
【AI4S】Token-Mol 1.0:基于LLM的token化药物设计 - 指南
Token-Mol 1.0:基于LLM的token化药物设计
众所周知,药物研发需要经历一段极其漫长且复杂的过程。好在大型语言模型 (LLM) 在药物设计中的应用,正逐渐给这一挑战带来曙光。不过,现有基于 LLM 的方法往往难以有效地整合三维分子结构。 Token-Mol是一个仅包含 token 的 3D 药物设计模型,它将二维和三维结构信息以及分子属性编码成离散的 token。 Token-Mol 建立在 Transformer 解码器之上,并经过因果掩蔽训练,引入了专为回归任务定制的高斯交叉熵损失函数,从而在多个下游应用中实现了卓越的性能。能力方面,该模型超越了现有手段,在两个数据集上将分子构象生成性能分别提高了 10% 和 20% 以上,同时在性质预测方面比仅利用 token 的模型高出 30%。在基于口袋的分子生成中,它分别将药物相似性和合成可及性提高了约 11% 和 14%。并且,Token-Mol 的运行速度比「专家」扩散模型快 35 倍。

Wang, J., Qin, R., Wang, M. et al. Token-Mol 1.0: tokenized drug design with large language models. Nat Commun 16, 4416 (2025). https://doi.org/10.1038/s41467-025-59628-y
背景与挑战
