
如何进行特征选择
前言
这是百度的周末AI课程的第三讲。主要讲的是如何进行特征选择,分成两部分的内容,第一部分是特征选择的理论,第二部分是代码。
理论部分:
一个典型的机器学习任务是通过样本的特征来预测样本所对应的值。特征过多会导致模型过于复杂,从而导致过拟合;而特征过少则会导致模型过于简单,从而导致欠拟合。事实上,如果特征数大于样本数,那么过拟合就不可避免。
特征数比较少的时候,我们需要增加特征。增加特征方法很多:依照经验;利用已有算法提取特征(比如多项式回归)。在现实中,我们更加注重的是减少特征。需要被减少的特征主要有两种:无关特征,多余特征。无关特征指的是和预测没有关系的特征;多余特征指的是和其他特征有很强相关性的特征。减少特征的意义主要有三点:1.降低过拟合;2.使得模型具有更好的解释性;3.可以加快模型训练的时间,获得更好的性能。
实际中我们很难从经验上判断特征是否和预测相关,也很难确定特征之间的相关性。因此我们需要利用工程和数学上的方法进行科学的特征选择。目前特征选择的方法主要可以分成三类:过滤法(fliter),包裹法(wrapper),嵌入法(embedding)。
过滤法:
过滤法只用于检验特征向量和目标向量的相关度,不需要任何的机器学习算法,不依赖于任何模型。过滤法只需要根据统计量进行筛选:我们根据统计量的大小,设置合适的阈值,将低于阈值的特征剔除。
相关系数是一种典型的过滤法。相关系数描述了变量之间的相关性。它是由变量之间协方差和变量的方差来定义的。具体的定义方式如下:


包裹法:
包裹法采用的是特征搜索的办法。他的基本思路是,从初始特征集合中不断的选择子集合,根据学习器的性能来对子集进行评价,直到选择最佳的子集合。
常见的包裹法有:穷举法(适合特征比较少的情况,特征多的时候易发生组合爆炸);随机法。随机法有很多种实现方式比如LV算法,贪心算法。不过我们一般使用贪心算法,因为LV算法在特征比较多的时候,开销依旧很大。贪心算法也有几种不同的实现方式:
1.前向搜索。在开始时,按照特征数来划分子集,每个子集只有一个特征,对每个子集进行评价。然后在最优的子集上逐步增加特征,使模型性能提升最大,直到增加特征并不能使模型性能提升为止。
2.后向搜索。在开始时,将特征集合分别减去一个特征作为子集,每个子集有N—1个特征,对每个子集进行评价。然后在最优的子集上逐步减少特征,使得模型性能提升最大,直到减少特征并不能使模型性能提升为止。
3.双向搜索。就是前向搜索和后向搜索的结合。
4.递归剔除。反复的训练模型,并剔除每次的最优或者最差的特征,将剔除完毕的特征集进入下一轮训练,直到所有的特征被剔除,被剔除的顺序度量了特征的重要程度。
嵌入法:
过滤法不需要学习器,包裹法使用固定的学习器,而嵌入法没有显式的特征选择过程,他的特征选择是在训练学习器的过程中完成的。
L1正则化和决策树算法是典型的嵌入式特征选择算法。L1正则化将某些特征的权重系数降为0,那就说明这些特征不重要,不需要被模型所训练【又看到了一种L1正则化的新解释】。决策树也是典型的嵌入法。因为决策树是利用一个特征进行分类,我们在生成决策树的过程就是挑选特征的过程,并且根据特征的不同取值构建子节点,直到特征没有分类能力或者很小,就停止生成节点。
参考链接:https://mp.weixin.qq.com/s/169d2yndhuAeafMKtEviyw
spearman系数:
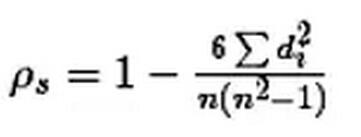
本文所说的相关系数又叫做Pearson相关系数,实际上,Pearson相关系数能被看作夹角余弦值的重要前提是数据的中心化,而中心化的思想来源于高斯分布。所以Pearson相关系数更多的是测量服从正态分布的随机变量的相关性,如果这个假设并不存在,那么可以使用spearman相关系数。
• 过滤法应用于回归问题,还可以采用互信息法(Mutual Information ),应用分类问题则可以使用卡方检验(Chi-Squared Test )。
• 我们将多个决策树集成起来,会获得随机森林(Random Forests ),与决策树一样,它可以在决定类别时,评估特征的重要性,从而实现特征选择的作用.xgboost也会起到类似的作用。
• 深度学习具有自动学习特征的能力,而特征选择是机器学习非常重要的一环,这也是深度学习能取得重大成功的原因之一。
代码部分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号