
【Python数据分析】Python3操作Excel-以豆瓣图书Top250为例
本文利用Python3爬虫抓取豆瓣图书Top250,并利用xlwt模块将其存储至excel文件,图片下载到相应目录。旨在进行更多的爬虫实践练习以及模块学习。
工具
1.Python 3.5
2.BeautifulSoup、xlwt模块
开始动手
首先查看目标网页的url: https://book.douban.com/top250?start=0, 然后我尝试了在代码里直接通过字符串连接仅改变”start=“后面的数字的方法来遍历所有的250/25 = 10页内容,但是后来发现不行,那样的话出来的永远是第一页,于是通过浏览器的F12开发者工具检查,发现start是要post上去的,如下图:
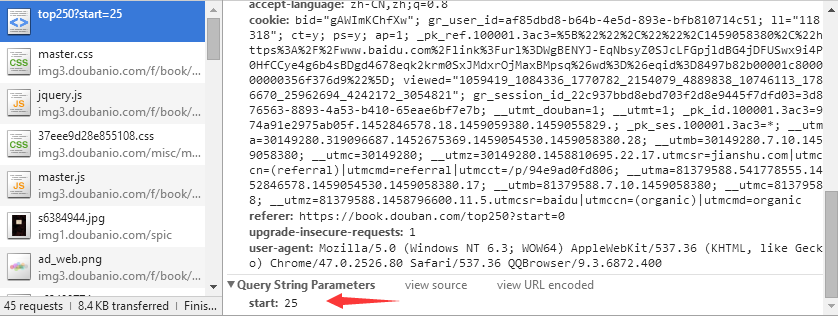 (图1)
(图1)
所以建立一个postData的dict:
postData = {"start": i} #i为0,25,...225
每次将其post上去即可解决返回都是第一页的问题。
分析网页可知,一本书的罗列信息以及要爬取的点如下图:
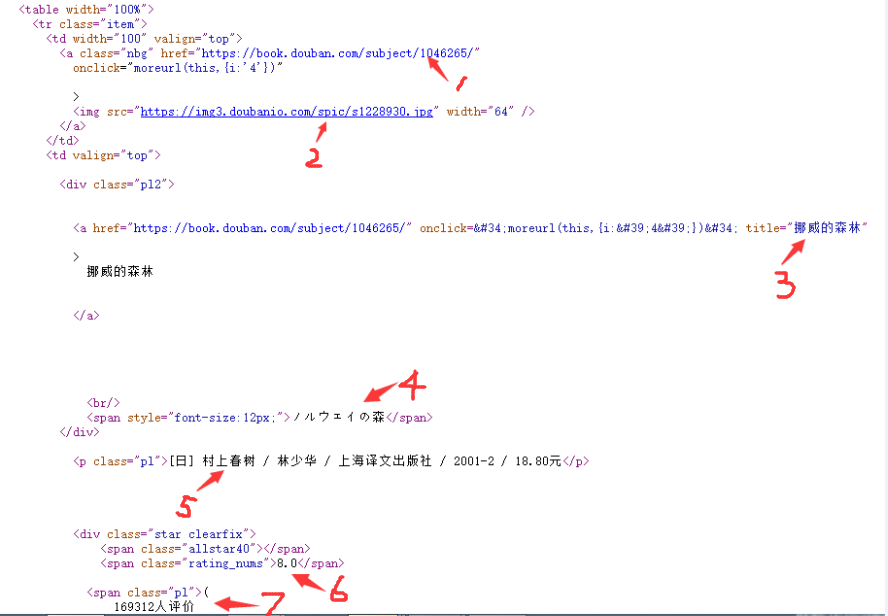 (图2)
(图2)
从上到下需要爬取的信息有:
1.图书链接地址
2.封面图片链接 我到时候会将此链接打开,下载图片到本地 (download_img函数)
3.书名 要注意的是这里书名取title的内容而不去a标签中的string信息,因为string信息可能包含诸如空格、换行符之类的字符,给处理造成麻烦,直接取title格式正确且无需额外处理。
4.别名 这里主要是副标题或者是外文名,有的书没有这项,那么我们就写入一个“无”,千万不可以写入一个空串,否则的话会出现故障,我下面会提到。
5.出版信息 如作者、译者、出版社、出版年份、价格, 这也是重要信息之一,否则有多本书名字一致可能会无法分辨
6.评分
7.评价人数
除此之外,我还爬取一个“标签”信息,它在图书链接打开之后的网页中,找到它的位置如下:
 (图3)
(图3)
爬到标签以后将它们用逗号连接起来作为标签值。
好了,既然明确了要爬的指标,以及了解了网页结构以及指标所在的html中的位置,那么就可以写出如下代码:
geturl = url + "/start=" + str(i) #要获取的页面地址
print("Now to get " + geturl)
postData = {"start":i} #post数据
res = s.post(url,data = postData,headers = header) #post
soup = BeautifulSoup(res.content,"html.parser") #BeautifulSoup解析
table = soup.findAll('table',{"width":"100%"}) #找到所有图书信息的table
sz = len(table) #sz = 25,每页列出25篇文章
for j in range(1,sz+1): #j = 1~25
sp = BeautifulSoup(str(table[j-1]),"html.parser") #解析每本图书的信息
#print(sp.div)
imageurl = sp.img['src'] #找图片链接
bookurl = sp.a['href'] #找图书链接
bookName = sp.div.a['title']
nickname = sp.div.span #找别名
if(nickname): #如果有别名则存储别名否则存’无‘
nickname = nickname.string.strip()
else:
nickname = "None"
#print(type(imageurl),imageurl)