在药物研发中,获取带注释素材集的高成本仍然是该领域发展的重大障碍。近年来,以 BERT 和 GPT 为代表的无监督学习框架的快捷发展,为化学和生物等学科引入了无监督化学和生物预训练模型。这些模型经过大规模无监督训练,学习小分子或蛋白质的表征,并随后针对特定应用进行微调。通过在大规模素材集上进行无监督学习,这些预训练模型有效地应对了与稀疏标记和分布外泛化能力欠佳相关的挑战。
大规模分子预训练模型大致可分为两大类:基于化学语言的模型和利用分子图的模型。
- 化学语言模型使用诸如简化分子输入体系 (SMILES) 或自引用嵌入字符串 (SELFIES) 等表示形式对分子结构进行编码。它们往往采用类似于 BERT 或 GPT 的训练方法。
- 基于图的分子预训练模型表现出更高的通用性。它们以图形形式表示分子,节点表示原子,边表示化学键。预训练方法包括各种技术。与基于语言的模型不同,基于图的分子预训练模型本质上含有几何信息。
这里有一个很尴尬的问题,就是但基于化学语言的大规模分子预训练模型无法处理对分子特性至关重要的3D结构信息,所以它难以胜任相关下游任务;基于图结构的预训练模型虽能整合 3D 信息却仅聚焦性质预测,同时难以与通用 NLP 模型融合。因此,当前亟需开发能克服这两类模型局限、适用于所有药物设计场景并可无缝对接通用大语言模型的新型预训练模型。
方法
本研究提出了分子预训练的大语言模型Token-Mol。为了增强与现有通用模型的兼容性,该研究采用仅基于词元的训练范式,将所有回归任务重新定义为概率预测任务。Token-Mol采用Transformer解码器架构构建,通过SMILES和扭转角词元整合关键的二维和三维结构信息。此外,在预训练过程中,利用泊松分布和均匀分布的组合随机掩码训练数据。这种策略增强了模型的填空生成能力,提高了它对各种下游任务的适应性。
