Python爬虫-爬取豆瓣图书Top250
豆瓣网站很人性化,对于新手爬虫比较友好,没有如果调低爬取频率,不用担心会被封 IP。但也不要太频繁爬取。
涉及知识点:requests、html、xpath、csv
一、准备工作
需要安装requests、lxml、csv库
爬取目标:https://book.douban.com/top250
二、分析页面源码
打开网址,按下F12,然后查找书名,右键弹出菜单栏 Copy==> Copy Xpath
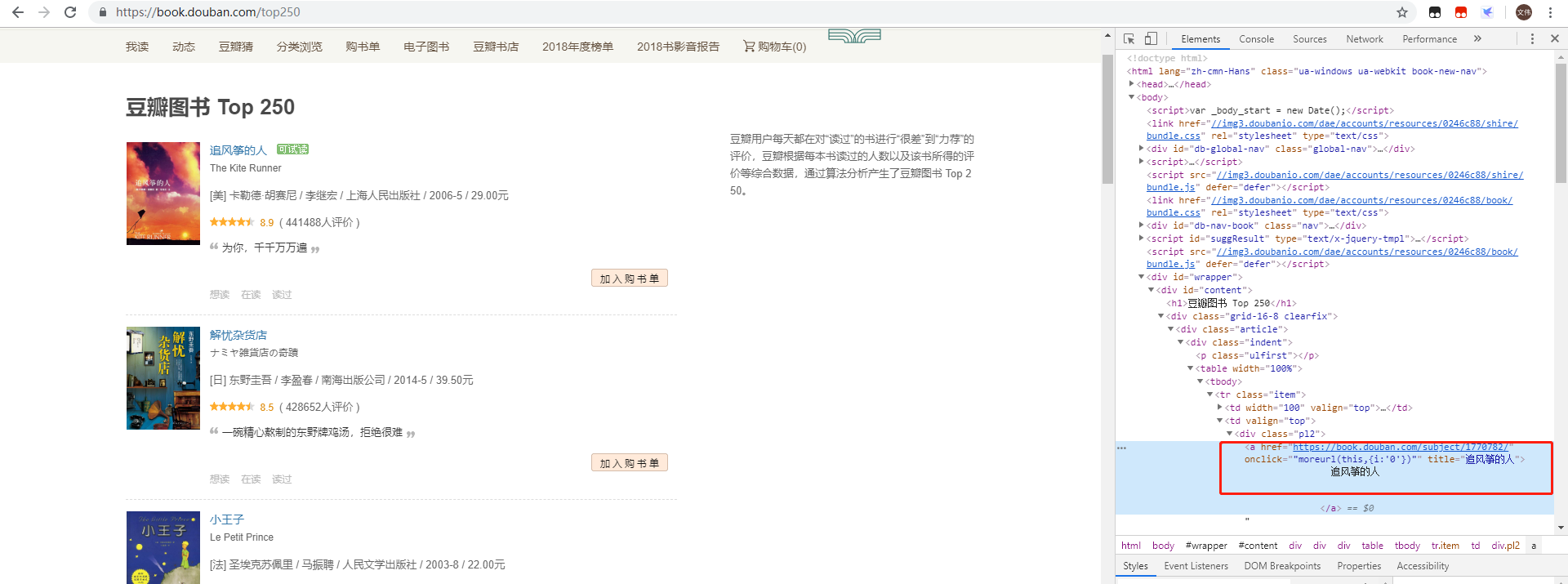
以书名“追风筝的人” 获取书名的xpath是://*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a
这里需要注意一下,浏览器复制的xpath只能作参考,因为浏览器经常会在自己里面增加多余的tbody标签,我们需要手动把这个标签删除,整理成//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a
同样获取图书的评分、评论人数、简介,结果如下:
//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2]
//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[3]
//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/p[1]
初步代码
import requests from lxml import etree html = requests.get('https://book.douban.com/top250').text res = etree.HTML(html) #因为要获取标题文本,所以xpath表达式要追加/text(),res.xpath返回的是一个列表,且列表中只有一个元素所以追加一个[0] name = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text()')[0].strip() score = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2]/text()')[0].strip() comment = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[3]/text()')[0].strip() info = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/p[1]/text()')[0].strip() print(name,score,comment,info)
执行显示:

这里只是获取第一条图书的信息,获取第二、第三看看

得到xpath:
import requests from lxml import etree html = requests.get('https://book.douban.com/top250').text res = etree.HTML(html) name1 = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text()')[0].strip() name2 = res.xpath('//*[@id="content"]/div/div[1]/div/table[2]/tr/td[2]/div[1]/a/text()')[0].strip() name3 = res.xpath('//*[@id="content"]/div/div[1]/div/table[3]/tr/td[2]/div[1]/a/text()')[0].strip() print(name1,name2,name3)
执行显示:

对比他们的xpath,发现只有table序号不一样,我们可以就去掉序号,得到全部关于书名的xpath信息:
import requests from lxml import etree html = requests.get('https://book.douban.com/top250').text res = etree.HTML(html) names = res.xpath('//*[@id="content"]/div/div[1]/div/table/tr/td[2]/div[1]/a/text()') for name in names: print(name.strip())
执行结果:太多,这里只展示一部分

对于其他评分、评论人数、简介也同样使用此方法来获取。
到此,根据分析到的信息进行规律对比,写出获取第一页图书信息的代码:
import requests from lxml import etree html = requests.get('https://book.douban.com/top250').text res = etree.HTML(html) trs = res.xpath('//*[@id="content"]/div/div[1]/div/table/tr') for tr in trs: name = tr.xpath('./td[2]/div[1]/a/text()')[0].strip() score = tr.xpath('./td[2]/div[2]/span[2]/text()')[0].strip() comment = tr.xpath('./td[2]/div[2]/span[3]/text()')[0].strip() info = tr.xpath('./td[2]/p[1]/text()')[0].strip() print(name,score,comment,info)
执行结果展示(内容较多,只展示前部分)

以上只是获取第一页的数据,接下来,我们获取到全部页数的链接,然后进行循环即可
三、获取全部链接地址
查看分析页数对应网页源码:
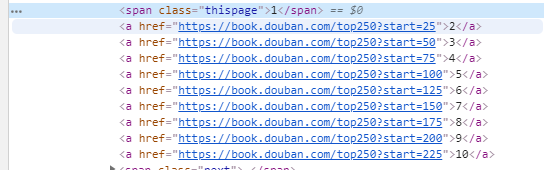
以代码实现
for i in range(10): url = 'https://book.douban.com/top250?start={}'.format(i * 25) print(url)
执行结果:正是正确的结果

经过分析,已经获取到全部的页面链接和每一页的数据提取,最后把整体代码进行整理和优化。
完整代码
#-*- coding:utf-8 -*- """ ------------------------------------------------- File Name: DoubanBookTop250 Author : zww Date: 2019/5/13 Change Activity:2019/5/13 ------------------------------------------------- """ import requests from lxml import etree #获取每页地址 def getUrl(): for i in range(10): url = 'https://book.douban.com/top250?start={}'.format(i*25) urlData(url) #获取每页数据 def urlData(url): html = requests.get(url).text res = etree.HTML(html) trs = res.xpath('//*[@id="content"]/div/div[1]/div/table/tr') for tr in trs: name = tr.xpath('./td[2]/div/a/text()')[0].strip() score = tr.xpath('./td[2]/div/span[2]/text()')[0].strip() comment = tr.xpath('./td[2]/div/span[3]/text()')[0].replace('(','').replace(')','').strip() info = tr.xpath('./td[2]/p[1]/text()')[0].strip() print("《{}》--{}分--{}--{}".format(name,score,comment,info)) if __name__ == '__main__': getUrl()
执行结果:总共250条图书信息,一条不少,由于数据太多,只展示前部分

把爬取到的数据存储到csv文件中
def write_to_file(content): #‘a’追加模式,‘utf_8_sig’格式到处csv不乱码 with open('DoubanBookTop250.csv','a',encoding='utf_8_sig',newline='') as f: fieldnames = ['name','score','comment','info'] #利用csv包的DictWriter函数将字典格式数据存储到csv文件中 w = csv.DictWriter(f,fieldnames=fieldnames) w.writerow(content)
完整代码
#-*- coding:utf-8 -*- """ ------------------------------------------------- File Name: DoubanBookTop250 Author : zww Date: 2019/5/13 Change Activity:2019/5/13 ------------------------------------------------- """ import csv import requests from lxml import etree #获取每页地址 def getUrl(): for i in range(10): url = 'https://book.douban.com/top250?start={}'.format(i*25) for item in urlData(url): write_to_file(item) print('成功保存豆瓣图书Top250第{}页的数据!'.format(i+1)) #数据存储到csv def write_to_file(content): #‘a’追加模式,‘utf_8_sig’格式到处csv不乱码 with open('DoubanBookTop250.csv','a',encoding='utf_8_sig',newline='') as f: fieldnames = ['name','score','comment','info'] #利用csv包的DictWriter函数将字典格式数据存储到csv文件中 w = csv.DictWriter(f,fieldnames=fieldnames) w.writerow(content) #获取每页数据 def urlData(url): html = requests.get(url).text res = etree.HTML(html) trs = res.xpath('//*[@id="content"]/div/div[1]/div/table/tr') for tr in trs: yield { 'name':tr.xpath('./td[2]/div/a/text()')[0].strip(), 'score':tr.xpath('./td[2]/div/span[2]/text()')[0].strip(), 'comment':tr.xpath('./td[2]/div/span[3]/text()')[0].replace('(','').replace(')','').strip(), 'info':tr.xpath('./td[2]/p[1]/text()')[0].strip() } #print("《{}》--{}分--{}--{}".format(name,score,comment,info)) if __name__ == '__main__': getUrl()
内容过多,只展示前部分


 浙公网安备 33010602011771号
浙公网安备 33010602011771号