
ELK原理与简介
为什么用到ELK:
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
ELK简介:
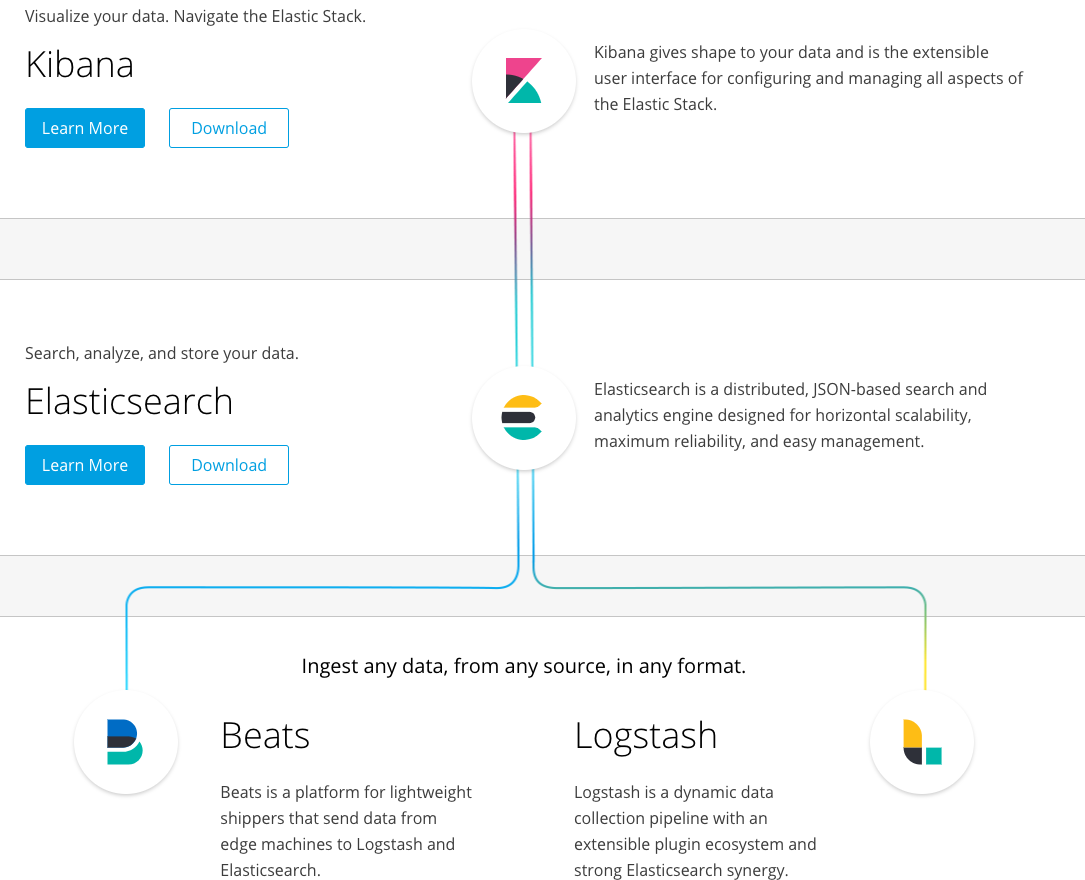
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Filebeat隶属于Beats。目前Beats包含四种工具:
- Packetbeat(搜集网络流量数据)
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
- Filebeat(搜集文件数据)
- Winlogbeat(搜集 Windows 事件日志数据)
官方文档:
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/6.4/index.html
Logstash:
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/6.4/index.html
Kibana:
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/6.4/index.html
Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/6.4/index.html
elasticsearch中文社区:
https://elasticsearch.cn/
ELK架构图:
架构图一:

这是最简单的一种ELK架构方式。优点是搭建简单,易于上手。缺点是Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。
此架构由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户亦可以更直观的通过配置Kibana Web方便的对日志查询,并根据数据生成报表。
架构图二:

此种架构引入了消息队列机制,位于各个节点上的Logstash Agent先将数据/日志传递给Kafka(或者Redis),并将队列中消息或数据间接传递给Logstash,Logstash过滤、分析后将数据传递给Elasticsearch存储。最后由Kibana将日志和数据呈现给用户。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
架构图三:

此种架构将收集端logstash替换为beats,更灵活,消耗资源更少,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。
来自:https://www.cnblogs.com/aresxin/p/8035137.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号