为了解决仅基于词元的模型对数值敏感度有限的问题,该研究引入了高斯交叉熵(GCE)损失函数,取代了传统的交叉熵损失。这种创新的损失函数在训练过程中为每个词元分配权重,使模型能够学习数值词元之间的关系。此外,Token-Mol与其他先进的建模技术(包括微调和强化学习(RL))具有出色的兼容性。
Token-Mol在分子构象任务中,在两个数据集上生成的表现提高超过10%和20%,同时在性质预测任务方面优于其他仅基于词元的模型达30%。在基于口袋的分子生成中,相比起其他专家模型,Token-Mol分别将药物相似性和合成可及性提高了约11%和14%, 在生成速度上相较于基于扩散模型的专家模型快35倍。在模拟真实世界场景的生成中,Token-Mol提高了生成分子到达特定目标的成功率。与强化学习相结合后,模型进一步优化了生成分子的亲和力和药物相似性。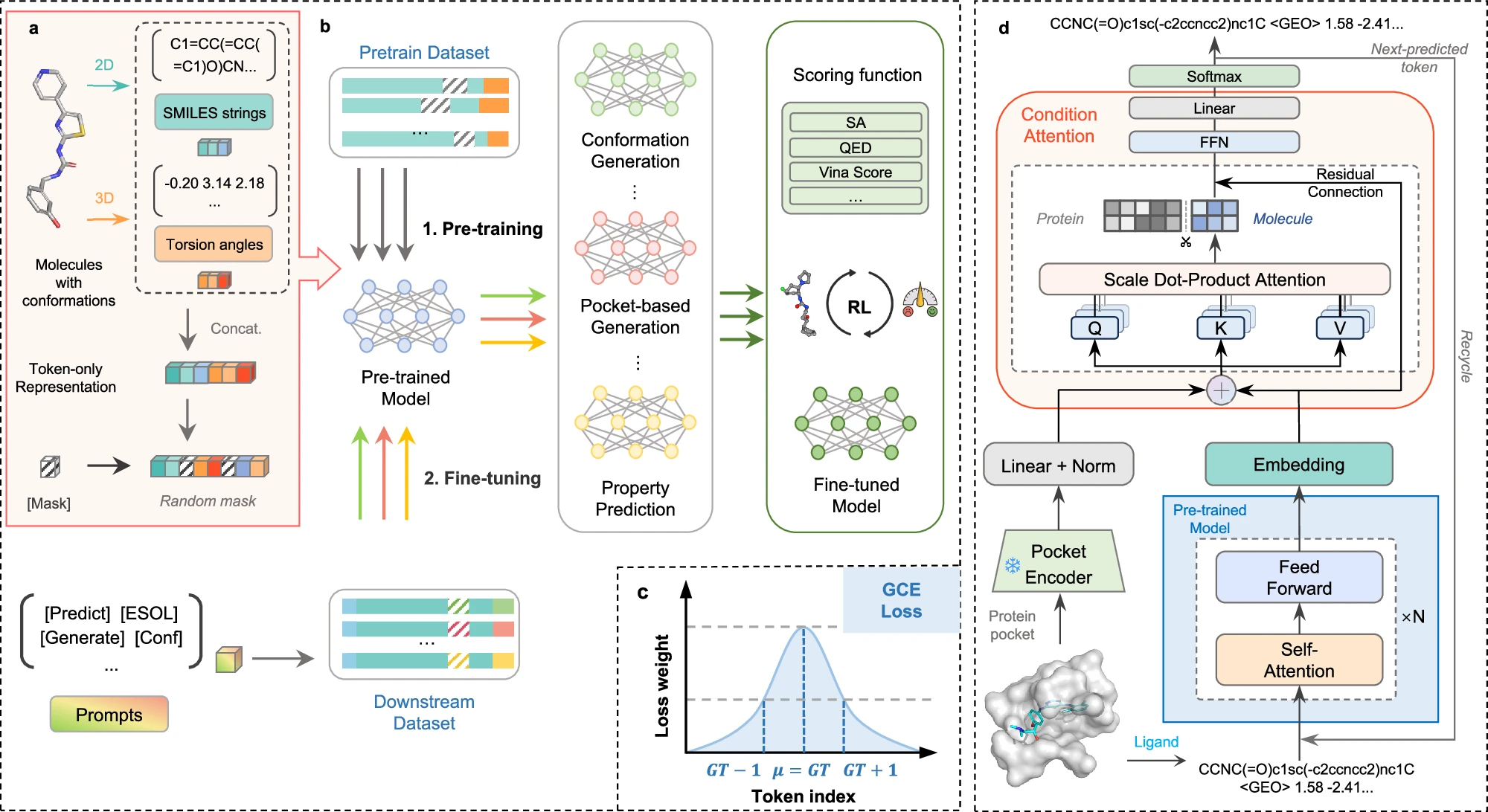
图 1. Token-Mol流程示意图
在此背景下,预训练数据集的预处理至关重要。对标准 SMILES 格式的整个分子进行深度优先搜索(DFS)遍历,以提取分子结构中嵌入的扭转角。之后,每个提取出的扭转角都会被同化为一个 token,并附加到 SMILES 字符串中。
在整个预训练阶段,研究人员会实施基于因果回归的随机因果掩蔽。预训练完成后,研究人员会对下游任务进行微调。值得注意的是,任务提示是专门为构建对话系统而设计的。这一特性显示了仅使用 token 的模型相较于其他大规模模型的一个关键优势:它们能够促进实时交互。
