
通常学习器在训练集上的误差称为“训练误差”或“经验误差”,在新样本上的误差称之为“泛化误差”。显然,我们想得到泛化误差小的学习器。然而我们事先不知道新样本是什么,实际上能做的是努力使经验误差最小化。在很多情况下我们可以学习到一个经验误差很小的,在训练集上表现很好的学习器,但这是不是我们想要的学习器呢?遗憾的是,这样的学习器在多数情况下都不好。我们实际希望的是在新样本上能表现得很好的学习器,为了达到这个目的,应该从训练样本中尽可能的学习出适用于所有潜在样本的“普遍规律”,这样才能在遇到新样本时做出正确的判断。然而,当学习器把训练样本学的“太好”的时候,很可能已经把训练样本自身的一些特点也当做了所有潜在样本都会有的一般性质,这样就会导致泛化性能的下降,这种现象称之为“过拟合”,与之相对应的是“欠拟合”。
对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量泛化模型能力的评价标准,这就是性能度量。性能度量反应了任务需求,在对比不用模型的能力时,使用不容的性能度量往往会导致不同的评判结果,下面介绍几种不同的性能度量标准。
1.错误率和准确率
错误率和准确率是分类任务中常用的两种性能度量,即适应于二分类度量,也适用于多分类任务。错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例,对样例集D的分类错误率定义为:
精度定义则为$$acc(f;D)=\frac{1}{m}\sum_{i=1}^m\prod(f(x_i)=y_i)=1-E(f;D).$$
2.查准率,查全率与F1
错误率和准确率虽常用,但不能满足所有任务需求,如在信息检索领域中,我们经常会关心“检索出的信息有多少比例是用户感兴趣的”“用户感性趣的信息中有多少被检索出来了”,在统计学中分别对应“查准率”和“查全率”。
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为如下结果的“混淆矩阵”所示:
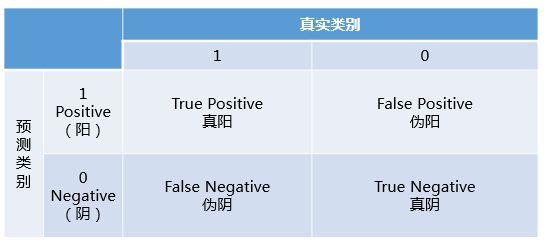
由此引出的查准率,查全率两个概念:
查准率和查全率是一对矛盾的变量,一般来说,查准率越高时,查全率往往偏低;而查全率高时,查准率往往偏低。例如,若希望把好瓜尽可能的多选出来,则可通过增加选瓜的数量来实现,如果将所有的西瓜都选上,那么所有的好瓜也就必然被选上了,此时的查全率为1,但是查准率肯定较低;若希望选择的瓜中好瓜的比例高,那么只挑选最优把握的瓜,但这样难免会漏掉不少好瓜,使得查全率很低。
F1是基于P和R的调和平均值,定义为:\(\frac{1}{F_1}=\frac{1}{2}(\frac{1}{P}+\frac{1}{R})\),是一种在查全率和查准率之间的权衡。
在一些应用中,对查全率和查准率的重视程度不一样。例如在推荐用户商品的过程中,希望尽可能的少打扰用户更希望推荐用户感兴趣的,这时查准率较为重要;而在逃犯追踪过程中希望尽可能的少漏掉逃犯,这时的查全率就更为重要,F1的更一般形式--\(F_\beta\),能让我们对查准率和查全率有不同的偏好。定义为\(\frac{1}{F_\beta}=\frac{1}{1+\beta^2}*(\frac{1}{P}+\frac{\beta^2}{R})\).
3 ROC和AUC
与上一节的定义不同,本节定义了True Positive Rate(真阳率),False Positive Rate(伪阳率)两个概念:
TPR与上一节的查全率其实是一个概念,TPR的意义是在所有的真实类别为1的样本中,预测类别为1的比例。FPR的意义是所有真实类别为0的样本中,预测类别为1的比例。
很多学习器是为测试样本产生一个实值或概率预测,然后将这个预测值与阈值做比较,若大于阈值则分类为正,否则分类为负。在不同的任务中,我们可以根据任务需求来采样不同的截断点,例如若我们更重视“查准率”,则可选择排序中靠前的位置进行截断,如果我们更重视查全率那么阈值就设小一点,如果我们更重视查准率那么阈值就设大一些。因此,概率排序本身的质量好坏,体现了综合考虑学习器在不同任务下的“期望泛化性能”的好坏,ROC曲线则是从这个角度出发来研究学习器泛化性能的有力工具,ROC的全称是“受试者工作特征”(Receiver Operating Characteristic)曲线,横轴是假正例率,纵轴是真正例率。
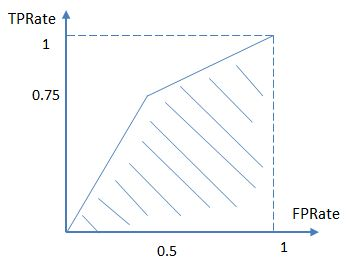
绘图过程很简单:给定m个正例和n个反例,根据学习器结果对样例进行排序,先把阈值设为最大,这样所有的样例都预测为反例,此时的真正例率和假正例率都为0,在坐标点(0,0)处,然后将分类阈值依次设为每个样例的预测值,即依次将每个样例设为正例,直到所有的样例都被预测为正的,此时的真正例率和假正例率都为1,坐标点为(1,1)。
在进行学习器选择的时候,若一个学习器的曲线完全把另一个学习器的曲线包围,则可断言后者优于前者;若两个学习器的曲线交叉时,则难以判断两个模型的孰优孰劣,此时如果非要进行判断,则较为合理的判据是比较ROC曲线下的面积,即AUC(Area Under ROC Curve)。
最后说说AUC的优势,AUC的计算方法同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。例如在反欺诈场景,设非欺诈类样本为正例,负例占比很少(假设0.1%),如果使用准确率评估,把所有的样本预测为正例便可以获得99.9%的准确率。但是如果使用AUC,把所有样本预测为正例,TPRate和FPRate同时为1,AUC仅为0.5,成功规避了样本不均匀带来的问题。
4 MSE和RMSE
待添加。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号