#print(type(bookurl),bookurl)
#print(type(bookName),bookName)
#print(type(nickname),nickname)
notion = str(sp.find('p',{"class":"pl"}).string) #抓取出版信息,注意里面的.string还不是真的str类型
#print(type(notion),notion)
rating = str(sp.find('span',{"class":"rating_nums"}).string) #抓取平分数据
nums = sp.find('span',{"class":"pl"}).string #抓取评分人数
nums = nums.replace('(','').replace(')','').replace('\n','').strip()
nums = re.findall('(\d+)人评价',nums)[0]
#print(type(rating),rating)
#print(type(nums),nums)
download_img(imageurl,bookName) #下载图片
book = requests.get(bookurl) #打开该图书的网页
sp3 = BeautifulSoup(book.content,"html.parser") #解析
taglist = sp3.find_all('a',{"class":" tag"}) #找标签信息
tag = ""
lis = []
for tagurl in taglist:
sp4 = BeautifulSoup(str(tagurl),"html.parser") #解析每个标签
lis.append(str(sp4.a.string))
tag = ','.join(lis) #加逗号
if tag == "": #如果标签为空,置"无"
tag = "None"
通过xlwt模块存入xls文件及其问题
爬取下来了以后当然要考虑存储,这时我想试试把它存到Excel文件(.xls)中,于是搜得python操作excel可以使用xlwt,xlrd模块,虽然他们暂时只支持到excel2003,但是足够了。xlwt为Python生成.xls文件的模块,而xlrd为读取的。由于我想的是直接生成xls文件,不需用到xlrd,所以先安装xlwt。
直接进入Python目录使用如下命令即可安装xlwt:
pip3 install xlwt
安装完后写出操作代码,这里同时也写入txt文件,方便比较:
#建立Excel
workbook = xlwt.Workbook(encoding='utf-8')
sheet = workbook.add_sheet('book_top250',cell_overwrite_ok=True)
item = ['书名','别称','评分','评价人数','封面','图书链接','出版信息','标签']
for i in range(1,9):
sheet.write(0,i,item[i-1])
...
for j in range(1,sz+1):
...
writelist = [i+j,bookName,nickname,float(rating),int(nums),"I:\\douban\\image\\"+bookName+".jpg",bookurl,notion,tag]
for k in range(0,9):
sheet.write(i+j,k,writelist[k])
txtfile.write(str(writelist[k]))
txtfile.write('\t')
txtfile.write(u'\r\n')
workbook.save("I:\\douban\\booktop250.xls")
...
