.py。
尝试测试pytorch0.4.0版本(0.4.0版本尝试失败,想快速跑通可直接跳到pytorch1.0.0版本训练过程),据ReadMe配置环境后,执行训练数据集命令行:
训练命令行示例:
CUDA_VISIBLE_DEVICES=0,1 python trainval_net.py --dataset pascal_voc --net res101 --cuda
- “CUDA_VISIBLE_DEVICES”指代了gpu的id,这得看你实验室服务器哪块gpu是闲置的。
- “–dataset”指代你跑得数据集名称,我们就以pascal-voc为例。
- “–net”指代你的backbone网络是啥,我们以vgg16为例。
- "–bs"指的batch size。
- “–nw”指的是worker number,取决于你的Gpu能力,我用的是Titan Xp 12G,所以选择4。稍微差一些的gpu可以选小一点的值。
- “–cuda”指的是使用gpu。
训好的model会存到models文件夹底下,此处暂时使用默认的训练参数。
训练阶段在roibatchLoader.py出现报错:AttributeError:'int' object has no attribute 'astype'
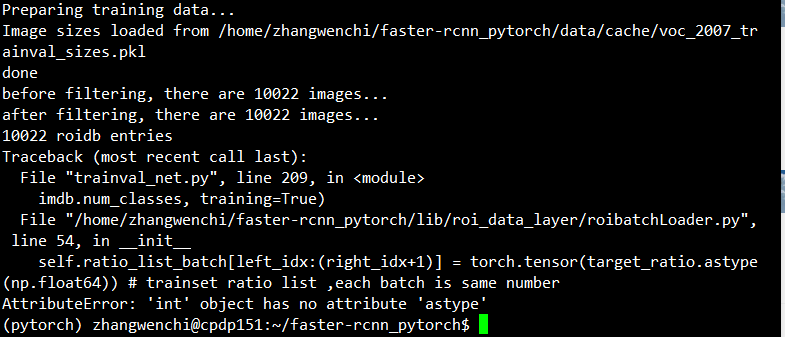
解决方案在GitHub上有所讨论htts://github.com/jwyang/faster-rcnn.pytorch/issues/452,但限于版本更新和pytorch放弃对之前版本部分语法的支持,此问题是短时间内难以解决的死胡同,遂放弃0.4.0版本转入1.0.0版本
据pytorch1.0.0分支ReadMe配置好pytorch环境后,运行训练时出现coco数据集导入问题
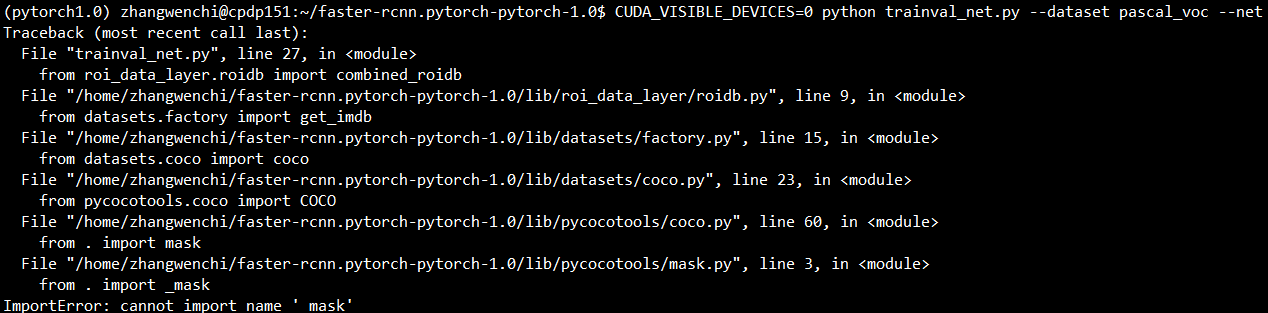
训练命令行示例:
CUDA_VISIBLE_DEVICES=0,1 python trainval_net.py --dataset pascal_voc --net res101 --cuda
若是在服务器上长久运行,断掉连接关掉xshell后继续运行,可是使用nohup语句。实测在一块TITAN X上运行一个epoch需要40min,20epoch大概需要训练一天。
nohup python trainval_net.py --dataset pascal_voc --net res101 --epochs 10 --bs 4 --lr 0.01 --lr_decay_step 8 --cuda &
Notice:bs切记不要太大,本例中bs=16会爆12G的显存,如果出现如下报错,调小bs即可
