基于Web日志挖掘的个性化推荐系统(附源码)
个性化推荐系统
实现该系统主要是使用的编程语言主要是R,然后配合css在样式上进行一定优化,使用shiny开发的一款web程序,主要实现的核心功能是基于spark的ALS算法的课程个性化推荐系统。首页界面如下图所示:
该系统中的所有课程名称,课程图片以及课程链接均从百度传课爬取进行汇总得到的,因此点击每个图片均可以跳转至该课程在百度传课的页面。
该系统中实现的主要功能有:
首页推荐。
课程搜索。
课程分类。
个性化推荐。
热点分析。
首页推荐
当一个新用户或未登录的用户进入到该学习平台时,系统无法得知用户的具体信息,因此对用户的兴趣爱好还一无所知,所以无法使用常规的推荐算法进行推荐。一般在这个时候,只是向用户推荐那些普遍反映比较好的物品之前。面对这种情况,该项目通过Web日志分析,提取浏览次数较多的课程在首页进行推荐。
首页推荐是从预处理好的数据中提取用户访问的课程ID,然后统计这些课程ID出现的次数,根据出现的次数以降续进行排序,向用户推荐最热门,也是访问次数最多的课程。
课程搜索
搜索功能可以帮助用户快速查找到所有与搜索关键字相关的课程,这些课程名称数据是使用R语言从Web日志中提取出来的,因此可以搜索出所有存在于Web日志中的课程。该搜索引擎是基于正则表达式来完成。通过grepl函数在课程数据中的课程名中进行正则表达式匹配,可以搜索到所有包含关键字的课程,并获取其序列号,当查找完成之后,将序列号集合返回。根据课程的序列号和ID号将查找到的课程显示在前端。
用户可以使用搜索功能完成课程的搜索,另外一个方面,该功能是对热点分析中的热词分析功能的一个完善,用户可以查看热词,然后使用搜索功能进行课程查看。

课程分类
课程分类主要通过人工的方法,在课程信息汇总文件中对各个课程添加标签,在前端显示时根据标签即可显示。课程分类可以帮助用户根据类别进行课程查看。该设计中包含13个类别,比如“办公”,“考试”,“外语”,“建造”,“金融”等。
在最初爬取数据的时候我并没有想到后期会有课程分类功能,所以在数据中也没有添加分类标签,所以后期数据分类表签是手动添加。
因为在百度传课爬取课程名和课程图片时,我是根据课程分类爬取的,因此在后期添加分类时也基本就是在Excel中复制,花费不了多少时间。
个性化推荐
个性化推荐是基于用户的历史访问数据进行分析计算。在该系统中的个性化推荐是基于Web日志的数据挖掘,使用Spark中的ALS机器学习算法实现。ALS算法是基于协同过滤进行课程推荐。
该推荐算法主要是基于用户和用户之间的联系进行推荐,需要的数据包括用户ID,课程ID,课程评分。但Web日志数据中并没有用户对课程的评分数据,只有用户访问的课程内容,因此该系统使用用户观看课程视频的次数作为对该课程的评分。
本文从Web日志数据中统计出每个用户观看每个视频的次数,根据用户对课程的访问次数来反映用户对该课程的喜欢程度,观看次数越多越喜欢,反之则不喜欢。ALS算法可以根据其喜欢的课程视频发现相似用户,相似用户各自喜欢的视频之间必有交集,再分析相似用户的喜欢的课程视频,去除用户已经看过的课程视频来对其进行推荐。由此可知,该算法是根据其他已有的用户偏好来预测用户对其未观看视频的评分或喜欢程度,对新用户无法进行个性化推荐。

其中用户信息保存在MySQL数据库中,用户在登录时通过访问数据库,对账户和密码进行检查。
在另外一方面,因为该日志是自己使用脚本自动生成了20万行,所以在这里推荐的效果并不是很明显。
热点分析
热点分析包含两个部分:热词分析和地域分析。
热词分析
首先Web日志数据中提取课程名称,使用jiebaR扩展包进行分词。分词时,需要针对该系统建立课程词典和停用词库,因为Web日志中的课程名包含一些专用名词,比如“一带一路”,使用系统词典,它会被切分成两个词:“一带”和“一路”,另外也包含了大量的停用词,比如“的”,“是”等。通过这种方式,可以非常有效地提高分词的准确性。
热词分析是向用户推荐一些关键字,用户可以通过搜索功能进行搜索查看,这也是一种潜在的推荐方法。

