Word2Vec 词向量
首先,为什么需要Word2Vec?
因为人类世界的字符、语言计算机理解不了,需要将词语、语音等形式转化成数值形式,计算机才能理解,Word2Vec顾名思义,就是将词语转换成向量
接下来就来揭开 word2vec 的神秘面纱吧~
Word2Vec
Word2Vec 是一种广泛使用的NLP技术,目的是将词语转换成向量形式,使计算机能够理解。
通过学习大量文本数据,捕捉到词语间的上下文关系,进而生成词的高维表示,即词向量。
Word2Vec有两种主要模型:跳字模型Skip-Gram 和 连续词袋 CBOW(Continue Bag of Words)
- Skip-Gramd: 根据目标词预测其周围的上下文词汇
- CBOW:根据周围的上下文词汇来预测目标词。
Word2Vec的优点就是能够揭示词与词之间的相似性(比如通过计算向量之间的距离来找到语义上相近的词)
模型架构
CBOW
CBOW 模型架构示意图
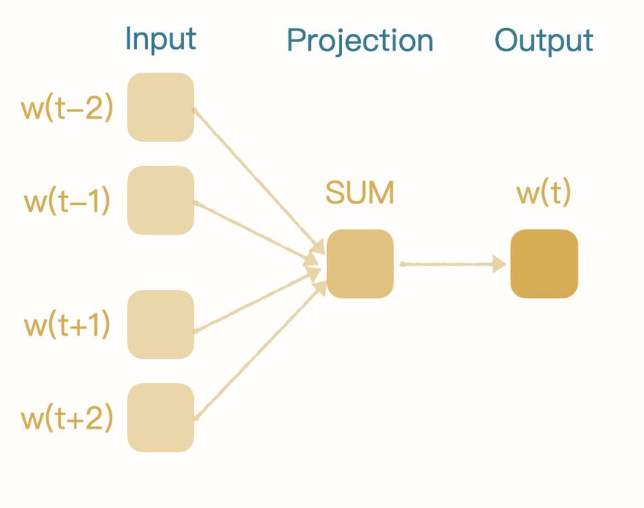
它是一种上下文预测目标词的神经网络架构,在Word2Vec中,CBOW尝试从一个词的"上下文"来预测词本身
上下文由目标词周围的一个或多个词组成,这个数目由窗口大小决定
窗口指的上下文词汇的范围,比如,窗口为10,那么模型将使用目标词前后各10个词
Skip-Gram
Skip-Gram 模型架构示意图
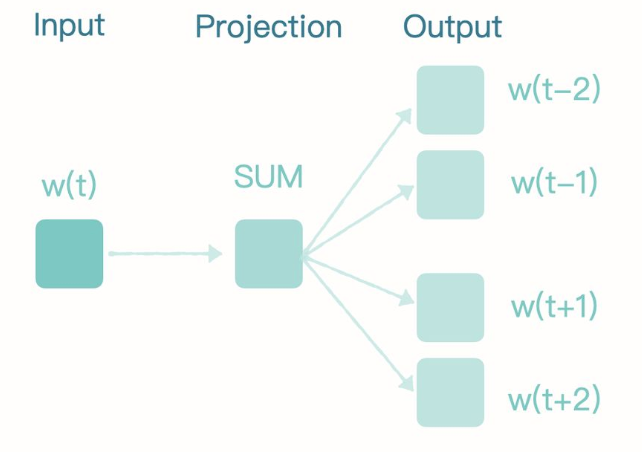
它是一种通过一个给定的目标词来预测其上下文的神经网络,和CBOW模型相反
Skip-Gram每次接受一个词作为输入,并预测其周围的词,这使其在处理较大数据集和捕获罕见短语时表现更出色
构建Word2Vec模型
数据收集和预处理
这里采用公开的 微博内容数据集
文本预处理:数据加载 --> 去除停用词 --> 分词等
停用词: 在自然语言文本中非常常见的单词,它们通常不携带特定含义,例如“the”、“a”、“an”、“in”等。在文本分析中,这些词语可能会干扰模型的训练效果,因此需要将它们从文本中移除。
import jieba
import xml.etree.ElementTree as ET
# 读取XML文件并解析
file_path = 'data.xml'
tree = ET.parse(file_path)
root = tree.getroot()
# 获取所有<article>标签的内容
texts = [record.find('article').text for record in root.findall('RECORD')]
print(len(texts))
# 停用词列表,实际应用中需要根据实际情况扩展
stop_words = set(["的", "了", "在", "是", "我", "有", "和", "就"])
# 分词和去除停用词
processed_texts = []
for text in texts:
if text is not None:
words = jieba.cut(text)
processed_text = [word for word in words if word not in stop_words]
processed_texts.append(processed_text)
# 打印预处理后的文本
for text in processed_texts:
print(text)
使用ET在解析xml文件时,xml默认不识别HTML实体的,需要将¦替换成¦
以及将<fff> 删除掉
训练模型
这里使用gensim库,它提供了简洁的 API 来训练 Word2Vec模型
pip install gensim
这里采用CBOW模型。
vector_size参数设置了词向量的维度,window参数设置了上下文窗口的大小,min_count参数设置了词频的最小阈值,workers参数设置了训练的线程数,sg=1表示使用Skip-Gram架构,sg=0表示使用CBOW架构
from gensim.models import Word2Vec
# 训练Word2Vec模型
model = Word2Vec(sentences=processed_texts, vector_size=100, window=5, min_count=1, workers=4, sg=0)
# 保存模型
model.save("model/word2vec/word2vec.model")
执行结果:

生成三个文件:
- word2vec.model:主模型文件,包含了模型的参数、词汇表等信息。不仅存储了模型的架构信息,还包括了词汇频率、模型训练状态等。这个文件是加载完整模型所必需的。