对于基于口袋的分子生成任务,研究人员引入了口袋编码器和融合模块,从而更好地将蛋白质口袋信息整合到模型中。同时,他们利用多头条件注意力机制,将每个自回归步骤中生成的信息完整地整合到后续迭代中。该机制将自回归过程中生成的每个 token 视为后续生成的先决条件,从而确保整个查询、键和值矩阵均源自原始序列。
,在实际应用中,就是得注意的先导化合物不仅要对靶标表现出高亲和力,还要满足一系列标准,包括高生物活性和多种良好的药理特性。这对基于口袋的分子设计任务提出了更高的要求,而训练数据集中受体-配体分子对的整合存在固有的局限性。
该模型主要利用来自蛋白质口袋的信息来生成配体分子。因此,这些生成分子的性质受到训练数据的严重影响,限制了对其生物物理和化学性质的明确控制。当需要精确调节分子特性时,这些限制尤为明显。
Token-Mol 建立在自回归语言模型架构之上,其中 token 的生成与强化学习框架中的动作相一致,从而促进了强化学习的无缝优化,从而保证获得量身定制的结果。
2.1 Token-Only建模策略
传统模型往往使用连续数值表示三维信息,而Token-Mol采用一种纯离散化表示方法,将包括分子构型(SMILES)、扭转角、性质等内容统一转化为token序列。这种方式可以直接与现有大语言模型框架兼容,便于未来与通用LLM进行集成。
2.2 Transformer解码器架构
Token-Mol基于GPT类结构,采用Transformer解码器进行自回归训练,并通过随机因果掩码(Random Causal Masking)策略提升模型的泛化能力,使其具备空填式生成能力,适用于多种分子任务。
2.3 高斯交叉熵损失函数(GCE)
为克服token-only模型对数值敏感度不足的问题,作者引入GCE损失函数,对数值token进行加权建模,从而提高模型在回归任务中的精度。
