


1 架构
SQL是结构化查询语言。而MySQL是一种关系数据库,是软件,是DBMS(数据库管理系统),且有自己独特的SQL实现。
根据看的书和网上查看各种专家的博客总结,在全貌上,我们可以把MySQL分成两个部分:
-
Sever层:负责连接、分析、优化和执行等。主要有连接器、查询缓存、预处理器、优化器、执行器等。包括了MySQL的大多数核心服务功能,所有的内置函数(日期、时间、数学和加密函数等)和所有跨存储引擎的功能(存储过程、触发器、视图等)都在这一层实现。
-
存储引擎层:负责数据的存储和提取。MySQL是插件式存储引擎架构的,这是它最独特的一点,支持InnoDB、MyISAM、Memory等多个存储引擎。现在最常用的是InnoDB(支持事务),从MySQL 5.5.5版本称为默认存储引擎。存储引擎是基于表的,而不是数据库。
如下图所示:
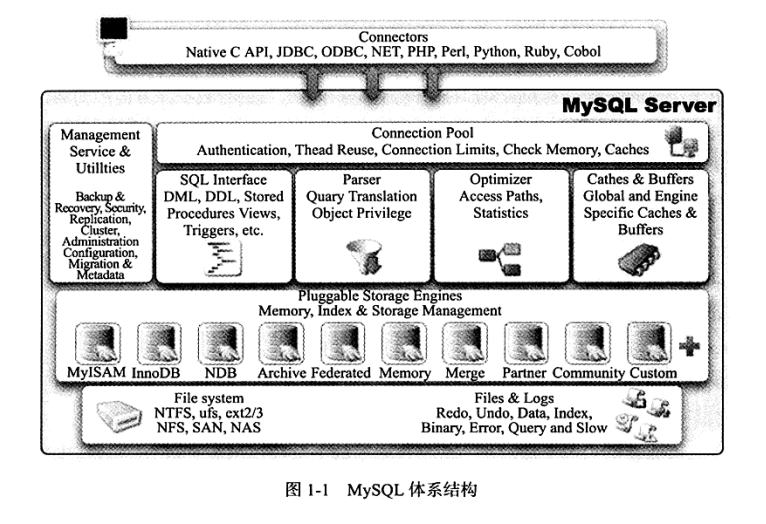
从上图中可以看出,不同的存储引擎共用同一个Sever层,即从连接器到执行器的部分。
现在大致分析一下各个组件的作用:
1.1 连接器
即上图中的Connectors,负责跟客户端建立连接、获取权限、维持和管理连接。
要是用一个数据库,首先要连接到数据库,这时数据库端的连接器就开始起作用了。实质是本地的一个连接进程和服务端的MySQL数据库实例进行通信,本质是进程通信。
mysql -h$ip -P$port -u$user -p
#-h,指定ip地址,如果本地MySQL,则可省略
#-P,指定端口
#-u,指定用户名,管理员为root
#-p,指定密码吗,一般不建议在命令行写密码
连接命令中的mysql是客户端工具,用来跟服务端建立连接。
首先使用TCP三次握手进行连接,TCP/IP套接字是MySQL数据库在任何平台下都提供的连接方式,根据MySQL服务是否正常运行,确定是否完成TCP连接。
连接完成后,验证用户名/密码是否正确,给出回复。
以上正常完成后,则连接器会到权限表中查出权限,此后该连接权限不变,除非修改后重连。
1.2 查询缓存
首先确定,查询缓存往往弊大于利(查询缓存的失效非常频繁)。MySQL 8.0版本直接将查询缓存的整块功能删掉了,也就是说8.0开始彻底没有这个功能了。
MySQL服务收到客户端传来的SQL语句,解析出第一个字段,判断语句类型。
SELECT语句则会先去查询缓存( Query Cache )里查找缓存数据,看看之前有没有执行过这一条命令,这个查询缓存是以 key-value 形式保存在内存中的,key 为 SQL 查询语句,value 为 SQL 语句查询的结果。
注意:查询缓存是Sever层的,8.0移除的是Sever层的查询缓存,并不是InnoDB中的buffer pool。
1.3 解析器
在执行SQL语句之前,会对SQL语句做解析。
-
词法分析:识别关键字,构建SQL语法树,方便后面模块获得 SQL 类型、表名、字段名、 where 条件等等。
-
语法分析:根据词法分析结果,语法分析器根据语法规则,判断 SQL 语句是否满足 MySQL 语法。
注意:8.0表或字段不存在不是在解析器里做的,8.0解析器只负责构建语法树和检查语法。
后面的阶段,各有说法,所以我选择了比较详细的一种,即小林coding的版本,感谢大佬。
1.4 执行SQL
每条SELECT 查询语句流程主要可以分为下面这三个阶段:
- prepare 阶段,也就是预处理阶段;
- optimize 阶段,也就是优化阶段;
- execute 阶段,也就是执行阶段;
1.4.1 预处理器