RuntimeError: CUDA out of memory. Tried to allocate 30.00 MiB (GPU 0; 11.93 GiB total capacity; 11.17 GiB already allocated; 5.81 MiB free; 222.17 MiB cached)
nohub语句使用详情请见我的另一篇博客:nohup---将程序以忽略挂起信号的方式运行起来
开始训练:
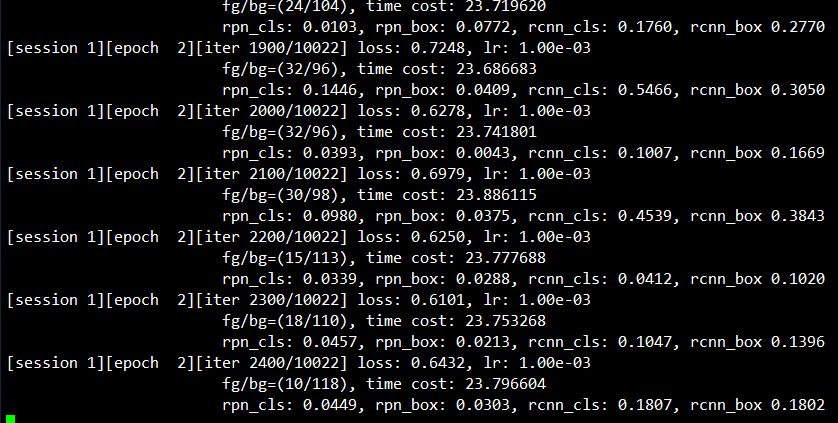
测试命令行示例:
python test_net.py --dataset pascal_voc --net res101 --checksession 1 --checkepoch 3 --checkpoint 10021 --cuda
注意,这里的三个check参数,是定义了训好的检测模型名称,我训好的名称为faster_rcnn_1_3_10021,代表了checksession = 1,checkepoch = 3, checkpoint = 10021,这样才可以读到模型“faster_rcnn_1_3_10021”。训练中,我设置的epoch为20,但训练到第3批就停了,所以checkepoch选择3,也就是选择最后那轮训好的模型,理论上应该是效果最好的。当然着也得看loss。
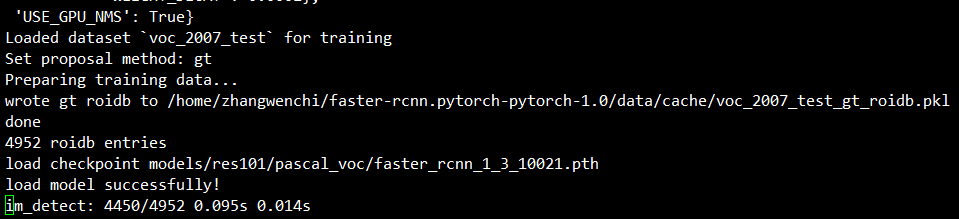
测试集5000张图像,一块TITANX平均测试时间0.1s/张,占用显存5G左右。
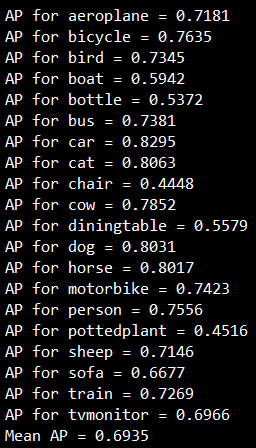
在VOC上20个class的mAP为69%,实际训练12epoch能到75%左右,(我训练3epoch就结束了loss还未收敛到较低程度)
demo命令行示例:
python demo.py --net vgg16 --checksession 1 --checkepoch 20 --checkpoint 10021 --cuda --load_dir models
此处我们需输入使用的网络(vgg16),以及训练好的模型路径(models)。我们测试的图片都在images文件夹里。在此处有坑。作者提供了4张image做测试,因为测试完的图像会输出到images文件夹里,所以做完一次测试,images文件夹会有8张图片(输出图片命名规则是在原图像文件名后面加上"_det"),而原作者没有把他自己测试后的图片删去,所以大家在做demo测试时,别忘把以"_det"结尾的检测输出文件先删去,否则测试完你的images文件夹可能会得到16张图像。。
当然,你可以放一些你自己在网上搜的图片在images文件夹里进行demo测试,看看效果。但检测类别一定在训练的类别中要有啊~
VOC2007数据集的类别在路径"/faster-rcnn.pytorch/lib/datasets/pascal_voc.py"文件中已注明,在此提醒:
//个例实验 self._classes = ('__background__', # always index 0 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor','plane')
放出一个识别网上的图片还不错的例子:

在测试的时候,如果没有gpu,则在命令行中不输入"–cuda"。但使用python3.5的朋友可能会遇到以下错误:
1 //weakref.py出错 2 Exception ignored in: <function WeakValueDictionary.__init__.<locals>.remove at 0x7f294b5c0730> 3 Traceback (most recent call last): 4 File "/anaconda2/envs/py35/lib/python3.5/weakref.py", line 117, in remove 5 TypeError: 'NoneType' object is not callable
解决方法如下:
https://github.com/python/cpython/commit/9cd7e17640a49635d1c1f8c2989578a8fc2c1de6#diff-a2f8f044364f136b5879679b60c19172
修改weakref.py后可完美解决。
训练自己数据集
当你走到这一步,恭喜,你马上就可以为所欲为了。在此只介绍适合于新手(我就是)的傻瓜式数据集制作方法。
我们以一个只检测一类的数据集为例,我这里是自己标注的飞机测试集,类别名称为“plane”。
我们仍然采用VOC2007数据集的类。皮不变,只是把我们自己的数据集“塞进去”
---VOC2007 ------Annotations ------ImagesSet ---------Main ------JPEGImages
真正“起作用”的训练集其实是这四个文件夹,位置是
faster-rcnn.pytorch/data/VOCdevkit/VOC2007/
1.Annotations为标注文件夹,若干.xml文件。每一个图片都对应一个.xml文件,其中存储的是该图片的名称,长宽,目标框(GroundTrues)的左上右下坐标,目标框的类别名称。
2.ImagesSet文件夹下的Main里,保存了需要训练图片的名称,以txt文本存储。
3.JPEGImage文件夹保存了原图片。
所以看到这,你就明白,怎么把我们的数据集塞进去了。
首先把我们的原图塞进JPEGImage文件夹里。当然原文件夹的图片我们需要备份,并从JPEGImage里移除。
然后,需要制作我们自己数据集的xml标注文件,朋友们如果想问做出的xml文件标准是啥样的,因为不同的标注软件生成的标注文件五花八门,和VOC一样的xml文件怎么制作?在此给个传送门,大家耐心学习:
https://blog.csdn.net/gvfdbdf/article/details/52214008