地域分析
该功能模块是从Web日志提取用户的访问IP。通过爬虫,使用Data Science Toolkit网站提供的API,根据IP可以获取地理位置。根据地理坐标,使用REmap扩展包的remapH函数进行地理数据可视化,REmap扩展包可以绘制出非常优秀的地理热图,迁移图。
Data Science Toolkit提供的API返回的结果是JOSN形式存储的,需要使用正则表达式对其进行处理。R语言正则表达式gsub函数可以完成正则表达的替换。该API返回的结果包括国家,城市,运营商,地理坐标等。通过观察数据可以发现仅地理坐标为数字类型,其余均为字符串类型。因此使用网络爬虫获取到的数据处理过程比较简单,可以直接将非数字类型的字符串替换为空,替换之后剩余的均为数字类型,也就是经度和纬度。不过这个API现在好像直接访问不了,估计需要FQ才能使用。
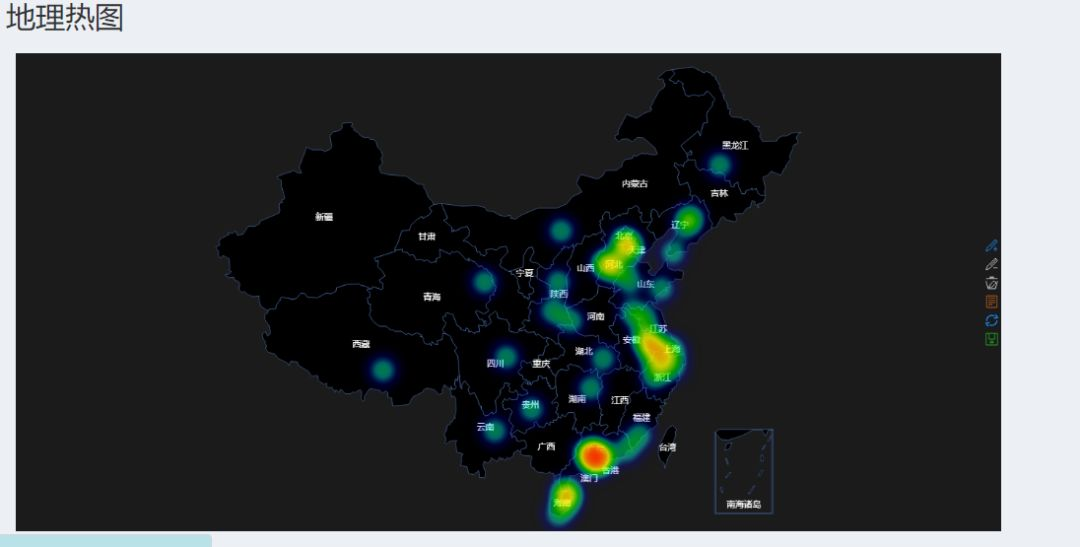
不过在这里我需要说明的是该地理热图是通过REmap包绘制的,但由于REmap包的css和shiny的css有冲突,导致系统界面出现一些故障,因为我是将地理热图保存成图片显示的。
以上就是我在该系统中实现的具体功能,如有疑问,欢迎在评论区留言讨论,如果有必要我会再写几篇分别具体对每个小功能进行详细的解释和介绍。
如果需要具体程序代码请点击阅读原文访问我的GitHub进行查看和下载,同时欢迎fork,感谢Star。
☞ 推荐阅读 ☜
1.基于Spark ALS算法的个性化推荐
2.R语言:使用REmap绘制超炫酷的地图
3.我把我用R写的第一个爬虫就献给了国家
4.正则表达式
5.爬虫|正则表达式提取腾讯教育新闻链接及图片链接
6.初识sparklyr—电影数据分析
github:https://github.com/hellowangheng/RecommendationSystem
转载请注明:
作者:王亨
公众号:数据志
原文链接:http://blog.csdn.net/wzgl__wh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号