


如何保证缓存与数据库的双写一致性?
问题1:先更新数据库,再删除缓存。如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据就出现了不一致。
解决思路:先删除缓存,再更新数据库。如果数据库更新失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。因为读的时候缓存没有,所以去读了数据库中的旧数据,然后更新到缓存中。
问题2:数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改。完了,数据库和缓存中的数据不一样了...
解决思路(1):写请求先删除缓存,再去更新数据库,(异步等待段时间)再删除缓存(成功表示有脏数据出现)。
这种方案读取快速,但会出现短时间的脏数据。
解决思路(2):写请求先修改缓存为指定值,再去更新数据库,再更新缓存。读请求过来后,先读缓存,判断是指定值后进入循环状态,等待写请求更新缓存。如果循环超时就去数据库读取数据,更新缓存。
这种方案保证了读写的一致性,但是读请求会等待写操作的完成,降低了吞吐量
详细参考文章:https://blog.csdn.net/hukaijun/article/details/81010475
上篇文章提到,一般存储数据,都用市面上比较流行的MYSQL和ORACLE数据库存储,但随着数据量的增加,总有一次会达到数据库性能瓶颈,访问读写速度缓慢。考虑用Redis来缓存数据库数据,减轻数据库的压力,提高访问请求响应速度。
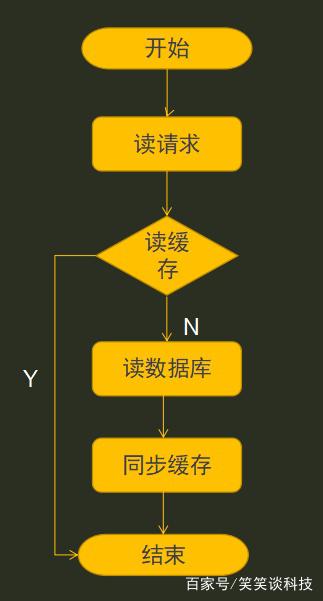 读请求流程
读请求流程先读缓存数据,缓存数据有,则立即返回结果;如果没有数据,则从数据库读数据,并且把读到的数据同步到缓存里,提供下次读请求返回数据。
虽说这样能减轻数据库压力,但是如果修改删除数据,在多线程高并发的场景下会有可能导致缓存和数据库数据不一致问题,那该如何解决呢?
分析问题与解决方案
场景一:
问题的根源其实是读数据与写数据请求同时并发时,数据库与缓存数据已更新,但访问的数据还是老数据,出现了脏读数据,我们假设读请求流程没有问题,那就分析写请求流程的优化
1. 先更新缓存,再更新数据库
这个方案肯定不行。原因是更新缓存成功,更新数据库出现异常了,导致缓存数据与数据库数据完全不一致。
2. 先更新数据库,再更新缓存
这个方案同样不行,原理跟第一个一样,数据库更新成功了,缓存更新失败,同样会出现数据不一致问题。
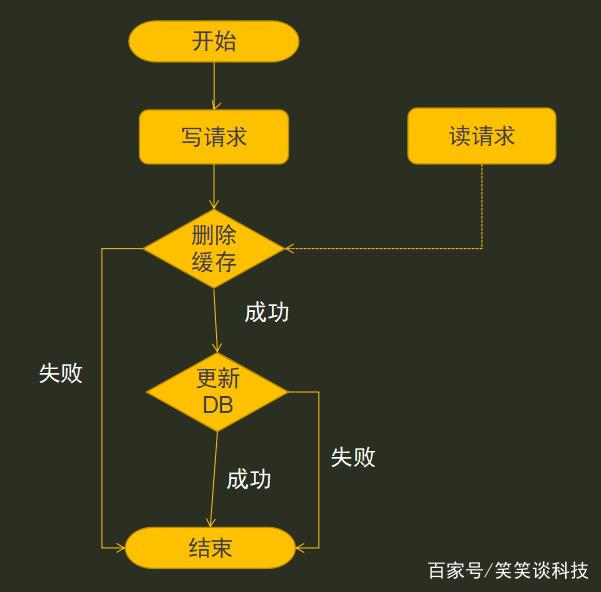 读请求与写请求并发
读请求与写请求并发那两种方案都不行,还有什么更好的解决方案呢?我们遇到写请求时,可用先删除缓存数据,再更新数据库,这样不管数据库更新失败还是缓存删除失败,缓存与数据库始终一致。这种方案一般可满足上万人并发操作了,因为删除缓存到更新数据库的时间可以用毫秒计算,正常的并发影响不大。但如果是达到上亿级访问,在这时间段内,会出现读请求在写请求更新数据库之前执行,导致数据库与缓存不一致
场景二:
上亿级并发访问,导致缓存与数据不一致。
比方:淘宝双11活动,抢购商品,商品数量为100,当前状态是数据库和缓存都是100,这时上亿账户抢购该商品,商品数量要减少。一个消费者A抢购成功,这时应该删除缓存,更新商品数量,在更新商品数量之前,又有一个消费者B来查看该商品数量,由于缓存清空,到数据库查询,该消费者查看到的是商品数量为100,并更新缓存为100,其实商品数量已经被消费者B抢购成功之后,数据库中商品数量更新为99了,缓存与数据库数据不一致
方案一:读写分离
读请求只访问缓存,写请求只修改数据库和缓存
 读写分离流程
读写分离流程写请求修改数据库和缓存是事务性动作,如果更新数据库成功,更新缓存失败,则回滚数据库,保证缓存与数据库数据强一致。这样实现了读写分离,不仅提高了读的响应速度,由写请求负责缓存与数据库一致,只有写请求成功才会影响到缓存的内容,时效性大大增强。
方案二:队列存储请求
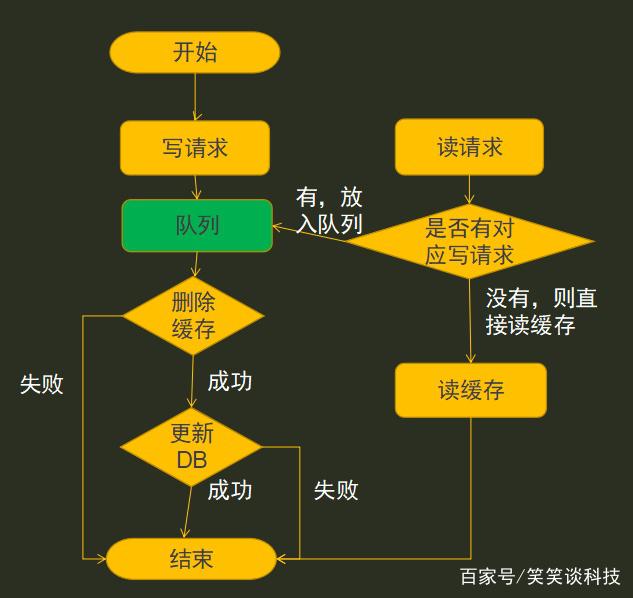 方案二流程
方案二流程沿用场景一的解决方案,为解决其缺陷,添加队列,凡是遇到写请求,则将写请求放入队列中,由队列对写请求统一管理,写请求处理成功,则从队列中删除。当有一个读请求过来时,到队列查询,是否有对应的写请求,如果有则放入队列中,等待写请求执行完之后再执行读请求。为防止某个请求阻塞情况,为其设置超时机制或者过期机制。
这种方案虽可行,但是倘若访问量大,处理器来不及处理,队列内的请求数量越来越高,则会影响查询效率。出现这种情况,就要加机器集群执行,帮忙分担压力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号