

使用xtener微调模型Qwen1.5-1.8B-Chat
1.构建虚拟环境
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env
拉取xtener
git clone https://github.com/InternLM/xtuner.git
然后安装依赖的软件,这步需要的时间比较长。
cd xtuner
pip install -e '.[all]'
2.下载模型
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen1.5-1.8B-Chat',cache_dir='/root/Qwen/Qwen1.5-1.8B-Chat')
3.微调
创建微调训练相关的配置文件在左侧的文件列表,xtuner 的文件夹里,打开
/root/xtuner/xtuner/configs/qwen/qwen1_5/qwen1_5_1_8b_chat/qwen1_5_1_8b_chat_qlora_alpaca_e3.py
复制一份至根目录。
打开这个文件,然后修改预训练模型地址,数据文件地址等。
### PART 1中 #预训练模型存放的位置 pretrained_model_name_or_path = '/root/llm/internlm2-1.8b-chat #微调数据存放的位置 data_files = '/root/public/data/target_data.json'#基座模型路径 4.微调训练 在当前目录下,输入以下命令启动微调脚本 5.模型转换 模型训练后会自动保存成 PTH 模型(例如 iter_2000.pth ,如果使用了 DeepSpeed,则将会是一个 文件夹),我们需要利用 xtuner convert pth_to_hf 将其转换为 HuggingFace 模型,以便于后续使 用。具体命令为: 6.模型合并 如果使用了 LoRA / QLoRA 微调,则模型转换后将得到 adapter 参数,而并不包含原 LLM 参数。如果您 期望获得合并后的模型权重(例如用于后续评测),那么可以利用 xtuner convert merge : 附:xtuner中文文档https://xtuner.readthedocs.io/zh-cn/latest/index.html # 训练中最大的文本长度 max_length = 512 # 每一批训练样本的大小 batch_size = 2 #最大训练轮数 max_epochs = 3 #验证数据 evaluation_inputs = [ '只剩一个心脏了还能活吗?', '爸爸再婚,我是不是就有了个新娘?', '樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买','马上要上游泳课了,昨天洗的泳裤还没 干,怎么办', '我只出生了一次,为什么每年都要庆生' ] # PART 3中 dataset=dict(type=load_dataset, path="json",data_files=data_files) dataset_map_fn=None
4.微调训练
在当前目录下,输入以下命令启动微调脚本
xtuner train internlm2_chat_1_8b_qlora_alpaca_e3.py
错误提示
RuntimeError: Failed to import transformers.integrations.bitsandbytes because of the following error (look up to see its traceback): No module named 'triton.ops'
我是4090显卡,重新安装torch和cuda版本
pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu121
成功运行
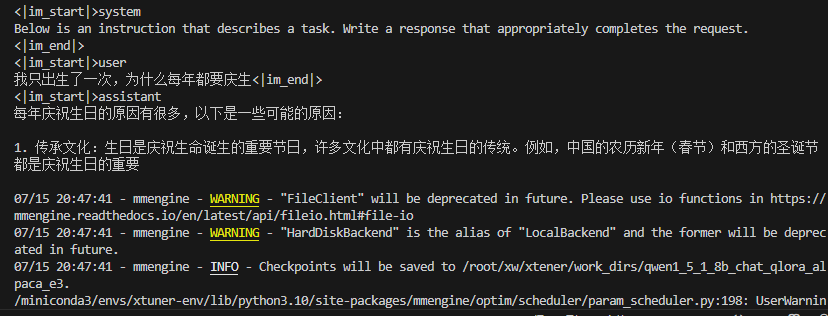
5.模型转换
模型训练后会自动保存成 PTH 模型(例如 iter_2000.pth ,如果使用了 DeepSpeed,则将会是一个
文件夹),我们需要利用 xtuner convert pth_to_hf 将其转换为 HuggingFace 模型,以便于后续使
用。具体命令为:
xtuner convert pth_to_hf ${FINETUNE_CFG} ${PTH_PATH} ${SAVE_PATH}
# 例如:xtuner convert pth_to_hf qwen1_5_1_8b_chat_qlora_alpaca_e3.py /root/xw/xtener/work_dirs/qwen1_5_1_8b_chat_qlora_alpaca_e3/iter_1500.pth /root/xw/xtener/work_dirs/qwen1_5_1_8b_chat_qlora_alpaca_e3/hf