https://blog.csdn.net/zcy0xy/article/details/79614862
在此也给出如何更改xml文件中属性值的方法,链接如下:
用这个代码可以任意改变xml里的属性值,比如你想把xml文件中类别名称改变,或把图片名称、路径等值改变,参考上述代码链接。
在此放出我自己的数据集标注xml文件:
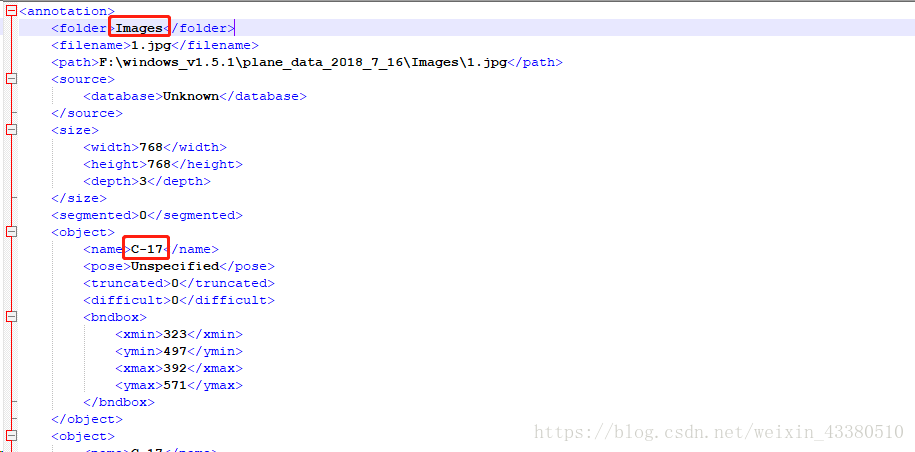
图中画圈的属性,需修改与VOC一样,folder应修改为"VOC2007",类别的name属性,也可修改为你想识别的类别,在此我将所有目标的name都改为"plane",修改代码见上述的github代码。
在所有xml文件修改后,将它们放入Annotations文件夹中。
最后,自己制作trainval.txt,里面存储自己的待训练图片名称,记住不要带.jpg后缀,这个很简单如下图所示:

制作好后将该文件放入ImagesSet\Main中
弹药已装好,下面需要为炮台调准方向!修改python文件。Ok我承认需要更改的几个坑真的坑了我一个晚上。。
第一处: faster-rcnn.pytorch/lib/datasets/pascal_voc.py

这个文件里存着VOC数据库的class,需要更改我们识别的类别,我的做法是把原class注释掉,把自己的class加进去,如图,加入’plane’类,看到这你也许就知道啦,这里的类名和前面xml文件中,目标的name属性应该是一样的。
第二处:发生如下错误:
assert(boxes[:,2]>=boxes[:,0]).all()
基本上都会碰上,只要是你标注的框靠近边缘,都会出这个错误,不用急,按照下面方法改,完美解决:
https://blog.csdn.net/xzzppp/article/details/52036794
第三处:发生如下错误:
Keyerror:'width'
OK,别着急,一帆风顺是不可能的,该句指的是得到的图像数据库imdb文件没有‘width’,也就是没有读到图像的宽度值,而这个宽度值是通过图片读出来的,所以说明你的训练文件夹JPEGImage中没有ImagesSet\Main\trainval.txt里列出的图片,我查了下,图片都放进去了,那为啥还出错呢?
原因是!在训练原数据集VOC时,图像数量是10021张(进行了数据增强),这时会保存训练信息至缓存中,文件路径为:
/home/zhangxin/faster-rcnn.pytorch/data/cache/voc_2007_trainval_gt_roidb.pkl
因此你在重新训练新数据集的时候,会读取这个缓存配置,以加快训练,那么此时就入坑了,我的新集合只有1000张,所以训练时读的缓存里,需要读的图像还是原来那10021张,那势必会找不到这10021张图像,所以要做的就是,把这个缓存文件voc_2007_trainval_gt_roidb.pkl删掉!
