WOS——Web of Science操作指南
WOS导出ciw/txt格式与csv/xlsx文件的转换
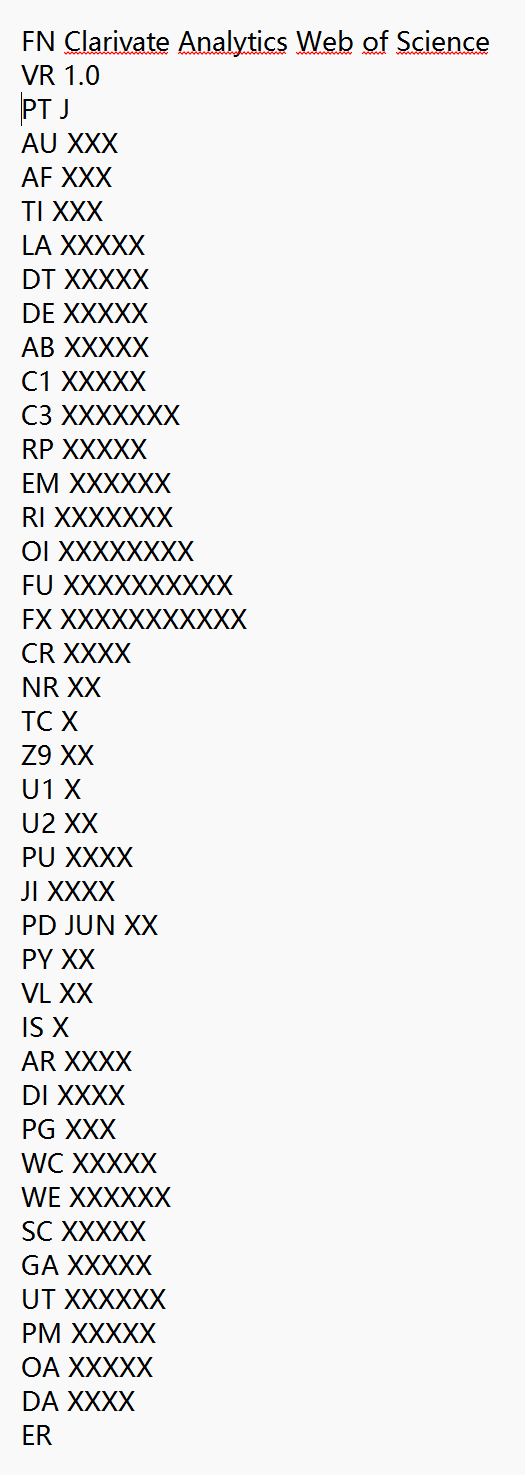
WOS导出文件结构:以FN和VR两个字段开头,多文献之间以空行划分,中间各字段为对应文献的信息,而且两字母字段标签与其内容也以空行相隔,每一篇文献记录以ER结尾,整个文件以EF结尾并与文献记录空一行。

