函数的基础知识
-
文件内光标的移动(了解)
-
文件数据修改(了解)
-
函数简介
-
函数的语法结构
-
-
函数的参数(重要)
今日内容详细
一、文件内光标的移动(了解)
# 1.前戏
with open(r'a.txt','r',encoding='utf8') as f:
print(f.read(3))
print(f.read(3))
# read在文本模式下 括号内的数字表示的是读取指定的字符个数
with open(r'a.txt','rb') as f:
print(f.read(9).decode('utf8')) # 读取九个字节
print(f.read(1).decode('utf8')) # 读取一个字节
# read在二进制模式下 括号内的数字表示的是读取指定的字节数
# Unicode所有的字符都是用2bytes来起步表示
# utf8中文用3bytes来表示 英文用1bytes来表示 往后Unicode可以不做研究 只研究utf8、gbk等编码即可
# 2.控制光标的移动
# with open(r'a.txt','r',encoding='utf8') as f:
分好多种情况
print(f.read()) # 表示的是光标从开头读取到末尾
f.seek(3,1) # 表示的是光标在基于当前位置 往后移动三字字节
# with open(r'a.txt','rb') as f:
# print(f.read(3).decode('utf8'))
# f.seek(3,1) 表示在当前位置 继续往后移动三个字节
# f.seek(-3,2) 表示基于文件末尾 往前移动三个字节
# print(f.tell()) 表示回去光标基于文件开头的字节数 比如:15
其中seek方法可以控制光标的移动 在文本模式下移动的单位也可以是字节数
seek(offset,whence)
offset:控制移动的字节数
whence:控制模式
0:相对于文件开头(让光标先移动号)
支持文本模式和二进制模式
1:相对于当前位置(让光标停留在当前位置)
支持二进制模式
2:相对于文件结尾(让光标先移动号到文件末尾)
只支持二进制模式
![]()

二、文件的修改
在计算机中,计算机硬盘上的数据有两个状态:自由态和占有态
我们在删除数据其实就是将数据原来的位置标记成自由态
之后如果有新的数据进来了并且落在了自由态位置,那么将直接覆盖
作用:比如自己的手机和电脑 当我们不需要使用时 也不要轻易的卖掉
如何清除自己的数据方法:先删除手机或电脑上所有的数据 然后找一些无关紧要的数据存储一遍(比如500G的葫芦娃)
存储好之后再删除一次 这样的话就算别人拿到恢复了打开也是那500G的葫芦娃
如何更改文件内数据:
比如 with open(r'b.txt','r',encoding='utf8') as f:
如果直接写f.seek(9) 默认是0模式 基于文件开头 并且兼容文本和二进制
f.write('你大爷') 这样写只能在文件后面加上‘你大爷’
也就是说文件数据在硬盘上其实是固定的 不可能从中间再添加新的内容 只能将老内容移除
然后再换一段新的上去
# 思考思路:将文件内容一次性全部读入内存中,然后再内存中修改完毕后在覆盖重新写回原文件
# 操作方法:利用with的简易拷贝功能
# 优点:在文件修改过程中通一份数据只有一份
# 缺点:会过多地占用内存
with open('b.txt', mode='r', encoding='utf-8') as f:
data = f.read()
with open('b.txt', mode='w', encoding='utf-8') as f:
f.write(data.replace('张一蛋', 'jason')) 可以达到更换数据的模式
# 方式二
实现思路:以读的方式打开原文件,以写的方式打开一个临时文件 一行行读取原文件内容 修改完后写入临时文件
# 删掉原文件 将临时文件重命名为原文件名
# 优点:不会占用太多的内存
# 缺点:在文件修改过程中同一份数据存储了两份
os.remove('b.txt') # 删除文件
os.rename('.b.txt.swap','b.txt') # 重命名文件
![]()

三、函数简介
如何查看内部源代码:Ctrl + 左键点击即可
举个例子:在前面的学习中我们学过统计列表内元素的个数方法:
1.print(len()):直接使用某些特定功能的字len(),strip()来实现
2.也可以通过写代码的方法:
n = 0
for i in s1:
n += 1
print('列表内元素的个数',n)
通过这两个例子发现:两种方式都能统计元素的个数 第二种如果换一种基本数据类型 需要反反复复的编写相同的代码,由此引出了我们对函数的概念
函数:我们需要在不同的地方 反复执行相同的代码
循环:我们需要在相同的地方 反复执行相同的代码
函数例子:
def my_len():
n = 0
for i in s:
n += 1
print('字符串中字符的个数',n)
如果需要调用该函数,只要print(my_len())即可
在该函数例子中可以得出得结论:
1、真正的len是可以统计指定数据的元素个数,而例子的len目前只能统计指定的数据
2、真正的len执行完后会有结果,而例子中的len执行完成后结果是none
由此可得出函数的实质:相当于工具 是提前定义好后可以反复使用
len是python解释器提前给我们写好的函数(工具)
工具顾名思义就是我们只需要拿来使用即可 这种类型的函数我们称之为内置函数
自定义函数:我们自己写的函数称之为自定义函数
四、函数的语法结构
函数基本书写
def 函数名(参数1,参数2):
'''函数的注释'''
函数体代码
return 返回值
下面将各个部分分开来解释一下
1.def:是定义函数的关键字,也是函数的标识
2.函数名 函数名类似于变量中的变量名 指代函数体代码 命名与变量名一样取名要做到见名知意
3.括号:定义函数的时候 函数名后面肯定要先写括号
4.参数:类似于使用函数的时候 给函数内部传递的数据 可以不写或单个 多个都可以
5.冒号:定义函数也需要有缩进的子代码
6.函数的注释:用于解释函数的主要功能 使用方法等说明性文字
7.函数体代码:函数的核心部分 也是我们编写的核心
8.return:后面跟什么 那么执行完函数后返回的反馈
需要注意的是:定义函数需要使用def关键字
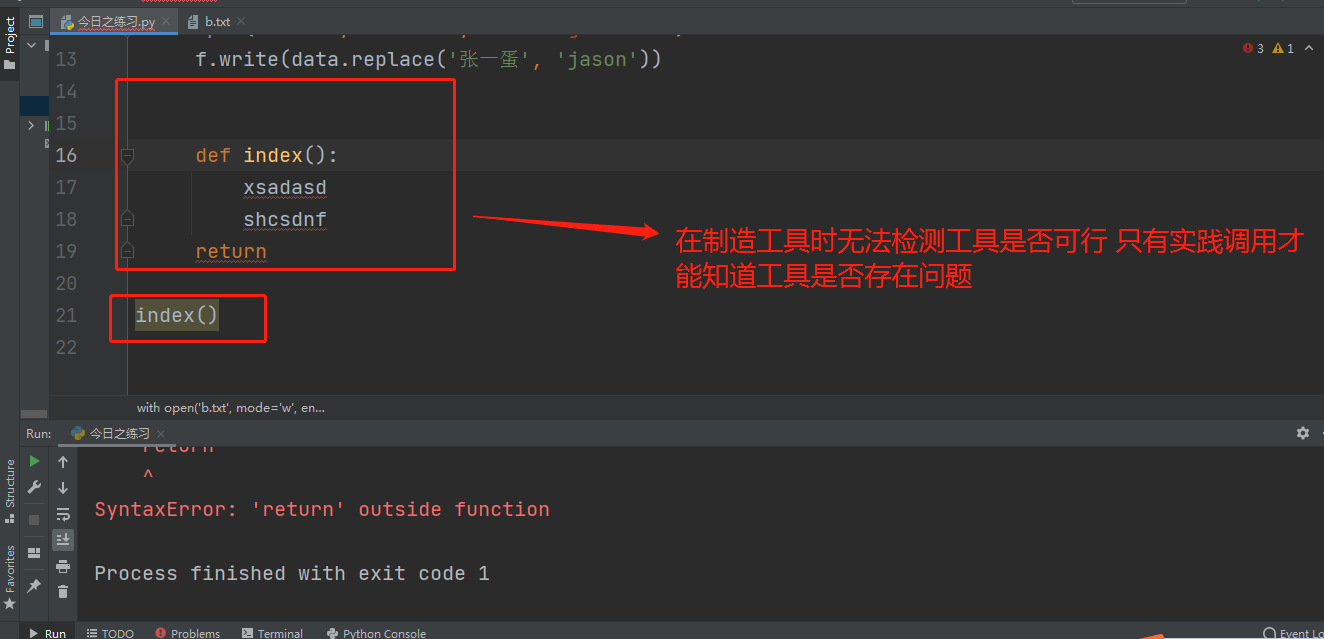
定义函数的过程中不会执行函数体代码(简单来说就是在编写函数时子代码没有语法问题就算报错也可以运行,但是如果需要使用此函数计算机就会报错,跟写一般代码还是有区别的) 只会检测语法 定义时不会报错 只有当函数编写完后在调用函数(工具)时,计算机才知道会报错,一个工具有没有用,不是在制造时能发现,只有放在实际应用中才能发现工具的可行性与实践性
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号