满以为这样就可以了,但是还是出现了一些错误。
比如曾经出现了写着写着就写不下去了的情况(以下并非以上代码产生的结果):
 (图4)
(图4)
这时我把不是str的都改成str了,不该str的尽量用数字(int,float),然后又遇到了下面的情况:
 (图5)
(图5)
写到第64项又写不下去了,但是那些int,float都写完了,‘无’也是断断续续显示几个,我想,既然找不到问题,那么慢慢套吧。首先极大可能是中文编码的问题,因为我把一些可以不为str类型的都赋成非str类型以后都正确地显示了,而且上图中的显示在图片路径名那里断了,所以我让那一列都不显示,居然,成功了!
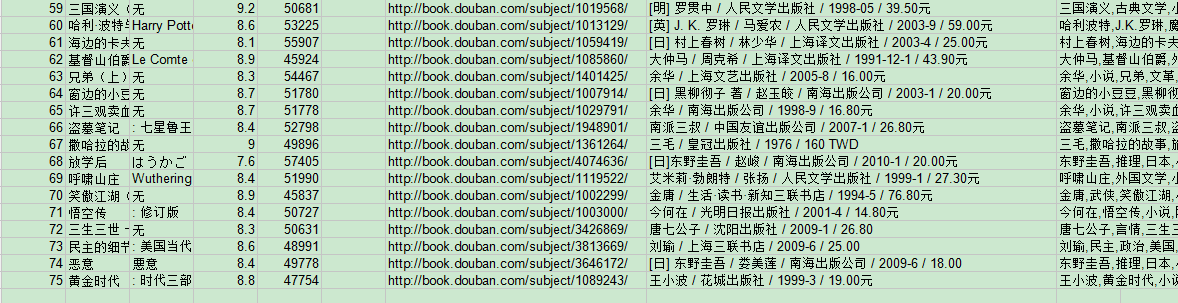 (图6)
(图6)
如图,除了不显示的那一列,其它完全正常,可以断定就是下面这里出现的错误:
writelist=[i+j,bookName,nickname,float(rating),int(nums),"I:\\douban\\image\\"+bookName+".jpg",bookurl,notion,tag]
我的图片路径那里是直接字符串拼接而成的,所以可能会有编码的错误。那么稍微改一下试试:
imgpath = str("I:\\douban\\image\\"+bookName+".jpg");
writelist=[i+j,bookName,nickname,float(rating),int(nums),imgpath,bookurl,notion,tag]
好吧,还是不行,还是出现图5的问题,但是打印在Python IDLE里面又都是正确的。
既然如此,把图片链接全部改成一样的英文试一下:
imgpath = str("I:\\douban\\image\\"+"a"+".jpg")
writelist=[i+j,bookName,nickname,float(rating),int(nums),imgpath,bookurl,notion,tag]
又是正确的:('无'已改为'None')
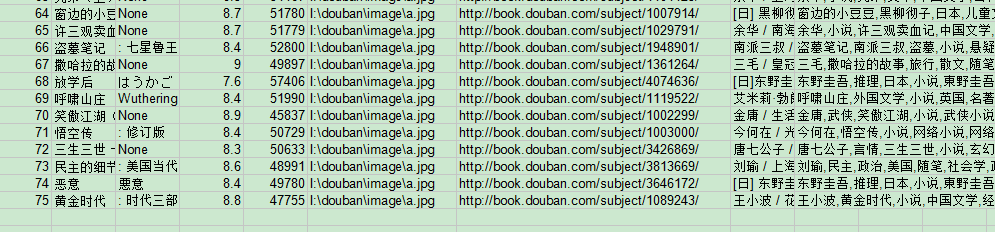 (图7)
(图7)
所以说,还是图片路径的问题,那我们索性将图片路径那列换成图片链接,采取消极应对方法,反正这项是图片链接还是图片路径无关紧要,反正图片路径里面有图片就可以了。此外我还加了一个计时的代码,计算总爬取时间,因为我觉得这样干爬太慢了,没有个将近10分钟完不成,考虑利用多线程去爬,这里先记录一下时间以观后效。然后发现还是不行!现在成了只要imageurl固定(中文也行),就能够顺利输出到xls中,否则就不行。很诡异。于是我又尝试了缩短imageurl,实验得知,当取imageurl[:-6]时是可以的,但imageurl[:-5]就不行了。后面又干脆不写入imageurl这一列,可以,不写入别名或者不写入图书链接都是正常的,但是不写入标号就不行。至今仍不得解。初步猜测莫非是写入的字符数受限制了?还得靠更多的实验才能确定。而且也说不定就是Windows下的编码问题,这又得靠在Linux下进行实验判断。所以要做的事情还很多,这里先把正确的绝大部分工作做了再说。
于是干脆不要图书地址一列,最后得出如下最终代码:


# -*- coding:utf-8 -*- import requests import re import xlwt from bs4 import BeautifulSoup from datetime import datetime import codecs now = datetime.now() #开始计时 print(now) txtfile = codecs.open("top250.txt",'w','utf-8') url = "http://book.douban.com/top250?" header = { "User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.13 Safari/537.36", "Referer": "http://book.douban.com/" } image_dir = "I:\\douban\\image\\" #下载图片 def download_img(imageurl,imageName = "xxx.jpg"): rsp = requests.get(imageurl, stream=True) image = rsp.content path = image_dir + imageName +'.jpg' #print(path) with open(path,'wb') as file: file.write(image) #建立Excel workbook = xlwt.Workbook(encoding='utf-8') sheet = workbook.add_sheet('book_top250',cell_overwrite_ok=True) item = ['书名','别称','评分','评价人数','封面','图书链接','出版信息','标签'] for i in range(1,9): sheet.write(0,i,item[i-1]) s = requests.Session() #建立会话 s.get(url,headers=header) for i in range(0,250,25): geturl = url + "/start=" + str(i) #要获取的页面地址 print("Now to get " + geturl) postData = {"start":i} #post数据 res = s.post(url,data = postData,headers = header) #post soup = BeautifulSoup(res.content.decode(),"html.parser") #BeautifulSoup解析 table = soup.findAll('table',{"width":"100%"}) #找到所有图书信息的table sz = len(table) #sz = 25,每页列出25篇文章 for j in range(1,sz+1): #j = 1~25 sp = BeautifulSoup(str(table[j-1]),"html.parser") #解析每本图书的信息 #print(sp.div) imageurl = sp.img['src'] #找图片链接 bookurl = sp.a['href'] #找图书链接 bookName = sp.div.a['title'] nickname = sp.div.span #找别名 if(nickname): #如果有别名则存储别名否则存’无‘ nickname = nickname.string.strip() else: nickname = "None" #print(type(imageurl),imageurl) #print(type(bookurl),bookurl) #print(type(bookName),bookName) #print(type(nickname),nickname) notion = str(sp.find('p',{"class":"pl"}).string) #抓取出版信息,注意里面的.string还不是真的str类型 #print(type(notion),notion) rating = str(sp.find('span',{"class":"rating_nums"}).string) #抓取平分数据 nums = sp.find('span',{"class":"pl"}).string #抓取评分人数 nums = nums.replace('(','').replace(')','').replace('\n','').strip() nums = re.findall('(\d+)人评价',nums)[0] #print(type(rating),rating) #print(type(nums),nums) download_img(imageurl,bookName) #下载图片 book = requests.get(bookurl) #打开该图书的网页 sp3 = BeautifulSoup(book.content,"html.parser") #解析 taglist = sp3.find_all('a',{"class":" tag"}) #找标签信息 tag = "" lis = [] for