2.4 强化学习优化
在口袋配体生成任务中,引入基于奖励函数的强化学习机制,优化目标如Vina打分、QED与SA,提升生成分子的药物潜力。
2.5 任务适应机制
模型可通过微调适应于构象生成、性质预测和口袋生成等任务。并支持prompt式对话接口,具备“对话式药物设计”的原始雏形。
结果
3.1 分子构象生成
,Token-Mol在COV精确率(COV-P)指标上取得了显著提升,比Tora3D高出约11%,这表明了Token-Mol生成的分子相较于其他方法具有更高的质量。然而,与GeoDiff和Tora3D相比,Token-Mol生成的构象在召回率方面表现略低,总体排名第二。对测试集II,Token-Mol在基于精确率的两项评估指标COV-P和MAT-P上均取得了最佳成绩,分别比其他模型高出约24%和21%(表2)。就是研究人员在两个数据集上进行了评测。结果表明,对测试集I,Token-Mol在两个精确率指标上均超越了基准方法(表1)。值得注意的
表1. 模型在测试集I上的性能对比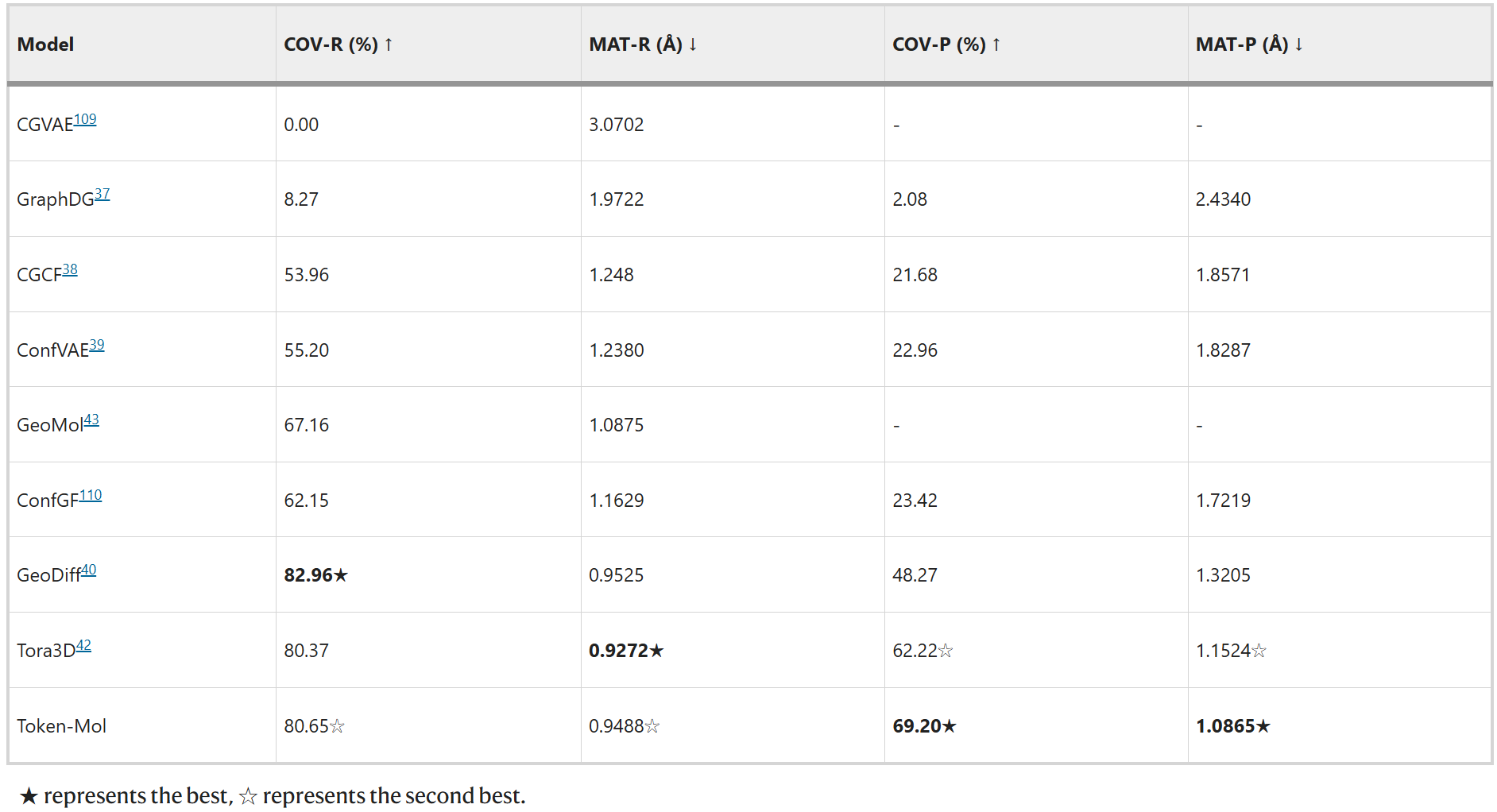
表2. 模型在测试集II上的性能对比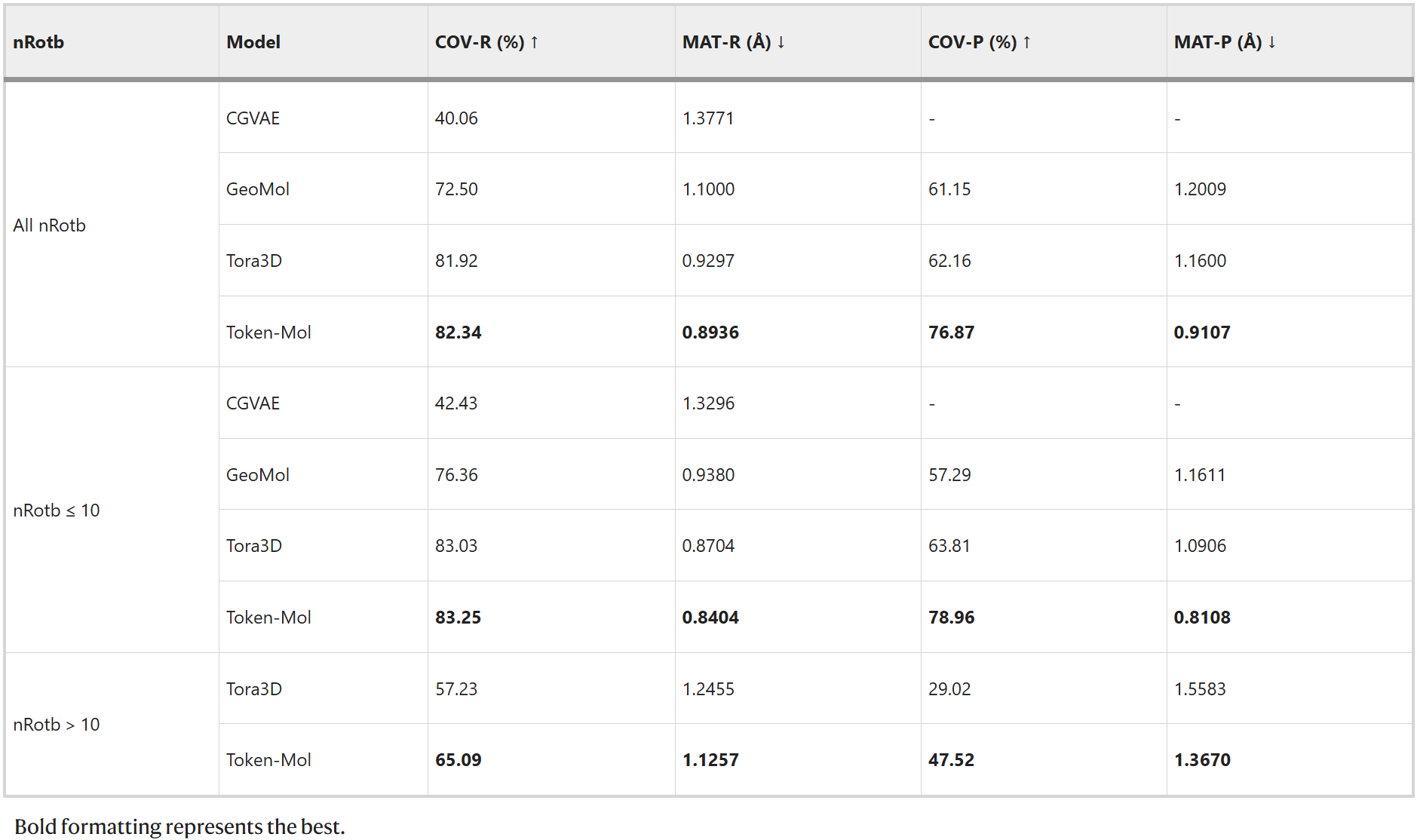
3.2 分子性质预测
分类任务
Token-Mol与五个不同类型的基线模型进行了比较:XGBoost(传统机器学习模型)、K-Bert(基于序列的模型)、Chemprop(图神经网络模型)、GEM(几何增强图神经网络模型)以及MapLight+GNN(传统机器学习与图神经网络相结合的集成模型)。如表3所示,Token-Mol在所有数据集上均表现出色,其准确率优于XGBoost和Chemprop,尽管在一定程度上落后于MapLight+GNN和GEM。