将ciw/txt转化为xlsx文件的方法
在了解了WOS导出文件的基本结构后,可以根据字段特征进行提取处理,使用到pandas库:参照@never_mind_kk的代码实现整理文献标题、年份、作者、关键词、摘要、期刊和被引信息转入Excel中
import os
import pandas as pd
import re
from collections import Counter
# 目录路径
directory_path = r'C:\Users\1'
# 提取字段函数
def extract_field(record, field):
pattern = re.compile(f'{field} (.+)')
match = pattern.search(record)
return match.group(1).strip() if match else None
# 初始化数据列表
data = []
# 初始化频率统计的字典
keyword_frequency = Counter()
# 遍历目录中的所有txt文件
for filename in os.listdir(directory_path):
if filename.endswith('.txt'):
file_path = os.path.join(directory_path, filename)
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
records = content.split('\nER\n') # 按照记录之间的分隔符切分内容
for record in records:
title = extract_field(record, 'TI')
keywords = extract_field(record, 'DE')
year = extract_field(record, 'PY')
authors = extract_field(record, 'C1')
journal = extract_field(record, 'SO')
abstract = extract_field(record, 'AB')
references = re.search(r'TC (\d+)', record) # 使用正则表达式提取TC后面的数字
references = references.group(1) if references else None
if title and keywords and year and authors and journal and abstract and references:
authors = re.findall(r'\b[A-Z][a-z-]+\b [A-Z][a-z-]+\b', authors) # 提取作者信息
first_three_authors = ', '.join(authors[:3])
keywords_list = [kw.strip() for kw in keywords.split(';')]
# 更新频率统计字典
keyword_frequency.update(keywords_list)
data.append([title, year, first_three_authors, ', '.join(keywords_list), abstract, journal, references])
# 创建 DataFrame
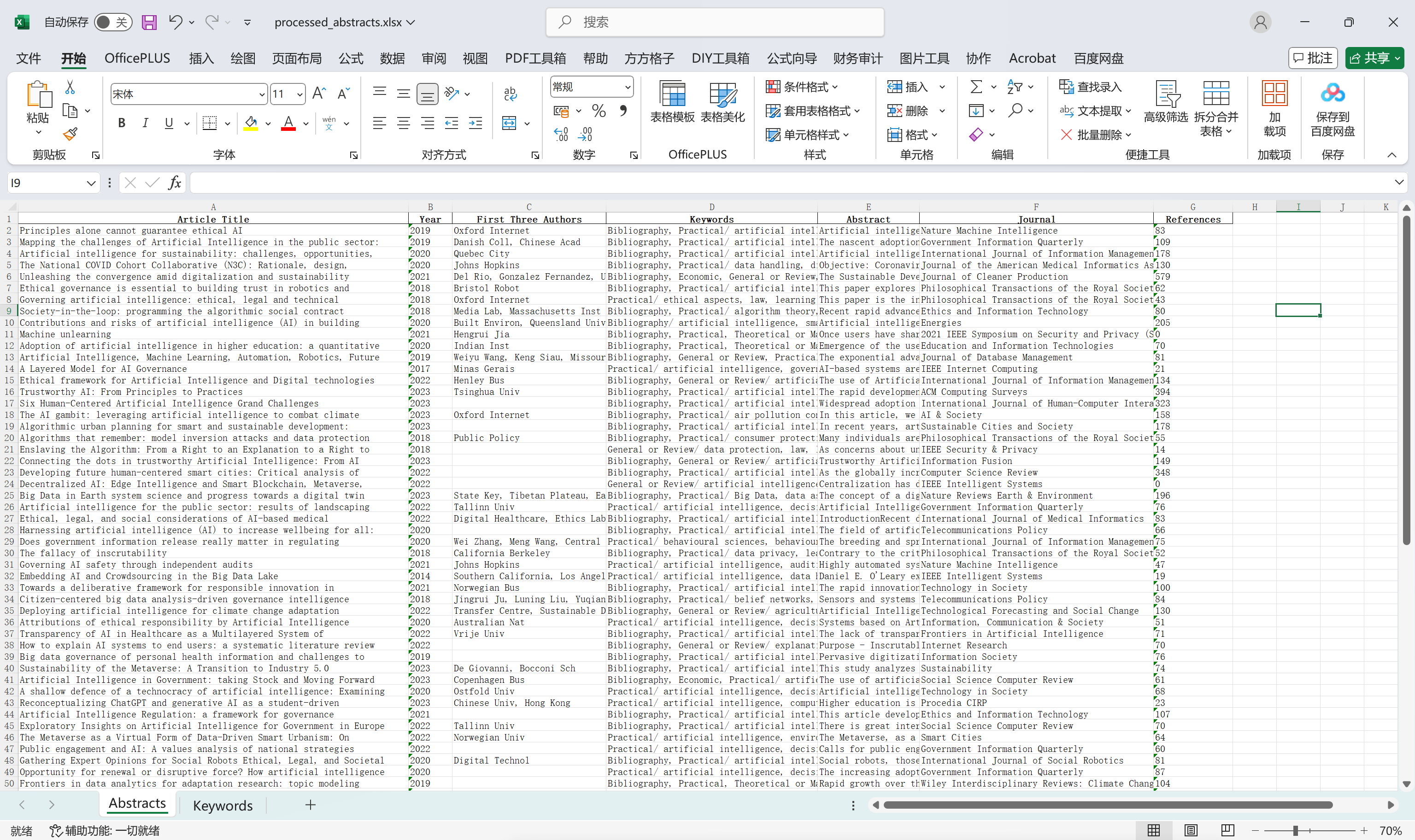
results_df = pd.DataFrame(data, columns=['Article Title', 'Year', 'First Three Authors', 'Keywords', 'Abstract', 'Journal', 'References'])
# 根据频率高低对关键词进行排序
sorted_keywords = sorted(keyword_frequency.items(), key=lambda x: x[1], reverse=True)
# 创建第二个工作表 DataFrame
keywords_df = pd.DataFrame(sorted_keywords, columns=['Keyword', 'Frequency'])
# 保存结果为Excel文件,路径为与原始文件相同的路径
excel_filename = "processed_abstracts.xlsx"
excel_path = os.path.join(directory_path, excel_filename)
# 将结果保存到Excel文件中的两个工作表
with pd.ExcelWriter(excel_path) as writer:
results_df.to_excel(writer, index=False, sheet_name='Abstracts')
keywords_df.to_excel(writer, index=False, sheet_name='Keywords')
print(f"Excel 文件已生成并保存到路径:{excel_path}。")
注1: 该方法是以检索选取WOS核心集为前提,因此在使用正则表达式提取被引TC/reference字段不为空,在提取作者信息时用的if判断可以继续下去,而如果常规搜索TC字段不存在,代码需要置换为其他标签或者删去reference作为逻辑判断。例如我自己将Reference字段换为引文数量NR,并且默认排序,实际按照搜索导出结果的默认顺序转化成xlsx文件。
注2:在运行代码过程中出现过以下的报错:
解决方法:pip install openpyxl
想详细了解openpyxl可参考@高斯小哥(原博客链接后附)

csv表格转换为wos格式数据
原博客为@长相依_sz的课程作业,将给定csv文件转换为WOS格式,可视为一种逆向的方式,实际需求可能较少,也纳入这篇博客整合。

原博客作者先进行了字段名转换和Excel表格行列转置,此处略,待处理数据变为如下:

数据处理
# process1.py
import csv
def transpose_columns(input_file, output_file):
# 读取输入文件
with open(input_file, 'r') as file:
reader = csv.reader(file)
rows = list(reader)
# 获取列数
num_columns = len(rows[0])
# 转换列
transposed_rows = []
for col_index in range(1, num_columns):
column = [row[col_index] for row in rows]
transposed_rows.append(['PT J']) # 添加起始符
transposed_rows.extend([[row[0], column[i]] for i, row in enumerate(rows)])
transposed_rows.append(['ER']) # 添加终止符
transposed_rows.append([]) # 添加空行
# 写入输出文件
with open(output_file, 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(transposed_rows)
# 示例用法
input_file = 'input.csv'
output_file = 'output1.csv'
transpose_columns(input_file, output_file)
此为输出的文件output1.csv文件:
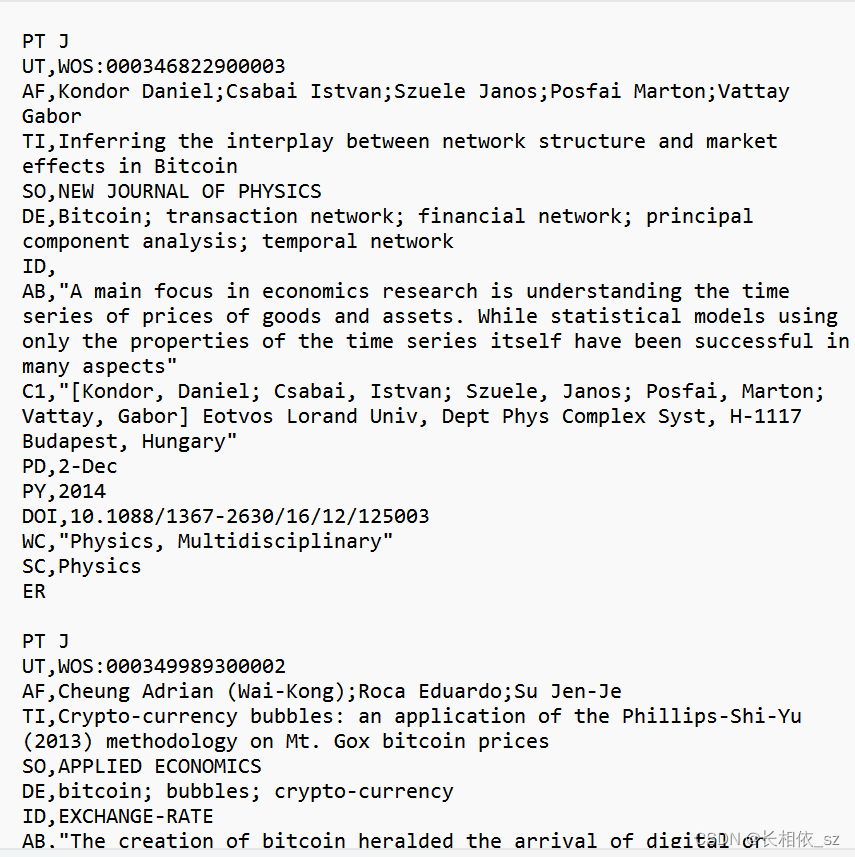
一个问题,在wos格式中,字段名和字段值之间是用空格( )隔开的,而不是结果中的逗号(,)同一文件夹下新建一个process2.py脚本,代码如下:
# process2.py
def replace_comma_with_space(input_file, output_file):
with open(input_file, 'r') as file:
lines = file.readlines()
modified_lines = []
for line in lines:
modified_line = line.replace(',', ' ', 1)
modified_lines.append(modified_line)
with open(output_file, 'w') as file:
file.writelines(modified_lines)
# 示例用法
input_file = 'output1.csv' # 也就是process1.py的输出文件
output_file = 'output2.txt'
replace_comma_with_space(input_file, output_file)
这样,就能把结果里每行的第一个逗号换成空格了。最终获得结果如下:

然后导入citespace参考:CiteSpace导入WOS数据详细步骤;另参考:【citespace】WOS的基本操作教程(数据导出、除重及可视化分析)
参考:Web of Science 数据库导出记录中各个字段的含义,WOS中批量导出文献后的文献信息统计查看,【Python】成功解决ModuleNotFoundError: No module named ‘openpyxl‘,csv表格转换为wos格式数据并导入citespace进行文献分析

 浙公网安备 33010602011771号
浙公网安备 33010602011771号