
ARM - Neon/SVE/SME 矩阵乘法运算对比
ARM 的 Neon、SVE 和 SME 架构都可以计算矩阵乘法,本篇博客将对比这三种架构。
本博客的编写参考了基于以下 ARM 社区文章:
- Part 1: Arm Scalable Matrix Extension (SME) Introduction
- Part 2: Arm Scalable Matrix Extension (SME) Instructions
- Part 3: Matrix-matrix multiplication. Neon, SVE, and SME compared
架构演进
Neon、SVE/SV2 和 SME/SME2 技术被引入 Arm 架构的时间线如下:
- Armv7 引入了高级 SIMD 扩展,为多种整数和浮点类型提供单指令多数据(SIMD)操作。Neon 是高级 SIMD 指令的实现,为部分 Cortex-A 系列处理器提供 SIMD 扩展功能。Neon 于 2011 年在 ARMv7-A 架构中首次推出,采用固定宽度 128 位寄存器设计。这意味着每条 Neon 指令都处理固定数量的数据值,例如四个 32 位数据值。
- 2016 年 Armv8-A 引入的 SVE 及 2021 年 Armv9-A 引入的 SVE2 则采用可变长度寄存器架构。寄存器大小由具体实现定义,范围从 128 位到 2048 位不等。这意味着程序员无需知晓可用寄存器的具体尺寸,编写的代码必须与向量长度无关。因此,每条指令处理的数据量不是固定的,而是可变的。
- SME 和 SME2 均于 2021 年随 Armv9-A 架构推出,同样提供可变长度寄存器。SME 引入了两大关键架构特性:流式 SVE 模式和 ZA 存储。流式 SVE 模式是一种高吞吐量矩阵数据处理模式,而 ZA 存储则是专为常见矩阵运算优化的二维专用存储阵列。这些特性使 SME 和 SME2 能够高效处理基于矩阵和向量的工作负载。
这些 SIMD 架构扩展提供的指令集可加速包括以下领域在内的广泛应用:媒体与信号处理应用、高性能计算(HPC)应用、机器学习(ML)应用。
本文示例采用内联函数(intrinsics),这些由编译器提供的函数对应特定的 Arm 指令。这使得程序员能够完全使用 C 语言而非汇编语言编写程序。
矩阵乘法运算
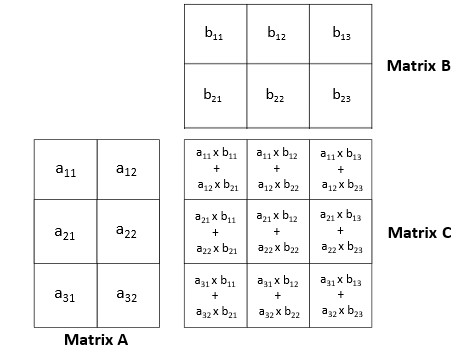
本文三个示例均实现了矩阵乘法运算。该运算通过将第一个矩阵的行元素与第二个矩阵的列对应元素相乘后求和,最终生成结果矩阵。结果矩阵的维度由第一个矩阵的行数和第二个矩阵的列数决定。例如,3×2 矩阵与 2×3 矩阵相乘将得到 3×3 矩阵。
Neon
本示例使用 Neon 内敛函数来执行矩阵乘法运算。代码执行以下操作:
- 两个输入矩阵包含以列优先格式存储的 32 位浮点数据。
- 代码以 4x4 的块为单位遍历这些矩阵中的所有数据。
- vld 内联函数从输入矩阵的行列中加载四个值到 Neon 寄存器。
- 每个 Neon fma 内联函数执行四次乘加运算,计算 4x4 块的结果。
- 使用 vst 内联函数将结果矩阵存储到内存中。
void matrix_multiply_neon(float32_t *A, float32_t *B, float32_t *C, uint32_t n, uint32_t m, uint32_t k) {
/*
* Multiply matrices A and B, store the result in C.
* It is the user's responsibility to make sure the matrices are compatible.
