
DFA算法
在一些有评论交流功能的系统中,我们经常可以看到有敏感词过滤的功能,而敏感词一般是有成千上万个的,都存储在数据库当中,而我们要替换掉敏感词的话就需要考虑到效率的问题。
如果像下面这样遍历整个表一一比对替换效率是十分缓慢的:
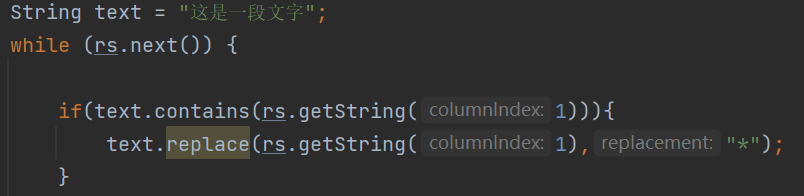
所以这里就引入了一种结构; 例如敏感词表中有三条敏感词数据。分别是:退订回M、退回、回复。我们将它们形成如下的结构

这个时候我们再进行查找替换;假如有这样一句话:“我们退回复123awyd”
首先,”我们“两个字在结构中不存在,继续往下查找,找到“退”这个字,就可以排除掉其它字开头的敏感词数据了,缩小了查找范围,接下来继续往下查找,找到“回”字,又缩小了查找的范围,再往下查找,下一个字是“复”,不是敏感词,这时候我们要退回到“回”这个字进行查找,并且是从整个结构中进行查找,我们找到了“回复”;替换掉。
接下来用代码把敏感词库形成这样的结构:这里使用HashMap来存储。

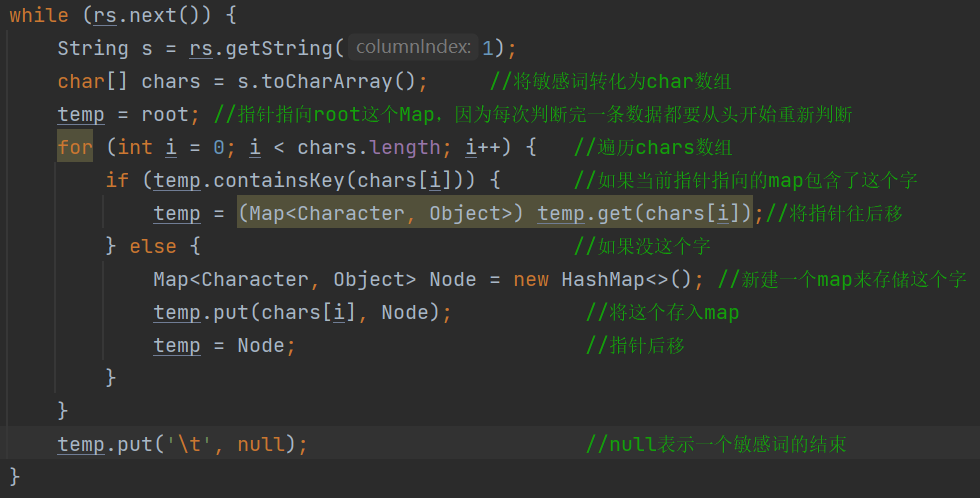
最后 我认为,这种结构的精髓在于,每次我们查找都可以将查找范围缩小,在这个缩小的范围内再不断进行查找,每次都是在一个有效的范围内查找,大大增加了查找的效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号