


《构建之法》——第四次作业结对编程
一.结对过程
照片如下:

二.PSP表格
| PSP2.1 | Personal Software Process Stages | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| Estimate | 估计这个任务需要多长时间 | 30 | 20 |
| Development | 开发(需求分析-具体编码) | 400 | 450 |
| Analysis | 需求分析(包括新技术学习) | 200 | 200 |
| Design Spec | 生成设计文档 | 20 | 30 |
| Design Review | 设计复审(和同学审核设计文档) | 30 | 40 |
| Coding Standard | 代码规范(为目前的开发制定规范) | 20 | 15 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 200 | 200 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试、修改代码、代码提交) | 120 | 120 |
| Reporting | 报告 | 80 | 60 |
| Test Report | 测试报告 | 45 | 40 |
| Size Measurement | 计算工作量 | 20 | 25 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 15 |
| total | 总计 | 1335 | 1375 |
三.解题思路(与结对同学共同思考得出思路)
1.当我看到本篇文章的时候,大概看了一下需求,是一个类似wordCount的程序,用来统计TXT文档的一些内容。
2.读取需要处理的文本到,然后用split和正则表达式拆分成数组,然后所有的按照要求进行设置,对数组中的元素,按照博客作业地址给的规范,挨个实现功能
3.考虑到后续可能会增加一些新的功能,要提前留出一些接口来实现功能可以实现
4.确立首先采用命令行编程,然后再过渡为面向对象编程
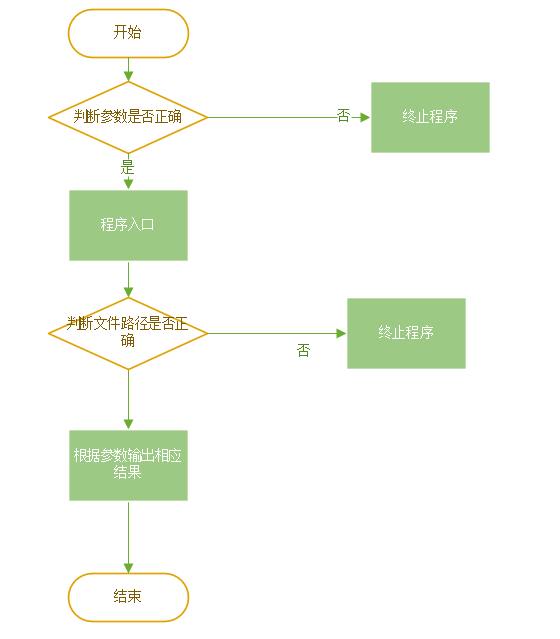
四.代码设计及接口封装设计
根据我们首先得命令行变成实现之后,我们打算重构代码,实现代码解耦还有面向对象编程,本次实验大致有下面几个功能统计字符,统计单词总数,统计行数
还有每个单词出现的次数于是设计了几个类:
Compare类:对单词进行字典序比较,为了排除单词的顺序
Program类:主类,综合调用其他类
Read类:文件的读入,将单词存入数组
Text类:测试类,试用方法
Write类:把输出结果写入文档中
Do类:综合逻辑处理,调用各个类,实现单词排序等功能
- 逻辑流程设计
- 接口封装设计
-
命令行参数设计
在cmd命令行输入的参数会存入程序入口主函数main(string[] args)的字符串数组中。 -
//对-l、-m、-n、-o参数识别并保存他们后面的输入值 for(int i=0;i<args.Length;i++) { if (args[i] == "-l")//路径参数 { path = args[i + 1]; i++; } else if (args[i] == "-m")//参数设定统计的词组长度 { wordlength = int.Parse(args[i+1]); i++; } else if (args[i] == "-n")//参数设定输出的单词数量 { outnum = int.Parse(args[i + 1]); i++; } else if (args[i] == "-o")//参数设定生成文件的存储路径 { outpath = args[i + 1]; i++; } }
