
初识Disruptor
Disruptor
文章参考:http://ifeve.com/ringbuffer/
背景介绍
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。目前,包括Apache Storm、Camel、Log4j 2在内的很多知名项目都应用了Disruptor以获取高性能。
★需要特别指出的是,这里所说的队列是系统内部的内存队列,而不是Kafka这样的分布式队列。

技术介绍
Disruptor是基于无锁的并发“生产者 - 消费者模型”构建的。在保证逻辑正确的前提下,尽可能地提高队列在并发情况下的性能,Disruptor 采用了“两阶段写入”的方法。在写入数据之前,先加锁申请批量的空闲存储单元,之后往队列中写入数据的操作就不需要加锁了,写入的性能因此就提高了。Disruptor 对消费过程的改造,跟对生产过程的改造是类似的。它先加锁申请批量的可读取的存储单元,之后从队列中读取数据的操作也就不需要加锁了,读取的性能因此也就提高了(即在读和写之前均加锁,然后在真正的读和写过程中不加锁)。
对于生产者
对于生产者来说,它往队列中添加数据之前,先申请可用空闲存储单元,并且是批量地申请连续的 n 个(n≥1)存储单元。当申请到这组连续的存储单元之后,后续往队列中添加元素,就可以不用加锁了,因为这组存储单元是这个线程独享的。
对于消费者
对于消费者来说,处理的过程跟生产者是类似的。它先去申请一批连续可读的存储单元(这个申请的过程也是需要加锁的),当申请到这批存储单元之后,后续的读取操作就可以不用加锁了。