*/
int A_idx;
int B_idx;
int C_idx;
// these are the columns of a 4x4 sub matrix of A
float32x4_t A0;
float32x4_t A1;
float32x4_t A2;
float32x4_t A3;
// these are the columns of a 4x4 sub matrix of B
float32x4_t B0;
float32x4_t B1;
float32x4_t B2;
float32x4_t B3;
// these are the columns of a 4x4 sub matrix of C
float32x4_t C0;
float32x4_t C1;
float32x4_t C2;
float32x4_t C3;
for (int i_idx=0; i_idx<n; i_idx+=4) {
for (int j_idx=0; j_idx<m; j_idx+=4) {
// Zero accumulators before matrix op
C0 = vmovq_n_f32(0);
C1 = vmovq_n_f32(0);
C2 = vmovq_n_f32(0);
C3 = vmovq_n_f32(0);
for (int k_idx=0; k_idx<k; k_idx+=4) {
// Compute base index to 4x4 block
A_idx = i_idx + n*k_idx;
B_idx = k*j_idx + k_idx;
// Load most current A values in row
A0 = vld1q_f32(A+A_idx);
A1 = vld1q_f32(A+A_idx+n);
A2 = vld1q_f32(A+A_idx+2*n);
A3 = vld1q_f32(A+A_idx+3*n);
// Multiply accumulate in 4x1 blocks, i.e. each column in C
B0 = vld1q_f32(B+B_idx);
C0 = vfmaq_laneq_f32(C0, A0, B0, 0);
C0 = vfmaq_laneq_f32(C0, A1, B0, 1);
C0 = vfmaq_laneq_f32(C0, A2, B0, 2);
C0 = vfmaq_laneq_f32(C0, A3, B0, 3);
B1 = vld1q_f32(B+B_idx+k);
C1 = vfmaq_laneq_f32(C1, A0, B1, 0);
C1 = vfmaq_laneq_f32(C1, A1, B1, 1);
C1 = vfmaq_laneq_f32(C1, A2, B1, 2);
C1 = vfmaq_laneq_f32(C1, A3, B1, 3);
B2 = vld1q_f32(B+B_idx+2*k);
C2 = vfmaq_laneq_f32(C2, A0, B2, 0);
C2 = vfmaq_laneq_f32(C2, A1, B2, 1);
C2 = vfmaq_laneq_f32(C2, A2, B2, 2);
C2 = vfmaq_laneq_f32(C2, A3, B2, 3);
B3 = vld1q_f32(B+B_idx+3*k);
C3 = vfmaq_laneq_f32(C3, A0, B3, 0);
C3 = vfmaq_laneq_f32(C3, A1, B3, 1);
C3 = vfmaq_laneq_f32(C3, A2, B3, 2);
C3 = vfmaq_laneq_f32(C3, A3, B3, 3);
}
// Compute base index for stores
C_idx = n*j_idx + i_idx;
vst1q_f32(C+C_idx, C0);
vst1q_f32(C+C_idx+n, C1);
vst1q_f32(C+C_idx+2*n, C2);
vst1q_f32(C+C_idx+3*n, C3);
}
}
}
此示例使用了以下 Neon 代码特性:
| 指令 | 描述 |
|---|---|
float32x4_t |
包含四个 32 位浮点值的向量数据类型。 |
| vld1q_f32 | 一个 Neon 内联函数,用于将四个 32 位浮点数从连续的内存地址加载到 float32x4_t 中。 |
| vfmaq_lane_f32 | 一条执行融合乘加操作的 Neon 内联函数。它将一个 float32x4_t 值与另一个 float32x4_t 的单个元素相乘,然后将结果与第三个 float32x4_t 相加后返回最终结果。 |
| vst1q_f32 | 一个 Neon 内联函数,将四个值存储在 float32x4_t 中并连续存入内存地址。 |
本示例采用固定的 4x4 块大小,这意味着输入矩阵在两个维度上都必须是 4 的倍数。对于其他尺寸的矩阵,可以通过补零填充来处理。
SVE/SVE2
此示例使用 SVE2 内联函数来执行矩阵乘法运算。
Neon 示例与这个 SVE2 示例的主要区别在于 SVE2 采用了可变长度向量。Neon 示例使用固定的 4x4 块大小来匹配 Neon 寄存器中可容纳的四个 32 位值,而 SVE2 寄存器的大小在运行时才能确定。这意味着代码必须与向量长度无关。该示例通过谓词化控制 SVE2 内联函数操作的数据值数量,确保无论实现何种寄存器大小都能完美适配。Neon 示例使用 32 位浮点数据类型 float32x4_t (其中数字 4 表示每个 Neon 寄存器可容纳 4 个 32 位值),而 SVE2 示例采用 svfloat32_t 数据类型,因为 SVE2 寄存器的大小需在运行时才能获知。代码执行以下操作:
- 两个输入矩阵包含以列优先格式存储的 32 位浮点数据。
- 代码以四行为一组遍历这些矩阵中的所有数据。它使用 svcntw 内联函数(该函数返回向量中 32 位元素的数量)来确保加载的列数与 SVE2 寄存器的大小匹配。这有助于避免在外层循环的每次迭代中硬编码元素数量。
whileit内联函数创建谓词以确保不会超出矩阵边界。 - 四个
svld内联函数使用先前创建的谓词将矩阵数据加载到 SVE2 寄存器中。 svlma内联函数执行乘加运算,计算当前迭代的结果。svst内联函数将结果矩阵存储到内存中。
void matrix_multiply_sve(const float32_t *A, const float32_t *B, float32_t *C, uint32_t n, uint32_t m, uint32_t k) {
/*
* Multiply matrices A and B, store the result in C.
