

Ai复习
1、目前比较好的向量模型是openAI的收费的,开源好用的Qwen3 embedding模型。


MTEB是一个公共的embedding测试集合
向量库:chroma,Milvus,Faiss, Weaviate

2、向量基于双塔模型训练

3、向量怎么计算

4、rag系统基本模型

5、改进切 文本的方式 nltk库

医疗的文档经验

6、文本切割的方式

7、有时候最合适的答案不一定排在前面,需要使用打分模型

打分模型:

8、混合检索
同时使用传统的es和向量检索,融合两次的召回结果做RRF排序。

9、工具

10、知识图谱(一般用不上)

11、配置Ak/SK

12、langchain和llamaindex的区别。

13、反向传播算法(Backpropagation algorithm,简称BP算法)
是一种用于训练多层神经网络的监督学习算法,通过梯度下降法和链式法则计算并调整网络参数(权重和偏置),以最小化预测输出与真实值之间的误差,从而优化网络性能。
(模型实际输出-预期值)的平方为loss。损失函数。目前loss一般1.5就会有效果经验。提升acc(准确率),lr(学习率)

14、模型本身就是矩阵
训练模型本身是进行特征提取,通过数据线性代数里的概率分布来表达的。
15、模型训练数据集合大小比例。
训练集合:验证集:测试集=8:1:1 假如分类模型,如果是分类任务,要保证训练集每个分类均衡
比如以下分类,类别不均衡,一般做不到补齐数据,只能按照合理范围舍弃数据。可以在将标签都控制在1.7左右。
比较牛逼是yolo方式去处理样本方式不均匀。

16、训练注意点
l训练oss损失逐渐上升,不保存过拟合的参数
17、大语 言大小

18 、使用配置更新模型的toke_maxlength长度,处理超长文本训练。
方式一:直接加载预训练模型。
方法二:config对象初始化模型。

改了模型矩阵需要,先验就失效了,需要把原模型数据一块加进来。

19、部署gpt2训练中文
vacab词典21128个词,生成文章原理每次是从这21128个词里面选,根据概率来,同一个模型,dosample为false,每次都是选取概率最大的,为true则会随机选前几个。

20、训练bert和训练gpt2区别
bert二分类模型只需要理解,所以是增量微调,gpt2只能全量微调。
21、训练模型时候
pytorch和cuda和python版本都要对应上,有的最高只能支持3.10

22、学习率优化器 AdamW,自动优化学习率,
学习率过大,好处:loss下降的快,坏处:不易收敛
学习率过小:好处:容易收敛,坏处:loss下降的慢

产生震荡。

23、eval()使用pytorch需要调用,transformer内部已经调用了eval(),所以使用transformer用模型生成文本,不要使用eval()
24、一般AI只负责创作,格式由程序控制。
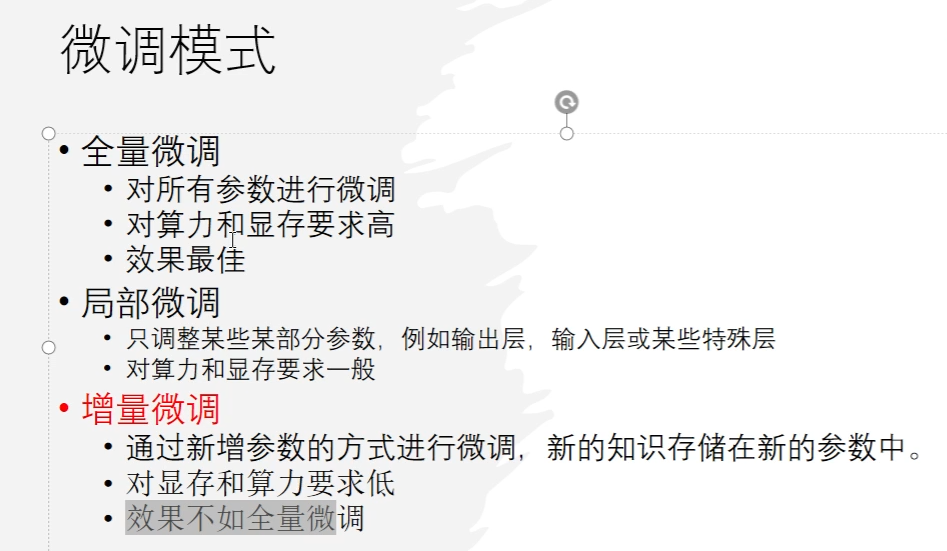
25、微调的方式,微调有时候不是最终解,针对10B以上的模型,不适合微调,可能微调后的模型不如之前的模型。现阶段都是使用局部微调。
微调都是针对百亿参数以下。
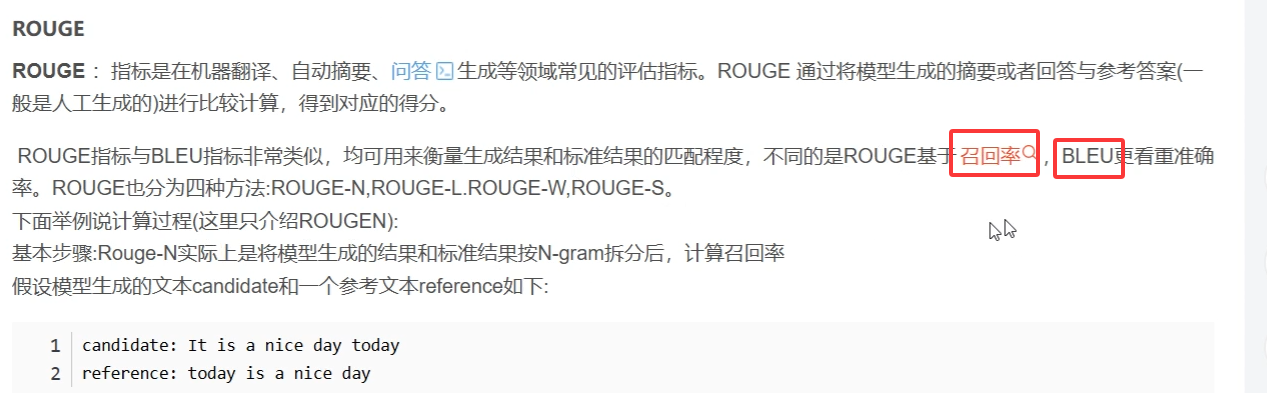
26 lammaryfactory评分标准,BLEU 就是生成词跟预测词的重叠度 ROUGE基于召回率



重叠度为4

27、opencompass评估大模型,原理也是根据bleu(对话)和rouge(段落)

一般不要选基座模型,因为数据集是没有人工梳理的,会涉及敏感信息。选择模型一般选带chat的版本,或者instruct(人类偏好对齐)
安装好compass后,直接通过命令评估,也可以在线评估模型。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号