- word2vec.model.wv.vectors.npy:这个文件存储了模型中所有词汇的词向量。Word2Vec模型通过学习这些词向量来捕捉词语之间的关系。.npy是NumPy数组的文件格式,这意味着这些向量是以NumPy数组的形式存储的,可以高效地加载和处理。
- word2vec.model.syn1neg.npy:这个文件存储的是训练过程中使用的负采样权重。当设置Word2Vec模型的negative参数大于0时,启用负采样来优化模型的训练过程。这个文件中的权重是模型训练中用于负采样的部分,对于模型的学习和生成词向量至关重要。
评估与应用
模型训练完成后,可以加载加载模型看下效果:
from gensim.models import Word2Vec
# 加载模型
model = Word2Vec.load('models/word2vec/word2vec.model')
# 查看模型
print(model)
print("模型加载完成")
# 使用模型
# 获取一个词向量
print(model.wv['娱乐'])
# 找最相似的词
similar_words = model.wv.most_similar('娱乐', topn=5)
print(similar_words)
执行结果:

如何科学评估
- 词相似度计算:通过比较模型生成的词与人工标注的词的相似度,来评估模型,一致性越高,说明效果越好。常用的数据集包括WordSim-353、SimLex-999等。
- 词类比计算:评估模型在解决“词A之于词B如同词C之于什么”这类问题的能力,比如,北京之于中国如同巴黎之于什么?
- OOV词比率:评估数据集中有多少词对因为包含未知词(模型词汇表外的词)而被排除在评估之外的比率。理想情况下,OOV率应该尽可能低,以确保评估结果能更全面地代表模型的性能。
- 定性分析:对于给定的词汇,查看模型认为与其最相似的其他词汇,判断这些相似词是否符合预期。
- 实际应用:将Word2Vec模型应用到具体的下游任务,如文本分类、情感分析、实体识别等,观察模型表现的提升。通过比较使用Word2Vec词向量前后的任务表现,可以间接评估Word2Vec模型的有效性。
模型的优缺点
- 优点
- 词嵌入质量高:Word2Vec能够学习到富含语义信息的高质量词向量,使语义上相近的词在向量空间中也相近。
- 捕捉多种语言规律:Word2Vec能够捕捉到一定的语法和语义规律,比如词类比:男人之于女人如同国王之于王后。
- 效率高:相比于早期的基于矩阵分解的词嵌入方法,Word2Vec的训练效率更高,尤其是在处理大规模语料库时。
- 可解释性:Word2Vec模型学习到的词向量具有一定的可解释性,可以通过向量运算进行词之间的关系探索。
- 缺点
- OOV问题:Word2Vec模型只能对其训练期间见过的词汇生成向量。对于新出现的或者罕见的词汇,模型无法直接提供词向量(尽管可以通过一些技巧进行处理)。
- 词义多样性:Word2Vec为每个词汇生成一个唯一的向量,因此无法直接处理一个词多种含义的情况,也就是多义词问题。
- 依赖于大量文本数据:为了训练出高质量的词向量,Word2Vec需要大量的文本数据。在数据量较小的情况下,模型的效果可能会受限。
- 上下文独立:Word2Vec生成的词向量是静态的,不考虑词在特定句子中的上下文。这与后来的上下文相关的词嵌入模型,如ELMo、BERT等形成对比。
- 缺乏层次化表示:Word2Vec提供的是词汇级别的向量表示,缺乏更细致的语法和语义结构信息,这些在一些复杂的NLP任务中可能是必需的。
应用场景及案例
Word2Vec模型因为能够捕捉到词语和词语之间复杂的语义语法关系,所以在NLP任务中被广泛使用。
- 计算文本相似度:比较文本中词向量的平均值或加权平均值,可以用于文档分类、推荐系统中相似项目的检索,或者在法律文档、学术论文等领域内查找相关内容。
- 情感分析:尤其是社交媒体平台,用Word2Vec模型来识别用户评论、帖子或新闻报道中的情绪态度。
- 机器翻译:Word2Vec可以用来生成源语言和目标语言的词向量,通过这些向量,可以改进翻译模型的性能,尤其是在处理罕见词或短语时,Word2Vec能够提供更加丰富的语义信息。
- 搜索引擎优化:在搜索引擎中,Word2Vec可以用来理解用户查询的意图,并提高搜索结果的相关性。通过分析查询和文档内容的词向量相似度,搜索引擎能够提供更准确、更贴近用户意图的搜索结果。
- 内容推荐系统:在推荐系统中,Word2Vec可以用来分析用户的阅读或购买历史,并推荐语义上相近的产品或内容。这种基于内容的推荐方式能够提供更加个性化的推荐,提高用户满意度和参与度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号