tagurl in taglist: sp4 = BeautifulSoup(str(tagurl),"html.parser") #解析每个标签 lis.append(str(sp4.a.string)) tag = ','.join(lis) #加逗号 if tag == "": #如果标签为空,置"无" tag = "None" writelist=[i+j,bookName,nickname,float(rating),int(nums),imageurl,bookurl,notion,tag] for k in range(0,9): if(k == 5): continue sheet.write(i+j,k,writelist[k]) txtfile.write(str(writelist[k])) txtfile.write('\t') txtfile.write(u'\r\n') workbook.save("I:\\douban\\booktop250.xls") end = datetime.now() #结束计时 print(end) print("程序耗时: " + str(end-now)) txtfile.close()
运行(7分多钟):
 (图8)
(图8)
还是断了,那就真不知道怎么办才好了。再改变方法,先写到TXT文本文件再导入到xls中,就先不管本文标题了。
运行:
2016-03-27 21:47:17.914149 Now to get http://book.douban.com/top250?/start=0 Now to get http://book.douban.com/top250?/start=25 Now to get http://book.douban.com/top250?/start=50 Now to get http://book.douban.com/top250?/start=75 Now to get http://book.douban.com/top250?/start=100 Now to get http://book.douban.com/top250?/start=125 Now to get http://book.douban.com/top250?/start=150 Now to get http://book.douban.com/top250?/start=175 Now to get http://book.douban.com/top250?/start=200 Now to get http://book.douban.com/top250?/start=225 2016-03-27 21:56:16.046792 程序耗时: 0:08:58.132643
在.txt中是正确的:
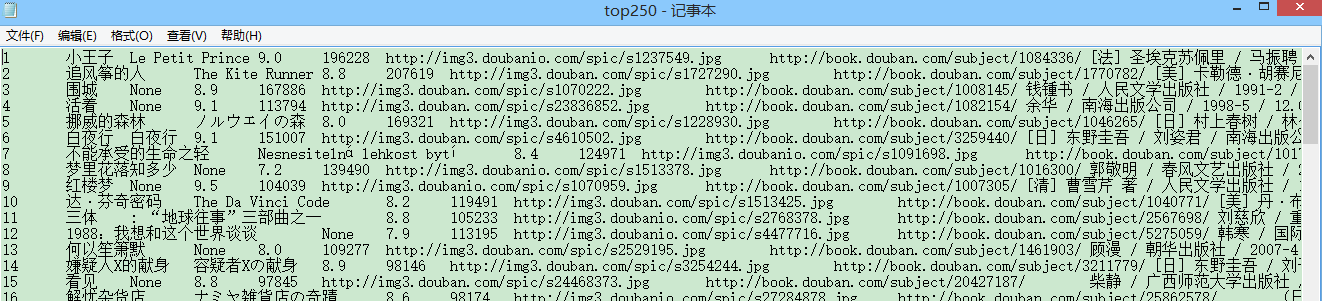 (图9)
(图9)
然后在xls文件中选择数据->导入数据即可得到最终结果:
 (图10)
(图10)
封面图片:
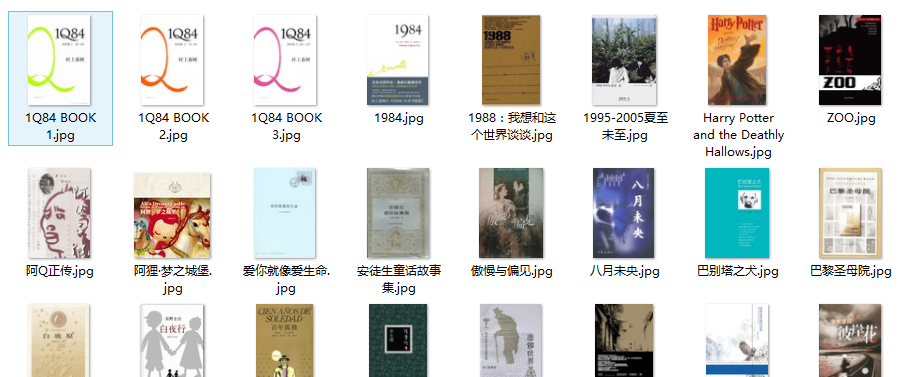 (图11)
(图11)
问题先解决到这,后面的问题有待深入研究。
后期可改进
1.采用多进程/多线程加快爬取速度
2.可考虑采用xlutis模块分多步写入到excel中
3.可考虑改换excel处理模块
3.考虑在Linux环境下进行试验
------------------------------------------------------------------------------------------------------
听人说数据分析绝大部分时间都花在数据采集与清洗,以前不怎么觉得,现在终于有一点感受了,任重道远啊..
如果您对我的方法有什么看法,欢迎留下您的评论:-)
作者:whatbeg
出处1:http://whatbeg.com/
出处2:http://www.cnblogs.com/whatbeg/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
更多精彩文章抢先看?详见我的独立博客: whatbeg.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号