表3. 分类任务上的性能对比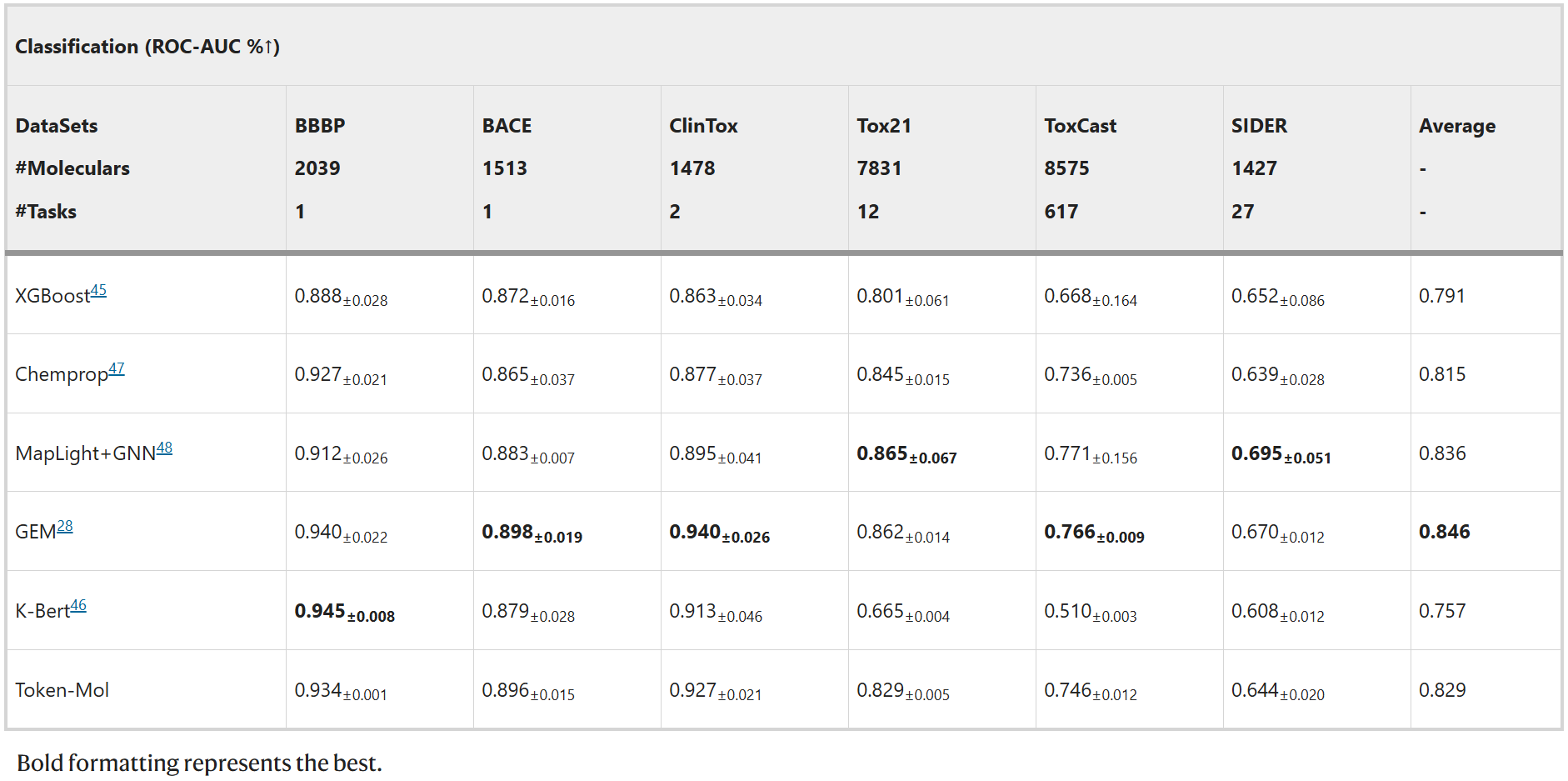
回归任务
Token-Mol在所有任务中都超越RT,平均性能提升约30%。尤其值得一提的是,Token-Mol在Aqsol数据集上构建了约50%的提升。此外,如表4所示,在Aqsol、LD50等拥有大量数据的数据集上,Token-Mol的表现与基于图神经网络的模型相近。
表4. 模型生成的分子的属性对比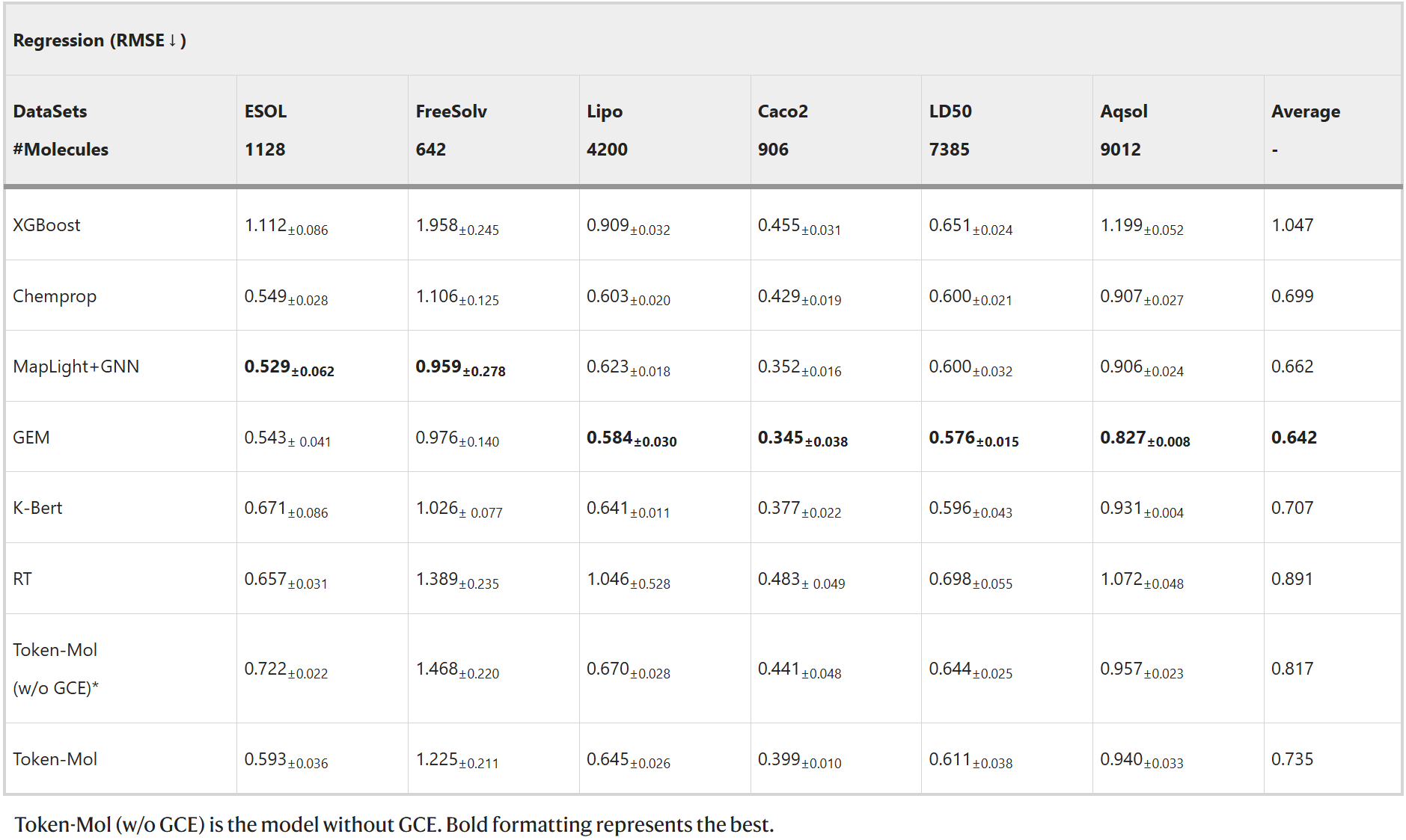
高斯交叉熵(GCE)
仅基于词元的生成模型通常在回归任务中使用交叉熵损失函数,但它们往往对数值不敏感,无法捕捉数值之间的关系。为克服这一困难,该研究针对分子性质预测中与回归相关的下游任务提出了高斯交叉熵(GCE)损失函数。为评估GCE的有效性,该研究进行了对比实验。结果表明,缺少GCE会显著降低Token-Mol在所有素材集上的性能,均方根误差(RMSE)平均增加约12%,这凸显了GCE在回归任务中的关键作用。与将单个数值分解为多个词元表示的RT相比,Token-Mol采用单个词元预测方法并结合GCE,在预测准确性和效率上都有显著提升。
蛋白口袋配体生成
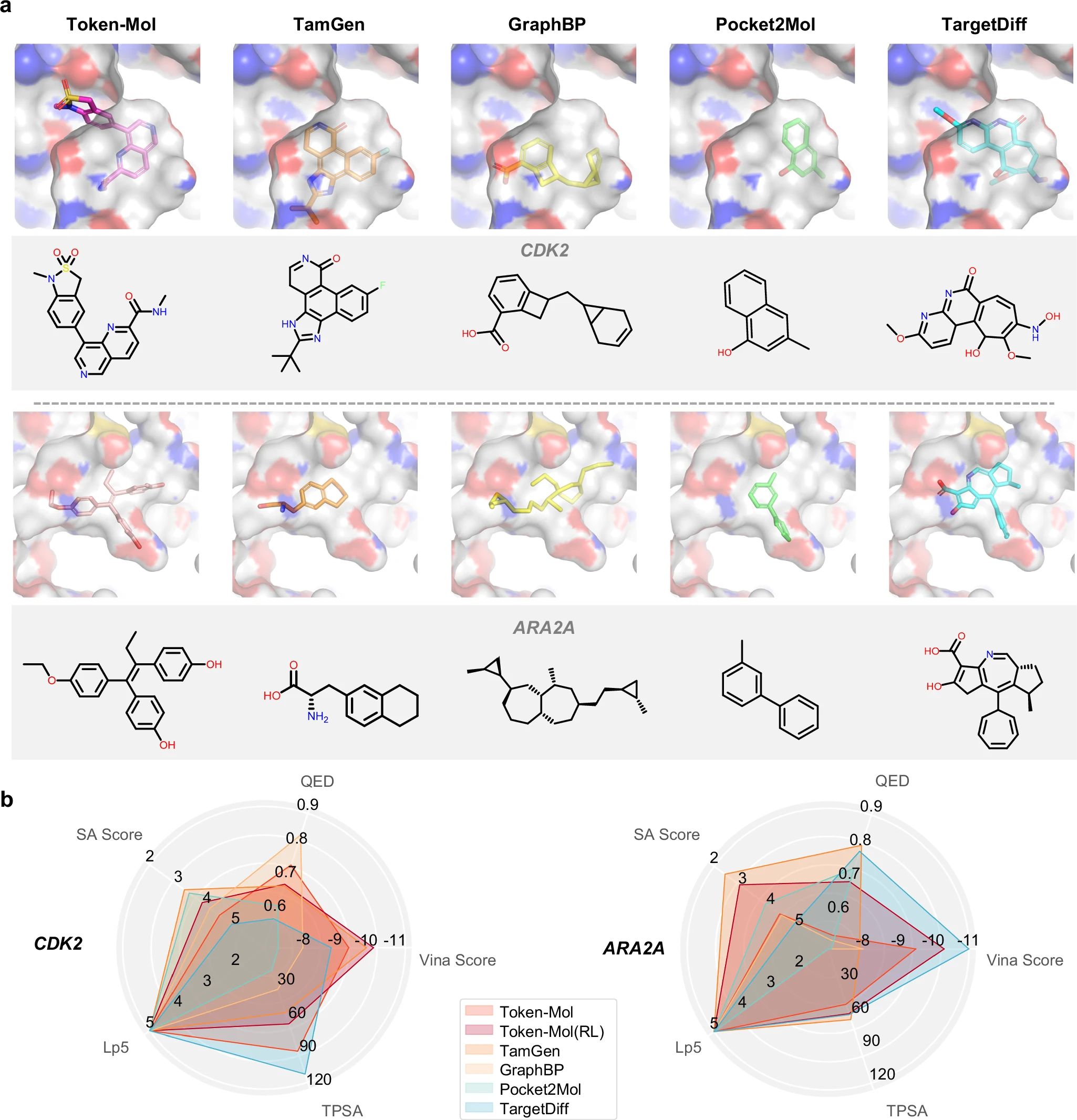 比较由Token-Mol和基线模型为CDK2和ARA2A生成的具有最高亲和力的类药性分子的(a) 结构与结合模式,以及(b)相关的分子性质。