hf文件夹
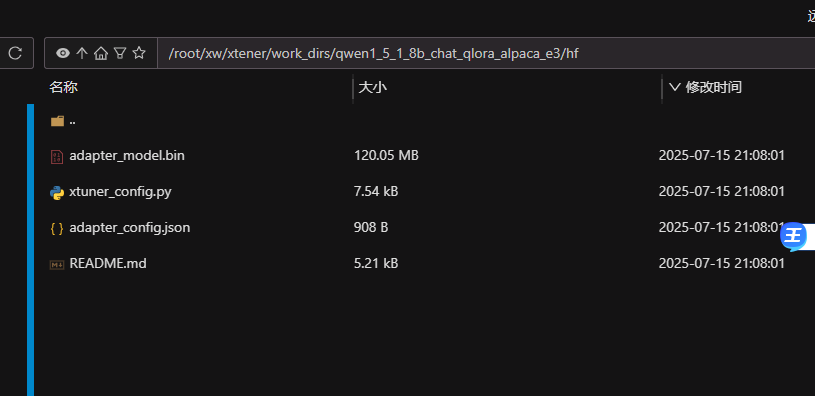
6.模型合并
如果使用了 LoRA / QLoRA 微调,则模型转换后将得到 adapter 参数,而并不包含原 LLM 参数。如果您
期望获得合并后的模型权重(例如用于后续评测),那么可以利用
xtuner convert merge ${LLM} ${LLM_ADAPTER} ${SAVE_PATH}
xtuner convert merge /root/xw/Qwen1.5-1.8B-Chat /root/xw/xtener/work_dirs/qwen1_5_1_8b_chat_qlora_alpaca_e3/hf /root/xw/xtener/work_dirs/qwen1_5_1_8b_chat_qlora_ alpaca_e3/cover


7、使用xtuner chat对话模型
xtuner chat /root/xw/xtener/work_dirs/qwen1_5_1_8b_chat_qlora_alpaca_e3/cover
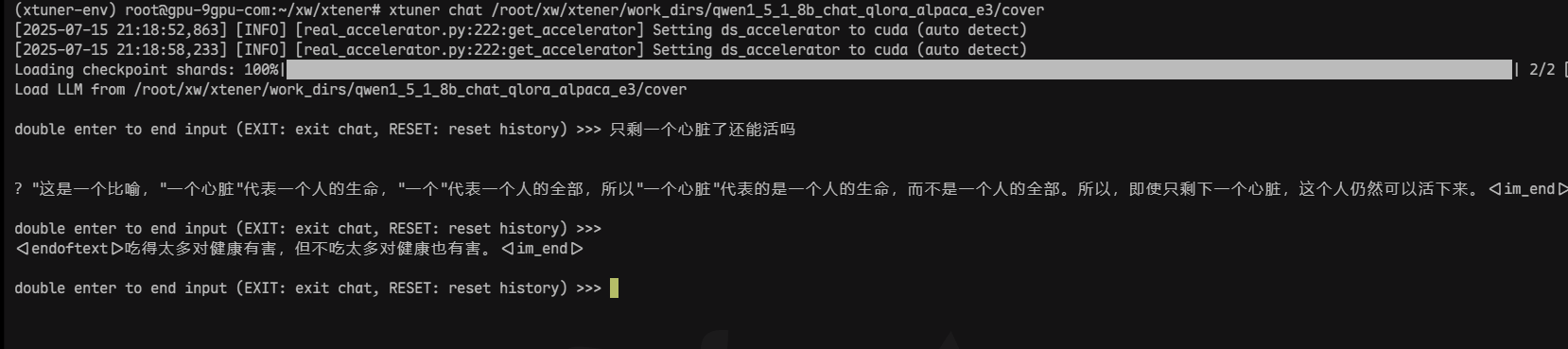
8,主观的查看训练的记录
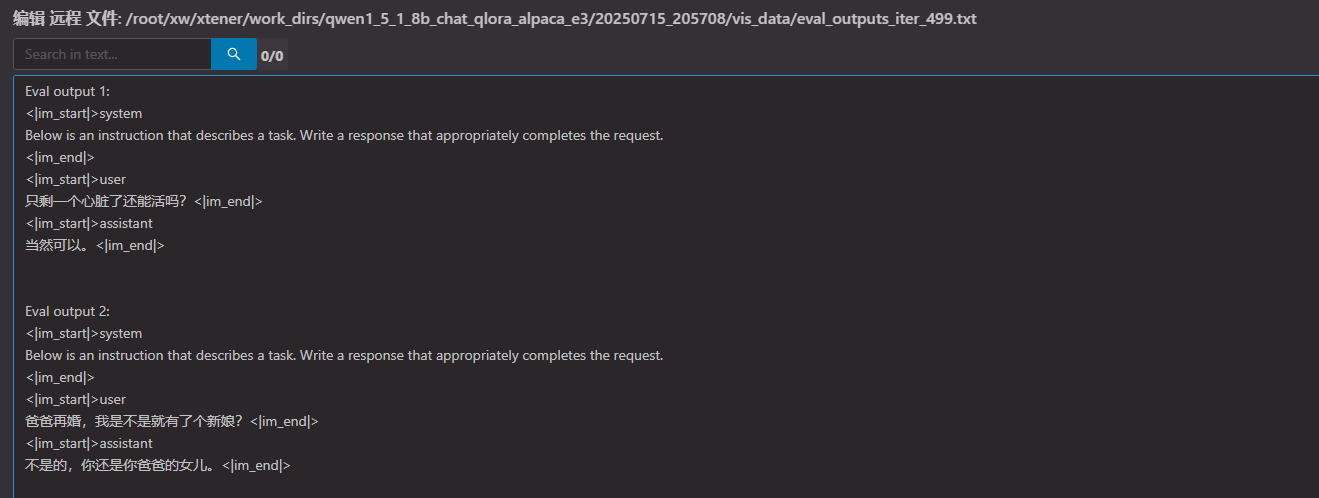

 浙公网安备 33010602011771号
浙公网安备 33010602011771号