-
词组个数设计实现(-m)
//嵌套循环生成词组 words[0] = word[1]; for(int i=0;i<word.Length-wordlenth;i++) { for (int j = i; j <= i+wordlenth-1; j++) { words[i] = words[i] + " "+word[j]; } }
-
按照参数输出高频次数个数(-n)
在Do类中通过调用Compare类实现单词比较,在通过词频优先进行排序,输出前n个词组。//单词比较算法 public int compare(String str1, String str2) { int length1 = str1.Length; int length2 = str2.Length; int limit = Math.Min(length1, length2); char[] a = str1.ToCharArray(); char[] b = str2.ToCharArray(); for (int i = 0; i < limit; i++) { char c1 = (char)(a[i] >= 'a' ? a[i] : (a[i] + 32)); char c2 = (char)(b[i] >= 'a' ? b[i] : (b[i] + 32)); if (c1 != c2) { return c1 - c2; } } return length1 - length2; }
五.代码规范
=》在命名的时候使用有意义的名称
=》禁止使用中文命名
=》变量采用驼峰命名法
=》对于一些复杂的功能和代码,加上详细的注释
=》采用缩进换行等方式,使得代码看起来整洁规范
六.代码复审
1.在代码复审的时候,我们发现队友在命名的时候有几个没有按照要求来命名,于是我更正了他之前的命名
2.在单词数量统计功能实现的时候,我发现了一些小的细节问题,那就是之前判断的时候把空格字符当成了单词输入,导致最终统计的数量不实际数量多,我把这个地方重新设计了一些,更改了一下判断的条件,得出了正确的结果。
3.队友的代码比较简洁,注释也比较少,不利于两个人共同工作和理解,所以我们对部分功能的注释进行了修改,为了能使下一个人在工作时,能理解。
4.还有一些小bug没来得及修复,但是不影响实际的操作(滑稽)
七.单元测试及异常处理
单元测试:
-
对单词字典比较算进行测试(Compare.compare()):
public class CompareTests { [TestMethod()] public void compareTest() { Compare compare = new Compare(); String[] word1 = { "as", "ae", "th", "cpig" }; String[] word2 = { "we", "are", "the", "pig" }; int t; bool k=false; for (int i = 0; i < 4; i++) { t = compare.compare(word1[i], word2[i]); if (t < 0) { k = true; } Assert.AreEqual(true,k ); } } }
-
测试结果:
![]()

-
复制字符混合测试
测试文本内容

测试成功
异常处理:
-
对文件读入进行测试
-
测试代码设计:
public void ReadTextTest() { Read read = new Read(); read.ReadText("D:\a.txt", 1); for(int i=0;i<read.word.Length;i++) { Assert.AreNotEqual("", read.word[i]); } //Assert.Fail(); }
-
运行出错:
-
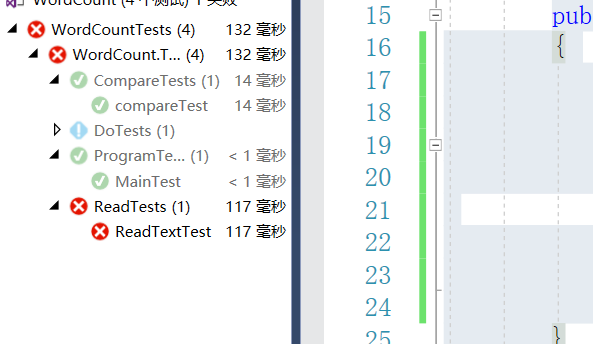
发现是由于word = Regex.Split(sr.ReadToEnd(), @"\W+");代码出现问题,split函数通过正则表达式拆分出来单词数组存在首尾为空的情况。
通过将数组存入hashtable时进行非空判断,解决问题如图所示。

-
写文件文档路径是否存在异常处理:
-
代码设计:
FileStream fileStream1 = new FileStream(l, FileMode.OpenOrCreate, FileAccess.ReadWrite); fileStream1.Close();//如果文件不存在会自动在该路径下创建写入文件
-
-
测试心得:
1、测试需要多参数测试,尽量覆盖用户可能的输入类型,这样才能减下出bug的可能性。
2、在对函数功能测试时,同时也发现了如果某个方法没有完全解耦的话,在测试的时候就会相对比较麻烦,没法单独对那个方法测试,这是一个值得注意的地方
3、在测试完这个系统之后也是受益匪浅,才觉得实际上的开发和书本上讲的一些敏捷的开发原则,和一些设计模式的使用,不是直接就可以简单完成的,这需要不断尝试,才能找到比较合适的 计模式去完成代码的编写
八.性能测试改进
改进花费时间:30mins
-
性能测试:
-
函数性能分析:
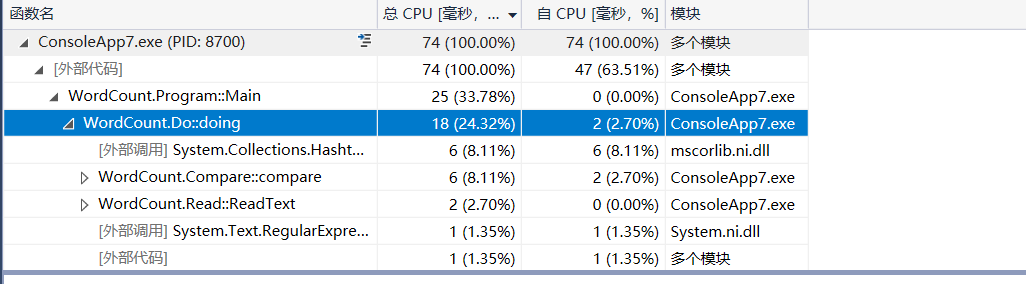
主要是hashtable的创建,字母的比较和读入字符三个部分吃性能

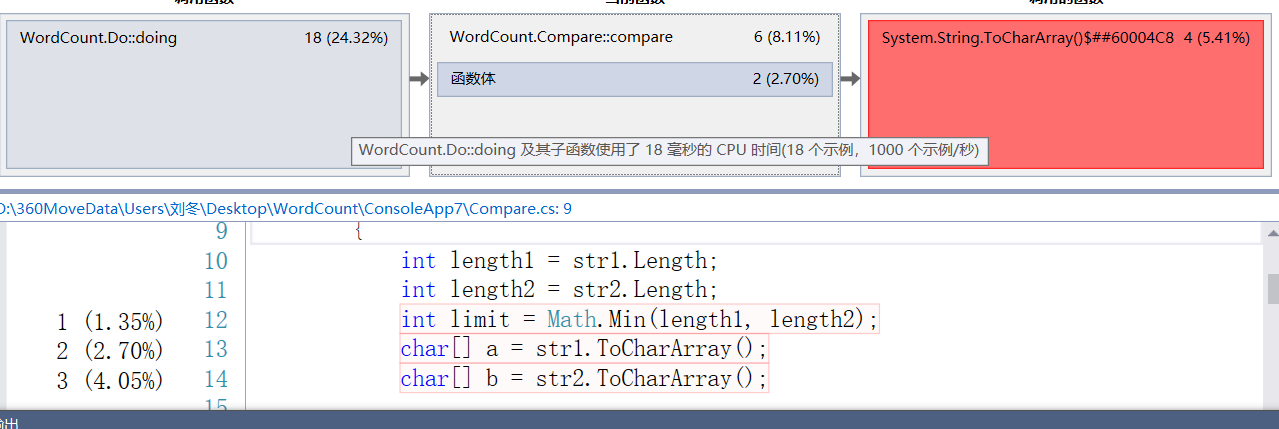
改进方案:
将hashtable的写入算法优化,不在重复判断是否包含value,而是在这之前就对数组进行消重操作。这将很好的提高hashtable部分的性能。
九.部分代码展示及过程运行
-
Main:
public static void Main(string[] args) { int wordlength=1; int outnum=0; string outpath="/"; string path=null; for(int i=0;i<args.Length;i++) { if (args[i] == "-i")//路径参数 { path = args[i + 1]; i++; } else if (args[i] == "-m")//参数设定统计的词组长度 { wordlength = int.Parse(args[i+1]); i++; } else if (args[i] == "-n")//参数设定输出的单词数量 { outnum = int.Parse(args[i + 1]); i++; } else if (args[i] == "-o")//参数设定生成文件的存储路径 { outpath = args[i + 1]; i++; } } new Do().doing(path, wordlength, outnum, outpath); }
-
ReadText:
public String ReadText(String path,int wordlenth) { StreamReader sr = new StreamReader(path, Encoding.Default); while(sr.Read()!=-1) { sum++; } row= sr.ReadToEnd().Split('\n').Length; sr.BaseStream.Seek(0, SeekOrigin.Begin);//重置流指针 row = sr.ReadToEnd().Split('\n').Length;//行数统计 sr.BaseStream.Seek(0, SeekOrigin.Begin); word = Regex.Split(sr.ReadToEnd(), @"\W+");// words = new string[word.Length-wordlenth]; words[0] = word[1]; for(int i=0;i<word.Length-wordlenth;i++) { for (int j = i; j <= i+wordlenth-1; j++) { words[i] = words[i] + " "+word[j]; } } sr.BaseStream.Seek(0, SeekOrigin.Begin);//重置流指针 return sr.ReadToEnd(); }
-
写入文件:
using (StreamWriter sw = new StreamWriter(outpath)) { sw.WriteLine("单词数:" + count);//单词数 sw.WriteLine("字符数:" + zifushu); sw.WriteLine("行数:" + hangshu); sw.WriteLine("词汇量:" + cihui); sw.WriteLine("词组频统计(词频优先字典序):"); for (int i = 0; i < wd.Length; i++) { sw.WriteLine(wd[i] + ": " + hashtable[wd[i]]); } sw.Close(); Console.ReadLine(); }
-
将词组存入hashtable:
for (int i = 0; i < read.words.Length; i++) { if (hashtable.ContainsKey(read.words[i])) { geshu = (int)hashtable[read.words[i]]; geshu++; hashtable[read.words[i]] = geshu; } else { if (read.words[i] != "")//取出split产生的空字符 hashtable.Add(read.words[i], times[i]); } }
-
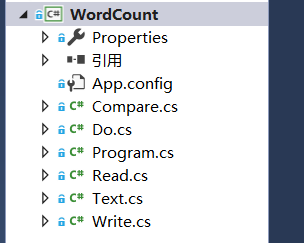
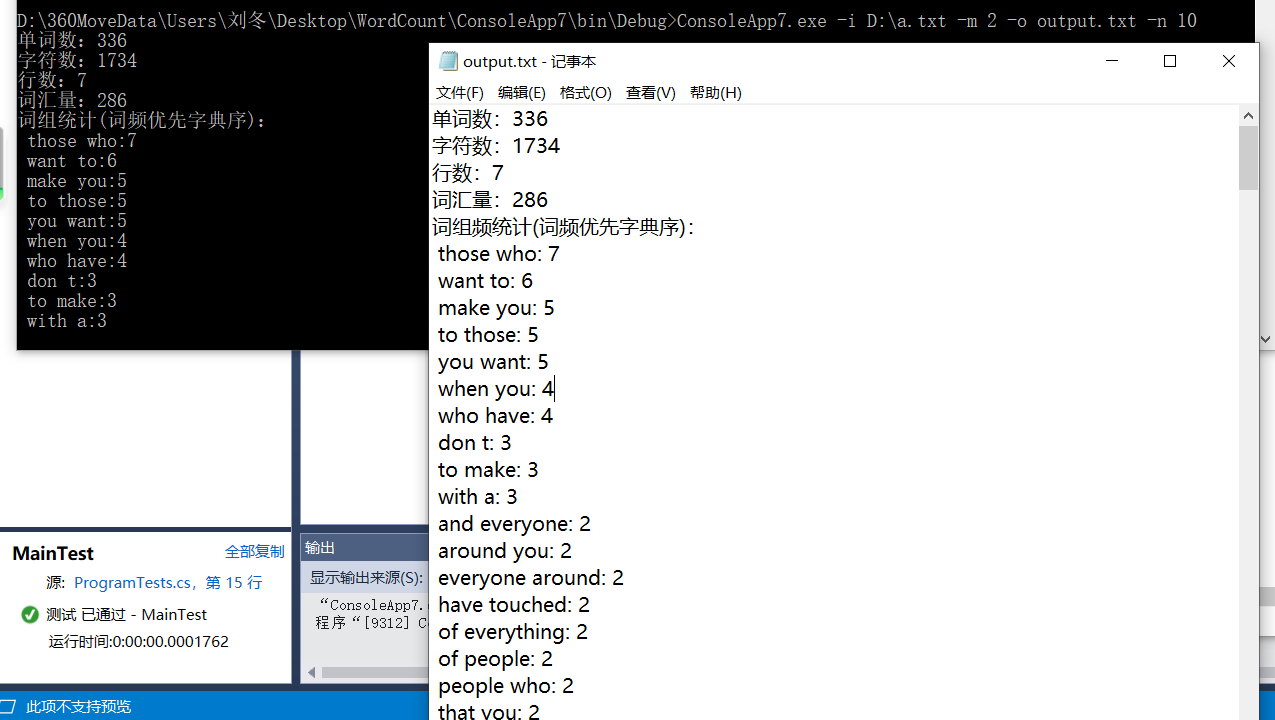
命令行运行结果:
![]()
十.经验总结
结对编程让我实际体会了1+1>2的效果,在一些时间很短的小项目上,结对编程的效率是远远大于单人开发的,当我们在某个具体代码实现的地方出现问题时,两个人解决问题的速度快于一个人,在我的伙伴实际编码的过程中,我会给他提出一些意见,在一个就是可以确定编码思路方向,另一个人只管实现就可以了,而且结对编程的过程中,每个代码就相当于看了两遍,这样出错的可能性大大减小。总的来说结对编程在敏捷这种思想下,是可行的。又学会并熟悉了VS工具还有git的使用流程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号