核心数据结构-RingBuffer
RingBuffer是一个环形数组,你可以把它当作在不同上下文(线程)间传递数据的buffer。
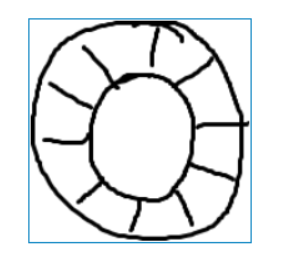
RingBuffer拥有一个序号,这个序号指向数组中下一个可用的元素。
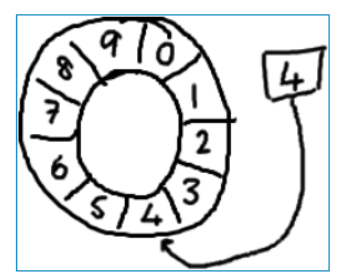
随着你不停地填充这个buffer,这个序号会一直增长,直到绕过这个环(注意:图中的黑色数字代表的是序号值,不是数组的真正下标)。
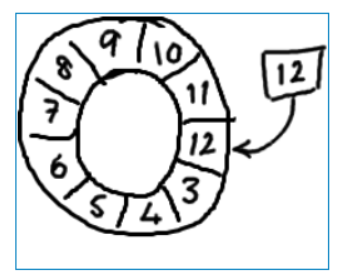
若想找到数组中当前序号所指向的元素(寻址),可以通过mod操作获得。
序号 % arr.length = arrIndex
12 % 10 = 2
2代表->数组下标是2
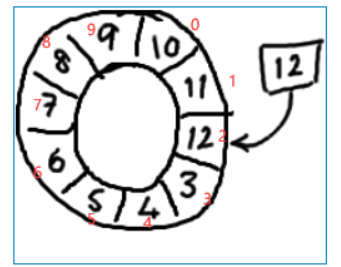
事实上,上图中的Ringbuffer只有10个槽完全是个意外。如果槽的个数是2的N次方将更有利于基于二进制的机器运算。
2的N次方换成二进制就是1000,100,10,1这样的数字,
--> 序号 & arr.length-1 = arrIndex,
比如一共有8槽,3&(8-1)=3,HashMap就是用这个方式来定位数组元素的,这种方式比取模的速度更快。
当另外一个服务通过nak (拒绝应答信号)告诉我们没有成功收到消息时,我们会从nak的那一个地方重新开始发送(因为RingBuffer不会删除已发送的数据,除非数据被覆盖了)。
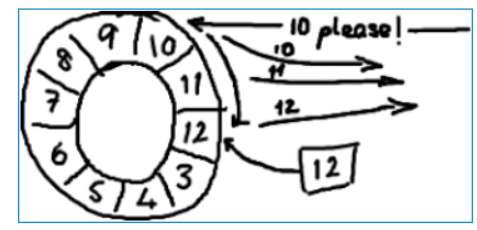
收到10号nak,那就从10号重新开始发送:10、11、12。。。
优点/为什么这么快
使用了数据,可以为数组预先分配好内存,使得数组对象一直存在,不会频繁的发生垃圾回收,此外,它也不会像链表那样,需要花时间在创建结点上,并且删除结点也是需要时间的,而RingBuffer没有删除操作,而是对原数据进行覆盖。
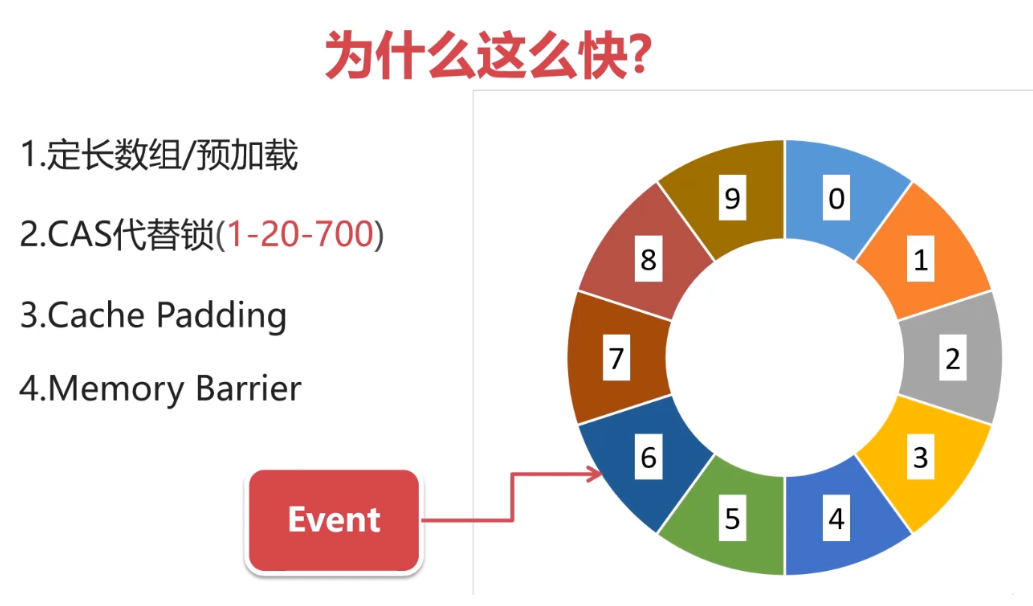
★Cache Padding:缓存补齐
前情提要:下图中,上方是内存,下方是高速缓存(CPU不是直接与内存交互的,他俩中间还有一个高速缓存),高速缓存是多级结构的,图中就是三级缓存结构的高速缓存。
内存 <--> 高速缓存 <--> CPU
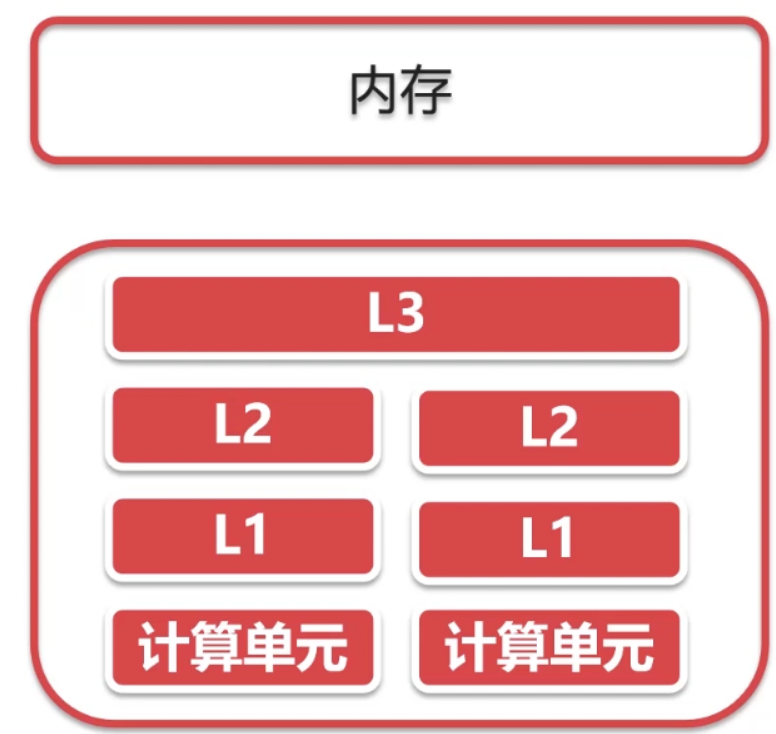
高速缓存是一行一行存储数据的(1到8是一行,有三行),如下图:

那么Cache Padding到底是什么?
缓存是以缓存行为最小单位存储数据的,一个缓存行可以存储多个不同的数据,这些不同数据数据被不同线程中的任意一个修改之后,会导致整行缓存失效,会导致其他线程更新缓存行,这就是低效的原因(更细的解释:一个缓存行中有多个数据,其中的某一个数据被某一个线程修改后,该行数据会整体失效,而在该行中的其他数据可能是和其他线程关联的,而它们缺因为一个线程的修改而被迫受到影响)。
★所以可以使用缓存补齐/填充来提高效率,即每一个缓存行只缓存一个数据,虽然这样会导致缓存的使用率降低,但是会减少缓存失效的频率。
★Memory Barrier(Volatile)
在RingBuffer中有游标字段(cursor),它是被volatile修饰的,它是我们可以不用锁而实现 Disruptor 的一个原因。

生产线程和消费线程有他们各自的cursor,当某一个cursor被修改时,其他线程能立刻发现。
- 消费线程的cursor若比生产线程的cursor要小,那么就可以处理数据,否则就要停下来等待。
- 下游的消费线程可以跟踪上游的消费线程,如上图所示:下游消费线程要等待上游消费线程消费完后,才能够对Entry1进行操作,即必须保证上游先消费完1,然后下游才能去消费1。
还未提到的点
RingBuffer的环重叠问题、如何对RingBuffer进行读写

 浙公网安备 33010602011771号
浙公网安备 33010602011771号