Python3的基本使用(2)
1、函数
1.1、定义函数
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
def my_abs(x): if x >= 0: return x else: return -x
在某个文件中定义了函数后,可以在另一个文件中用 " from 文件名 import 方法名 " 的方式来导入某个方法。注意,导入时文件名不含文件后缀 .py。
#在FuncTest.py文件中定义方法: def my_abs(x): if x >= 0: return x else: return -x #在test.py文件中引用该方法: from FuncTest import my_abs print(my_abs(100))
调用函数时,如果参数个数不对,Python解释器会自动检查出来,并抛出TypeError。但是如果参数类型不对,Python解释器就无法帮我们检查。
在Python中,函数可以定义返回多个值,并且最终结果也会返回多个值,但实际上只是返回了一个 tuple。
但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,并且会按位置赋给对应的值,所以,也可以视为返回了多个值。
#导入math包 import math def myMove(x, y, step, angle=0): nx = x + step * math.cos(angle) ny = y - step * math.sin(angle) return nx, ny #可以看做是返回了多个值 x, y = myMove(100, 100, 60, math.pi / 6) print(x, y) #151.96152422706632 70.0 #但实际上是返回了一个 tuple r = move(100, 100, 60, math.pi / 6) print(r) #(151.96152422706632, 70.0)
1.1.1、参数传递
在 python 中,字符串strings、元组 tuples 和 数字类型 numbers 是不可更改的对象,而 列表list、字典dict 等则是可以修改的对象。
-
不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变 a 的值,相当于新生成了 a。
-
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:不可更改对象作为参数是值传递(整数、字符串、元组)。可更改对象作为参数是引用传递(列表,字典)。
如 a=10,la=[1,2,3],fun(a),传递的只是 a 的值,不会影响外部的a的值,如果在 fun(a))内部修改 a 的值,则是新生成来一个 a。而 fun(la),则是将 la 真正的传过去,修改后 fun 外部的 la 也会受影响。
1.2、空函数
如果想定义一个什么事也不做的空函数,可以用pass语句:
def nop(): pass
pass语句什么都不做,那有什么用?实际上pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。
pass还可以用在其他语句里,比如下面,缺少了pass,代码运行就会有语法错误。
if age >= 18: pass
1.3、函数的默认参数
我们可以给函数定义默认参数,这样使用者可以不传那个默认参数。注意,必须得保证必选参数在前,默认参数在后,否则Python的解释器会报错。
def power(x, n=2): s = 1 while n > 0: n = n - 1 s = s * x return s
可以定义多个默认参数。调用有多个默认参数的函数时,可以按顺序提供默认参数,比如调用enroll('Bob', 'M', 7)。也可以不按顺序提供部分默认参数,此时需要把参数名写上。比如调用enroll('Adam', 'M', city='Tianjin'),
def enroll(name, gender, age=6, city='Beijing'): print('name:', name) print('gender:', gender) print('age:', age) print('city:', city)
定义默认参数要牢记一点:默认参数必须指向不变对象!
否则将可能会出现类似以下默认参数随着使用过程当中会发生变化的问题:
#先定义一个函数,传入一个list,添加一个END再返回: def add_end(L=[]): L.append('END') return L #当你正常调用时,结果没问题: add_end([1, 2, 3]) #[1, 2, 3, 'END'] add_end(['x', 'y', 'z']) #['x', 'y', 'z', 'END'] #当你使用默认参数调用时,一开始结果也是对的: >>> add_end() ['END'] #但是,再次调用add_end()时,结果就不对了: >>> add_end() ['END', 'END'] >>> add_end() ['END', 'END', 'END']
因为 Python 函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
要避免这个问题,我们可以用None这个不变对象来实现:
#这样定义,无论怎么调用、调用多少次,都不会有问题 def add_end(L=None): if L is None: L = [] L.append('END') return L
1.4、不定长参数(*参数名)
不定长参数的形式是*args,名称前面有一个星号*,用以接收不确定数量的参数。我们常用的内置函数print就是一个可变参数函数。调用该函数时,可以传入任意个参数,包括0个参数:
def foo(*args): print(type(args)) for item in args: print(item)
在函数内部,参数 args 接收到的实际上就是一个元组 tuple。
foo('a', 'b', 'c') #将输出 <class 'tuple'> a b c
如果需要将 list 或者 tuple 作为参数去调用具有可变参数的函数时,我们可以直接将其作为参数进行传递。Python同时允许你在 list 或 tuple 前面加一个*号,把 list 或 tuple 里面的元素变成一个个参数传进去:
nums = [1, 2, 3] foo(nums) #将输出 <class 'tuple'> 1 2 3
1.5、关键字参数(name=val、**参数名)
调用函数时,我们可以使用“关键字参数”,它的形式是:kwarg=value。代码示例:
def say_hi(name, greeting='Hi', more=''): print(greeting, name, more) say_hi(name='Tom') #Hi Tom say_hi(name='Tom', greeting='Hello') #Hello Tom say_hi(name='Tom', more='how are you') #Hi Tom how are you say_hi(more='good day', name='Tom', greeting='Hi') #Hi Tom good day
