

JVM中的STW和CMS
Java中Stop-The-World机制简称STW,是在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起(除了垃圾收集帮助器之外)。Java中一种全局暂停现象,全局停顿,所有Java代码停止,native代码可以执行,但不能与JVM交互;这些现象多半是由于gc引起。
GC时的Stop the World(STW)是大家最大的敌人。但可能很多人还不清楚,除了GC,JVM下还会发生停顿现象。
JVM里有一条特殊的线程--VM Threads,专门用来执行一些特殊的VM Operation,比如分派GC,thread dump等,这些任务,都需要整个Heap,以及所有线程的状态是静止的,一致的才能进行。所以JVM引入了安全点(Safe Point)的概念,想办法在需要进行VM Operation时,通知所有的线程进入一个静止的安全点。
除了GC,其他触发安全点的VM Operation包括:
1. JIT相关,比如Code deoptimization, Flushing code cache ;
2. Class redefinition (e.g. javaagent,AOP代码植入的产生的instrumentation) ;
3. Biased lock revocation 取消偏向锁 ;
4. Various debug operation (e.g. thread dump or deadlock check);
监控安全点看看JVM到底发生了什么?
最简单的做法,在JVM启动参数的GC参数里,多加一句:
-XX:+PrintGCApplicationStoppedTime
它就会把全部的JVM停顿时间(不只是GC),打印在GC日志里。
2016-08-22T00:19:49.559+0800: 219.140: Total time for which application threads were stopped: 0.0053630 seconds
这是个很有用的必配参数,可以打出几乎一切的停顿……
但是,在JDK1.7.40以前的版本,它居然没有打印时间戳,所以只能知道JVM停了多久,但不知道什么时候停的。此时一个土办法就是加多一句“ -XX:+PrintGCApplicationConcurrentTime”,打印JVM在两次停顿之间的正常运行时间(同样没有时间戳),但好歹能配合有时间戳的GC日志,反推出Stop发生的时间了。
2016-08-22T00:19:50.183+0800: 219.764: Application time: 5.6240430 seconds
如何打印出事哪种原因导致的停顿呢?
再多加两个参数:-XX:+PrintSafepointStatistics -XX: PrintSafepointStatisticsCount=1
此时,在stdout中会打出类似的内容
vmop [threads: total initially_running wait_to_block]1913.425: GenCollectForAllocation [ 55 2 0 ] [time: spin block sync cleanup vmop] page_trap_count[ 0 0 0 0 6 ] 0
此日志分两段,第一段是时间戳,VM Operation的类型,以及线程概况
total: 安全点里的总线程数
initially_running: 安全点时开始时正在运行状态的线程数
wait_to_block: 在VM Operation开始前需要等待其暂停的线程数
第二行是到达安全点时的各个阶段以及执行操作所花的时间,其中最重要的是vmop
spin: 等待线程响应
safepoint号召的时间
block: 暂停所有线程所用的时间
sync: 等于 spin+block,这是从开始到进入安全点所耗的时间,可用于判断进入安全点耗时
cleanup: 清理所用时间
vmop: 真正执行VM Operation的时间
可见,那些很多但又很短的安全点,全都是RevokeBias,详见 偏向锁实现原理, 高并发的应用一般会干脆在启动参数里加一句"-XX:-UseBiasedLocking"取消掉它。另外还看到有些类型是no vm operation, 文档上说是保证每秒都有一次进入安全点(如果这秒已经GC过就不用了),给一些需要在安全点里进行,又非紧急的操作使用,比如一些采样型的Profiler工具,可用-DGuaranteedSafepointInterval来调整,不过实际看它并不是每秒都会发生,时间不定。
在实战中,我们利用安全点日志,发现过有程序定时调用Thread Dump等等情况。不过因为安全点日志默认输出到stdout,因为性能及stdout日志的整洁性等原因,我们平时默认没有开启它。只有在需要时才打开。
再再增加下面三个参数,可以知道更多VM里发生的事情。可惜JVM不会因为设了这三个参数,就把安全点日志转移到vm.log里面来,而是白白打印了两次。