改完此处,可以完美进行训练,当然训练命令行不用变,怎么样,够傻瓜吧~

第五处: faster-rcnn.pytorch/demo.py
训完后,很想demo一下,看看训出来的模型如何,如果你觉得能顺利进行的话,那就图样图森破了,你会陷入第五个坑:
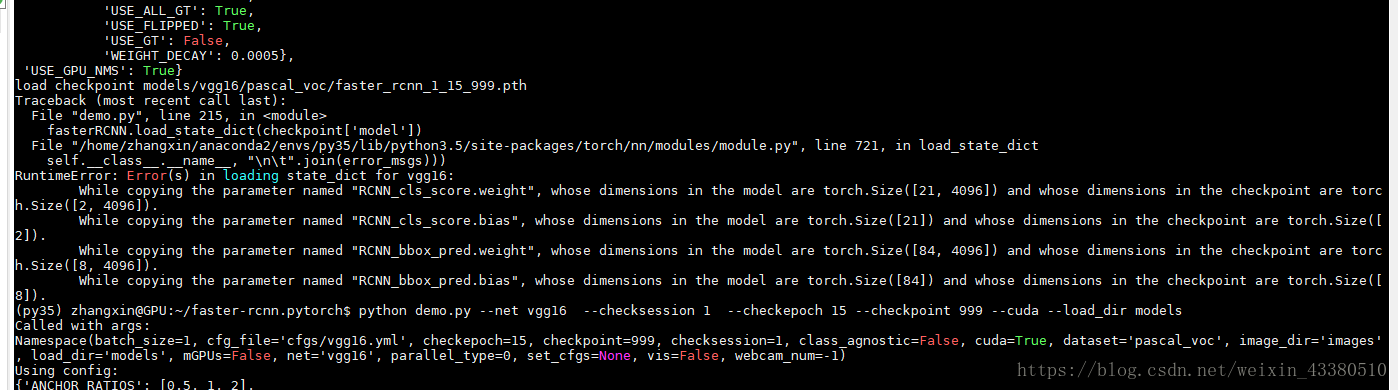
我们会发现,他说我们训的模型,预测层是两个节点(代表2类,飞机+背景),而测试的时候,发现模型是21类(原数据集的类数,20类+背景)。开始以为是训练前网络的输出类别数没有设置好,于是加各种断点找原因,但发现训练时的网络预测的类数就是2类。
//此处普及下设置断点代码 import pdb;pdb.set_trace()
于是机智的我又好好想了一下,那一定是测试的时候出错了,,而且上图错误信息也已经说了,是demo.py出问题了,于是,修改方法就有了,需修改demo.py文件:
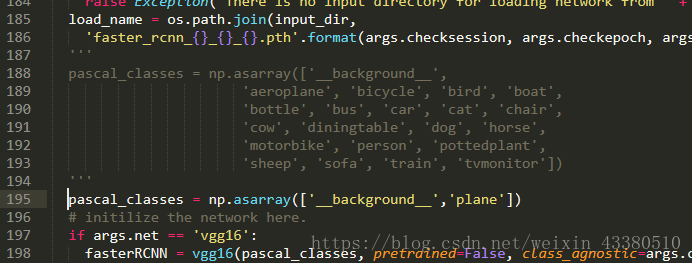
跟更改pascal_voc,py方法类似,更改自己训练集的类别。。
好了,设置完以上内容,我们就可以开始测试啦!
走一波小飞机!

有的个别效果不是很好,因为没有调参,而且训练集只有1000张,还没有做数据增强,不过这都不是重点,重点是掌握了训练自己数据集的技能!
最后给出一个小技巧,faster-rcnn对于每个图片会给出300个检测框,显示的时候,会限制最大显示框数量,同志们可以在以下路径的文件net_utils.py里修改。
/home/zhangxin/faster-rcnn.pytorch/lib/model/utils/net_utils.py

以下为参考
[1]https://blog.csdn.net/sinat_30071459/article/details/51332084
[2]https://blog.csdn.net/hongxingabc/article/details/79039537
[3]https://blog.csdn.net/gvfdbdf/article/details/52214008
[4]https://blog.csdn.net/xzzppp/article/details/52036794
[5]https://blog.csdn.net/sinat_30071459/article/details/50723212
[6]https://www.cnblogs.com/FZfangzheng/p/10852141.html
ref:https://blog.csdn.net/weixin_43380510/article/details/83004127


 浙公网安备 33010602011771号
浙公网安备 33010602011771号