关键字参数是通过关键字来确认参数的,所以可以不用按照函数定义时的顺序传递参数。但是关键字参数后面必须都是关键字参数,否则将会报错。比如下面的调用都是无效的:
def say_hi(name, greeting='Hi', more=''): print(greeting, name, more) say_hi() # 缺少必须的参数name say_hi(name='Tom', 'Hello') # 关键字参数后面出现了非关键字参数 say_hi('Tom', name='Tim') # 同样的参数传了两个值 say_hi(age=10) # 函数定义中不存在的关键字参数
如果函数定义的最后一个参数是两个星号加名称,比如**name,那么往这个函数传入的所有关键字参数将会在函数内部自动组装成一个字典dictionary,并且该字典指向为参数名 name。这个字典不包括name前面声明的普通参数。
如下,定义了关键字参数 kw:
def person(name, age, **kw): print('name:', name, 'age:', age, 'other:', kw)
函数person除了必选参数name和age外,还接受关键字参数kw。在调用该函数时,可以只传入必选参数,也可以传入任意个数的关键字参数:
#不传关键字参数 person('Michael', 30) #name: Michael age: 30 other: {} #可以传入任意个数的关键字参数: person('Bob', 35, city='Beijing') #name: Bob age: 35 other: {'city': 'Beijing'} person('Adam', 45, gender='M', job='Engineer') #name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
把 dict 作为参数传递:
extra = {'city': 'Beijing', 'job': 'Engineer'}
person('Jack', 24, **extra) #name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
**extra表示把extra这个dict的所有key-value用关键字参数传入到函数的**kw参数,kw将获得一个dict。注意kw获得的dict是extra的一份深拷贝,对kw的改动不会影响到函数外的extra。
1.6、命名关键字参数(*, 参数名1, 参数名2)
如果要限制关键字参数的名字,我们就可以用命名关键字参数。和关键字参数比如:**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
例如,只接收city和job作为关键字参数的函数定义如下:
def person(name, age, *, city, job): print(name, age, city, job) person('wen', 11, city='aa', job='bb') #输出 wen 11 aa bb
在调用定义了命名关键字参数的函数时,如果要使用命名关键字参数则必须传入参数名,如果没有传入参数名,调用将可能报错。因为 Python 会将其认为是普通的参数,而这些普通的参数中的数量可能跟你传递的不一致就会导致报错。
>>> person('Jack', 24, 'Beijing', 'Engineer') Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: person() takes 2 positional arguments but 4 were given
如果在函数定义的参数中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了。但如果没有可变参数,就必须加一个*作为特殊分隔符。如果缺少*,Python解释器将无法识别位置参数和命名关键字参数。
def person(name, age, *args, city, job): print(name, age, args, city, job)
命名关键字参数可以有缺省值,从而简化调用:
def person(name, age, *, city='Beijing', job): print(name, age, city, job) #由于命名关键字参数city具有默认值,调用时,可不传入city参数: >>> person('Jack', 24, job='Engineer') Jack 24 Beijing Engineer
1.7、Python中函数的各种参数的顺序
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
比如定义一个函数,包含上述若干种参数:
def f1(a, b, c=0, *args, **kw): print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw) def f2(a, b, c=0, *, d, **kw): print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
在函数调用的时候,Python解释器自动按照参数位置和参数名把对应的参数传进去。
>>> f1(1, 2) a = 1 b = 2 c = 0 args = () kw = {} >>> f1(1, 2, c=3) a = 1 b = 2 c = 3 args = () kw = {} >>> f1(1, 2, 3, 'a', 'b') a = 1 b = 2 c = 3 args = ('a', 'b') kw = {} >>> f1(1, 2, 3, 'a', 'b', x=99) a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99} >>> f2(1, 2, d=99, ext=None) a = 1 b = 2 c = 0 d = 99 kw = {'ext': None}
通过一个tuple和dict,你也可以调用上述函数:
>>> args = (1, 2, 3, 4) >>> kw = {'d': 99, 'x': '#'} >>> f1(*args, **kw) a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'} >>> args = (1, 2, 3) >>> kw = {'d': 88, 'x': '#'} >>> f2(*args, **kw) a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}
对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
2、迭代器(Iterator)
迭代是Python最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。字符串,列表或元组对象都可用于创建迭代器:
list=[1,2,3,4] it = iter(list) # 创建迭代器对象 print (next(it)) # 输出迭代器的下一个元素 1 print (next(it)) #2