预处理阶段做事:
- 检查 SQL 查询语句中的表或者字段是否存在;
- 将
select *中的*符号,扩展为表上的所有列;
对于 MySQL 5.7 判断表或字段是否存在的工作,是在词法分析&语法分析之后,prepare 阶段之前做的。结论都一样,不是在解析器里做的。正因为 MySQL 5.7 代码结构不好,所以 MySQL 8.0 代码结构变化很大,后来判断表或字段是否存在的工作就被放入到 prepare 阶段做了。
1.4.2 优化器
经过上述步骤,MySQL知道要做什么,但要怎么做,还需要先经过优化器处理。
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。不同的方法会导致执行的效率不同,而优化器的作用就是决定选择使用哪一个方案。
1.4.3 执行器
经过优化器,确定了执行方案,MySQL就会真正开始执行语句,在执行的过程中,执行器就会和存储引擎交互,交互是以记录为单位的。
开始执行时,要先判断对这个表有没有执行权限,如果没有,就会返回没有权限的错误。如果有权限,就打开表继续执行。
1.5 插件式存储引擎
存储引擎的好处是,每个存储引擎都有各自的特点,能根据具体的应用建立不同存储引擎表。并且MySQL是开源的,用户可以根据MySQL预定义的存储引擎接口编写自己的存储引擎。
执行CREATE TABLE建表的时候,如果不指定引擎类型,默认使用的就是InnoDB。不过,你也可以通过指定存储引擎的类型来选择别的引擎,比如在CREATE TABLE语句中使用 ENGINE=memory, 来指定使用内存引擎创建表。
下面介绍几种常见的存储引擎。
1.5.1 InnoDB
支持事物,主要针对在线事务处理(OLTP)。
特点:支持行锁设计、支持外键,并支持类Oracle的非锁定读。
MySQL 5.5.8版本之后,成为默认存储引擎。
数据放在一个逻辑表空间,这个表空间由InnoDB存储引擎自身进行管理。
对于表中数据的存储,InnoDB采用聚集方式,因此每张表的存储都是按主键的顺序进行存放。
最常用的一种引擎,Facebook、Yahoo等公司证明其高可用性、高性能及高可扩展性。
1.5.2 MyISAM
不支持事物、表锁设计,支持全文所有,主要针对一些OLAP数据库应用。
MySQL 5.5.8版本之前,MyISAM都是默认的存储引擎。
MyISAM的缓冲池只缓存索引文件,而不缓冲数据文件。这点与大多数数据库都非常不同。(MySQL数据库值缓存其索引文件,数据文件的缓存由操作系统本身完成)
表由MYD和MYI组成,MYD存放数据文件,MYI存放索引文件。
1.5.3 Memory
表中的数据都存放在内存中,如果数据库重启或发生崩溃,表中数据都会消失。它非常适合用于存储临时数据的临时表。
默认使用哈希索引,而不是B+树索引。
只支持表锁,并发性能差,不支持TEXT和BLOB类型,存储变长字段按照定长字段进行,因此会浪费内存。
若使用Memory存储引擎作为临时表来存放查询的中间结果集,若中间结果集大于Memory引擎表的容量,或含有TEXT和BLOB字段,则会把其转换到MyISAM存储引擎表而存放到磁盘中。
1.5.4 其他
存储引擎列表:
- NDB
- Archive
- Federated
- Maria
- Merge、CSV、Sphinx、Infobright等等
持续修改更新ing
参考:小林coding——图解MySQL & MySQL实战45讲 & 技术内幕


 浙公网安备 33010602011771号
浙公网安备 33010602011771号