比较由Token-Mol和基线模型为CDK2和ARA2A生成的具有最高亲和力的类药性分子的(a) 结构与结合模式,以及(b)相关的分子性质。
Token-Mol结合pocket encoder与条件注意机制,在基准任务中生成的分子具有更高的药物相似性(QED)与可合成性(SA),分别提升约11%与14%。在真实世界的8个靶点中,Token-Mol成功生成了约20%的候选分子,满足亲和性高、结构合理且可合成的标准,表现出较强的泛化能力。
强化学习增强效果
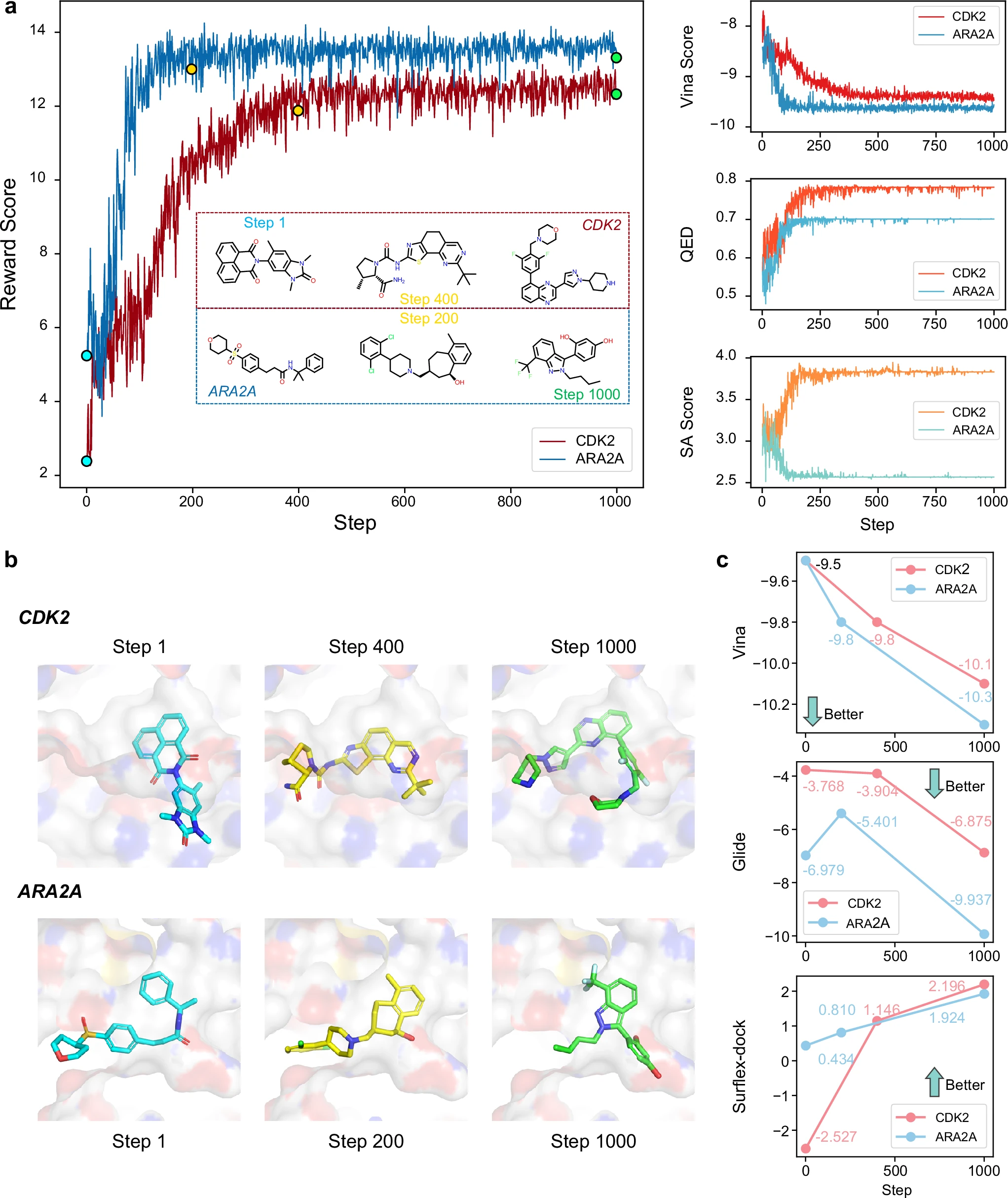
a 强化学习(RL)过程中关键指标的变化,包括奖励得分(reward score)、Vina打分、药物相似性评分(QED)和合成可及性评分(SA score)。图中还展示了不同阶段生成的分子的二维结构。
b 选定分子通过QVina2预测的结合模式。
c 使用不同分子对接方式预测的选定分子与其相应靶点的亲和力变化趋势。
针对CDK2与ARA2A两个靶点,应用RL后生成分子的平均Vina分数提升至约-9.5,同时保持高QED与可合成性。其结构更合理、结合模式更优,部分超越传统基于图的生成模型(如TargetDiff、Pocket2Mol)所能达到的效果。
与Token-Mol对话
Token-Mol的纯词元框架相比传统回归模型具有显著优势,它能够无缝集成前沿的大规模模型技术,包括提示学习、专家混合(MoE)以及检索增强生成(RAG)。在此,研究人员展示了一个提示学习的实例。该应用突出了纯词元模型能够与通用模型无缝集成的独特之处,这是传统的回归模型所不具备优势。 图 4. Token-Mol对话实例