迭代器对象可以使用常规for语句进行遍历:
#!/usr/bin/python3 list=[1,2,3,4] it = iter(list) # 创建迭代器对象 for x in it: print (x, end=" ") #将输出 1 2 3 4
也可以使用 next() 函数进行遍历:
#!/usr/bin/python3 import sys # 引入 sys 模块 list=[1,2,3,4] it = iter(list) # 创建迭代器对象 while True: try: print (next(it)) #将输出 1 2 3 4 except StopIteration: sys.exit()
可以直接作用于for循环的数据类型有以下几种:一类是集合数据类型,如list、tuple、dict、set、str等;一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。可以使用isinstance()判断一个对象是否是Iterable对象:
from collections.abc import Iterable print(isinstance([], Iterable)) #true print(isinstance({}, Iterable)) #true print(isinstance('abc', Iterable)) #true print(isinstance((x for x in range(10)), Iterable)) #true print(isinstance(100, Iterable)) #false
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。可以使用isinstance()判断一个对象是否是Iterator对象:
from collections.abc import Iterator isinstance((x for x in range(10)), Iterator) #True isinstance([], Iterator) #False isinstance({}, Iterator) #False isinstance('abc', Iterator) #False
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator) True >>> isinstance(iter('abc'), Iterator) True
Python的for循环实际上就是通过不断调用next()函数实现的,它会先将循环的对象转换为Iterator对象,例如:
for x in [1, 2, 3, 4, 5]: pass #实际上完全等价于以下: # 首先获得Iterator对象: it = iter([1, 2, 3, 4, 5]) # 循环: while True: try: # 获得下一个值: x = next(it) except StopIteration: # 遇到StopIteration就退出循环 break
3、生成器(generator)
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
以下实例使用 yield 实现斐波那契数列:
#!/usr/bin/python3 import sys def fibonacci(n): # 生成器函数 a, b, counter = 0, 1, 0 while True: if (counter > n): return yield a a, b = b, a + b counter += 1
f = fibonacci(10) # f 是一个迭代器,由生成器返回生成 while True: try: print (next(f), end=" ") #这里将依次输出 0 1 1 2 3 5 8 13 21 34 55 except StopIteration:
sys.exit()
要创建一个generator,可以把一个列表生成式的[]改成(),这样就创建了一个generator:
>>> L = [x * x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range(10))
>>> g
<generator object <genexpr> at 0x1022ef630>
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
>>> next(g)
0
>>> next(g)
1
>>> next(g)
4
>>> next(g)
9
>>> next(g)
16
>>> next(g)
25
>>> next(g)
36
>>> next(g)
49
>>> next(g)
64
>>> next(g)
81
>>> next(g)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
但一般会使用for循环,因为generator也是可迭代对象,使用for循环将不会出现StopIteration的错误。
>>> g = (x * x for x in range(10))
>>> for n in g:
... print(n)
...
0
1
4
9
16
25
36
49
64
81
要把一个函数变成generator,只需要在需要返回的值前面加 yield 符号就可以了:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
这就是定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
>>> f = fib(6)
>>> f
<generator object fib at 0x104feaaa0>
generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
比如:
def odd():
print('step 1')
yield 1
print('step 2')
yield(3)
print('step 3')
yield(5)
调用该generator时,首先要生成一个generator对象,然后用next()函数不断获得下一个返回值:
>>> o = odd()
>>> next(o)
step 1
1
>>> next(o)
step 2
3
>>> next(o)
step 3
5
>>> next(o)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
>>> for n in fib(6):
... print(n)
...
1
1
2
3
5
8
用for循环调用generator时我们会发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
>>> g = fib(6)
>>> while True:
... try:
... x = next(g)
... print('g:', x)
... except StopIteration as e:
... print('Generator return value:', e.value)
... break
...