-XX:+UnlockDiagnosticVMOptions -XX:+LogVMOutput -XX:LogFile=/dev/shm/vm.log
总结
本文关于快速理解Java垃圾回收和jvm中的stw的介绍就到这里,希望对大家有所帮助,感兴趣的朋友可以参阅:浅谈Java回收对象的标记和对象的二次标记过程 、Java虚拟机装载和初始化一个class类代码解析 、Java中map遍历方式的选择问题详解等,有什么问题可以随时留言,小编会及时回复大家的。
并发标记清除(CMS)垃圾收集器
CMS GC设计之初最根本的目的就是减小最大响应时间。
随着越来越多的应用要求有一个垃圾收集器,它能比串行或并行垃圾收集器有更短的最坏情况的中断时间,牺牲一些应用的吞吐量来消除或极大地减少漫长的GC 中断数量也是能够接受的,针对这种情况,CMS 垃圾收集器被开发出来。
在CMS 垃圾收集器中,年轻代的垃圾收集与并行垃圾收集器很类似,它们是并行的而且会stop-the-world,也就是说在年轻代的垃圾收集过程中所有的Java 应用线程都会被暂停,而垃圾收集工作会用多线程的方式来执行。需要注意的是,你可以给CMS 垃圾收集器配置一个单线程模式的年轻代收集器,但在Java 8 中并不推荐这个方式,这个选项在Java 9 中被移除了。
并行垃圾收集器与CMS 垃圾收集器最主要的区别是在老年代的收集上。CMS 收集器的老年代收集活动试图避免应用线程的长时间中断。为了实现这个目的,CMS 老年代收集器在应用线程执行的同时做了大部分工作(垃圾收集线程与应用线程同时工作),除了少量相对短的GC 同步暂停。通常来说,绝大多数情况下CMS 是并发的,老年代收集的某些阶段会暂停应用线程,比如初始标记和重新标记阶段。在CMS 最初的实现中,初始标记和重新标记阶段都是单线程的,但现在它们都已经被改为多线程的。激活多线程的初始标记和重新标记阶段的HotSpot 命令行选项分别是-XX:+CMSParallelInitial Mark Enabled和-XX:CMSParallelRemarkEnabled,当通过命令行选项XX:+UseConcurrentMarkSweepGC 激活CMS 垃圾收集器时也会缺省自动激活这两个选项。
有可能,或者说极有可能会在一个老年代并发收集正在进行的时候,又发生了一个年轻代收集。一旦发生这种情况,老年代并发收集会被年轻代收集所中断,直到后者结束之后立刻恢复执行。CMS GC 的缺省年轻代收集器被称为ParNew 收集器。
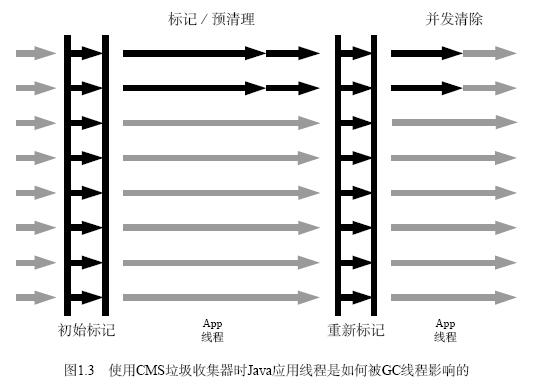
图1.3 描述了由于年轻代垃圾收集(黑色箭头)、CMS 初始标记,重新标记阶段以及老年代垃圾收集stop-the-world 阶段,导致Java 应用线程被暂停。CMS 垃圾收集器的老年代收集活动从一个stop-the-world 的初始标记阶段开始。一旦完成初始标记,就进入并发标记阶段,在这个阶段允许Java 应用线程和CMS 标记线程同时执行。图1.3 中,在“标记/预清理”标签下方,前两个比较长的黑色箭头就是并发标记线程。一旦并发标记完成,CMS线程就执行并发预清理,即图中“标记/预清理”标签下方两个较短的黑色箭头。需要注意的是,如果有足够的可用硬件线程,CMS 线程的执行成本并不会对Java 应用线程的性能产生太大影响。但如果硬件线程是饱和的或被高度利用的,CMS 线程就会和Java 应用线程竞争CPU 周期。一旦并发预清理完成,stop-the-world 的重新标记阶段就会开始。在重新标记阶段会标记初始标记、并发标记以及并发预清理过程中可能错过的对象。当重新标记阶段结束后,并发清除启动,释放所有死亡对象的空间。
使用CMS 垃圾收集器面临的一个挑战就是要在应用消耗完Java 的可用堆空间之前完成并发收集工作。因此对CMS 来说有个很棘手的部分,就是找到一个合适的时机来启动这个并发工作。这种并发方式往往导致一个结果,就是处理同一个应用,CMS GC 会比并行GC 多占用10%~20%的Java 堆空间。这也是为了缩短垃圾收集暂停时间所付出的代价。
CMS 垃圾收集器的另一个挑战是如何处理老年代中的空间碎片,也就是当老年代中对象间的空间碎片太小,以至于无法容纳从年轻代晋升上来的对象,因为在CMS 的并发收集循环中并不执行压缩,哪怕是增量或局部压缩。一旦无法找到可用空间,就会使CMS 回过来使用串行GC,触发一次full 收集,导致一个漫长的暂停。伴随CMS 碎片的另一个很不幸的挑战就是上述问题完全无法预测。同样都是老年代碎片,某些应用可能没有经历过一次full GC,而有些可能时不时就要经历一次。
对CMS 垃圾收集器做些调整,对应用做些优化改动,诸如避免生成大尺寸对象,会有助于延缓空间碎片的产生。当然,调优本就是个不寻常的工作,对专业能力有很高的要求,所以改动应用来避免碎片也是个不小的挑战。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号