图 4. Token-Mol对话实例
讨论
Token-Mol 1.0 提出了一种全新范式,将语言建模方法扩展至三维药物设计领域。其显著优势包括:
- 统一性:一个模型即可处理生成、预测、构象三类任务;
- 扩展性:Token-only结构适配所有主流LLM(如LLaMA、GPT),易于融入多模态AI体系;
- 高效性:与扩散模型、GNN模型相比,其生成速度更快、计算资源需求更低;
- 创新性:首次提出GCE损失以解决token数值敏感问题,为token-only模型拓展回归任务提供路径。
尽管Token-Mol在多个任务上均达到了或超过了SOTA水平,但仍存在改进空间:其在低频结构的建模仍有待加强,在蛋白口袋的三维结合模式捕捉上亦略逊于几何图模型。未来可从以下方向继续优化:
- 引入多模态对比学习以增强对三维构象的表达能力;
- 联合训练药效团、ADMET预测等任务构建多任务学习框架;
- 融合结构检索(RAG)与对话接口,构建交互式药物生成平台;
- 探索更高效的tokenization机制以缩短输入序列长度,提高模型吞吐量。
总结
Token-Mol 1.0 是首个全token化药物设计大模型,打通了分子构象生成、性质预测与蛋白结合生成的完整链路,在准确性、通用性与效率方面均实现显著突破。它不仅代表了药物AI模型向统一、可扩展平台化发展的重要一步,也为实现真正“智能化药物设计助手”奠定了手艺基础。未来,Token-Mol将有望在药物筛选、先导优化、新分子设计等多个环节加速创新,助力AI+药物研发新范式的落地与成熟。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号