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done
4、模块和包
4.1、模块的基本介绍
在Python中,一个.py文件就称之为一个模块(Module)。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
使用模块还可以避免函数名和变量名冲突。模块的变量和函数不会对其他模块产生冲突,因此,我们自己在编写模块时,不必考虑函数名字会与其他模块冲突。但是注意尽量不要与内置函数名字冲突。
在这里可以查看Python的所有内置函数:链接。
4.2、模块的命名
4.3、包
为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package),一个拥有__init__.py文件的文件夹即可称之为一个包。
不同包下的模块可以同名,同一个包下模块同名才会冲突。每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是该文件夹名,比如下面的mycompany包:
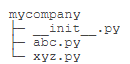
上面组织目录当中,abc.py模块的名字就变成了mycompany.abc,类似的,xyz.py的模块名变成了mycompany.xyz。

上面目录当中,文件www.py的模块名就是mycompany.web.www,两个文件utils.py的模块名分别是mycompany.utils和mycompany.web.utils。
4.4、如何引入一个模块(import)
Python本身就内置了很多非常有用的模块,只要安装完毕,这些模块就可以立刻使用。另外,还可以通过 pip 来安装第三方模块。
例如,使用 sys 模块:
# !/usr/bin/python3 # 假设当前文件名: test01.py import sys print('命令行参数如下:') for i in sys.argv: print(i) print('Python 路径为:', sys.path)
sys.argv 是一个包含命令行参数的列表,sys.path 包含了一个 Python 解释器自动查找所需模块的路径的列表。上面代码将依次输出:
命令行参数如下:
F:/pycharmWorkSpace/pythonTest01/test01.py
Python 路径为: ['F:\\pycharmWorkSpace\\pythonTest01', 'F:\\pycharmWorkSpace\\pythonTest01', 'F:\\pycharmWorkSpace\\pythonTest01\\venv\\Scripts\\python37.zip', 'E:\\develop\\Python37\\DLLs', 'E:\\develop\\Python37\\lib', 'E:\\develop\\Python37', 'F:\\pycharmWorkSpace\\pythonTest01\\venv', 'F:\\pycharmWorkSpace\\pythonTest01\\venv\\lib\\site-packages']
4.4.1、python中对模块的搜索路径
当我们使用import语句的时候,Python解释器是根据Python的搜索路径来依次搜索模块的。搜索路径是由一系列目录名组成的,Python解释器就依次从这些目录中去寻找所引入的模块。
搜索路径就被存储在sys模块中的path变量:
import sys print('python的搜索路径为:', sys.path) #上面将输出 Python 的搜索路径为: ['F:\\pycharmWorkSpace\\pythonTest01', 'F:\\pycharmWorkSpace\\pythonTest01', 'F:\\pycharmWorkSpace\\pythonTest01\\venv\\Scripts\\python37.zip', 'E:\\develop\\Python37\\DLLs', 'E:\\develop\\Python37\\lib', 'E:\\develop\\Python37', 'F:\\pycharmWorkSpace\\pythonTest01\\venv', 'F:\\pycharmWorkSpace\\pythonTest01\\venv\\lib\\site-packages']
其中第一项为当前运行脚本的路径。
4.5、import 和 from...import... 语法
在 python 用 import 或者 from...import 来导入相应的模块。对于同一个模块,不管你执行了多少次import,一个模块只会被导入一次,这样可以防止导入模块被一遍又一遍地执行。模块中的代码在被导入时会执行,并且只有在第一次被导入时才会被执行。
导入模块的语法:
将整个模块(somemodule)导入,格式为: import somemodule 此时我们要想使用该模块下的变量,应该这样使用: somemodule.name
从某个模块中导入某个函数,格式为: from somemodule import somefunction
从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
将某个模块中的全部函数导入,格式为: from somemodule import *
# 导入 sys 模块 import sys for i in sys.argv: print (i) print ('\n python 路径为',sys.path)
# 导入 sys 模块的 argv,path 成员 from sys import argv,path # 导入特定的成员print('path:',path) # 因为已经导入path成员,所以此处引用时不需要加sys.path
导入指定包下的模块:
导入某个包下的某个模块:import somepackage.somemodule 此时我们要想使用该模块下的变量,应该这样使用: somepackage.somemodule.name (这种形式的语法只允许导入包或者模块,不允许直接导入包的变量或者函数等)
导入某个包下的某个模块的另一种写法:比如导入包 a 下的包 b 下的模块 c : from a.b import c 此时我们要想使用 c 模块下的变量,可以直接写 c 模块,而不需要带上包名: c.name
导入某个包下的某个模块的某个函数:比如导入包 a 下的模块 b 下的 show 函数: from a.b import show 此时可以直接使用函数名 show()
导入包时用 * 语法:
比如导入 a 包:from a import * 。此时 * 所指的模块是由包的 __init__.py 文件中的 __all__ 变量定义的。__init__.py 文件的另外一个作用就是定义 包 中的__all__,用来模糊导入,如__init__.py:
__all__ = ["bmodule","cmodule"]
在包外面导入:
from a import * show = bmodule.show show()
如果 __all__ 没有定义,那么使用from a import *这种语法的时候,就不会导入包 a 里的任何子模块。但此时会运行 __init__.py 文件,并且把该文件中定义的变量和函数给引进来。(如果有定义了__all__,那么此时就只会导入__all__指向的模块,不会导入该文件中定义的变量)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号