* It is the users responsibility to make sure the matrices are compatible.
*/
int a_idx;
int b_idx;
int c_idx;
// these are the columns of a nx4 sub matrix of A
svfloat32_t A0;
svfloat32_t A1;
svfloat32_t A2;
svfloat32_t A3;
// these are the columns of a 4x4 sub matrix of B
svfloat32_t B0;
svfloat32_t B1;
svfloat32_t B2;
svfloat32_t B3;
// these are the columns of a nx4 sub matrix of C
svfloat32_t C0;
svfloat32_t C1;
svfloat32_t C2;
svfloat32_t C3;
for (int i_idx=0; i_idx<n; i_idx+=svcntw()) {
// calculate predicate for this i_idx
svbool_t pred = svwhilelt_b32_u32(i_idx, n);
for (int j_idx=0; j_idx<m; j_idx+=4) {
// zero accumulators before matrix op
C0 = svdup_n_f32(0);
C1 = svdup_n_f32(0);
C2 = svdup_n_f32(0);
C3 = svdup_n_f32(0);
for (int k_idx=0; k_idx<k; k_idx+=4){
// compute base index to 4x4 block
a_idx = i_idx + n*k_idx;
b_idx = k*j_idx + k_idx;
// load most current a values in row
A0 = svld1_f32(pred, A+a_idx);
A1 = svld1_f32(pred, A+a_idx+n);
A2 = svld1_f32(pred, A+a_idx+2*n);
A3 = svld1_f32(pred, A+a_idx+3*n);
// multiply accumulate 4x1 blocks, that is each column C
B0 = svld1rq_f32(svptrue_b32(), B+b_idx);
C0 = svmla_lane_f32(C0,A0,B0,0);
C0 = svmla_lane_f32(C0,A1,B0,1);
C0 = svmla_lane_f32(C0,A2,B0,2);
C0 = svmla_lane_f32(C0,A3,B0,3);
B1 = svld1rq_f32(svptrue_b32(), B+b_idx+k);
C1 = svmla_lane_f32(C1,A0,B1,0);
C1 = svmla_lane_f32(C1,A1,B1,1);
C1 = svmla_lane_f32(C1,A2,B1,2);
C1 = svmla_lane_f32(C1,A3,B1,3);
B2 = svld1rq_f32(svptrue_b32(), B+b_idx+2*k);
C2 = svmla_lane_f32(C2,A0,B2,0);
C2 = svmla_lane_f32(C2,A1,B2,1);
C2 = svmla_lane_f32(C2,A2,B2,2);
C2 = svmla_lane_f32(C2,A3,B2,3);
B3 = svld1rq_f32(svptrue_b32(), B+b_idx+3*k);
C3 = svmla_lane_f32(C3,A0,B3,0);
C3 = svmla_lane_f32(C3,A1,B3,1);
C3 = svmla_lane_f32(C3,A2,B3,2);
C3 = svmla_lane_f32(C3,A3,B3,3);
}
// compute base index for stores
c_idx = n*j_idx + i_idx;
svst1_f32(pred, C+c_idx, C0);
svst1_f32(pred, C+c_idx+n,C1);
svst1_f32(pred, C+c_idx+2*n,C2);
svst1_f32(pred, C+c_idx+3*n,C3);
}
}
}
本示例使用了以下 SVE2 代码特性:
| 指令 | 描述 |
|---|---|
svfloat32_t |
一种包含 32 位浮点值的向量数据类型,其具体数值数量在运行时根据 SVE 向量长度确定。 |
| svwhilelt_b32_u32 | SVE2 内联函数,通过两个 uint32_t 整型数(起始值和最大值)计算得出谓词。 |
| svld1_f32 | 将 32 位浮点值加载到 SVE2 寄存器的 SVE2 内联函数。 |
| svptrue_b32 | 将 32 位值设置全真谓词的 SVE2 内联函数。 |
| svld1rq_f32 | 用相同 128 位数据(四个 32 位值)的副本填充 SVE2 寄存器的 SVE2 内联函数。 |
| svmla_lane_f32 | 执行融合乘加指令的 SVE2 内联函数。该函数将 svfloat32_t 值的每个 128 位段与另一个 svfloat32_t 的对应单个元素相乘,随后 svmla_lane_f32 内联函数将结果与第三个 svfloat32_t相加后返回最终结果。 |
| svst1_f32 | 将 svfloat32_t 中的值存储到连续内存地址的 SVE2 内联函数。 |
SME/SME2
本示例使用 SME2 汇编指令执行矩阵乘法运算。此 SME2 示例与其他示例的区别如下:
- 该 SME2 示例使用汇编代码而非其他示例所采用的内联函数。
- SME2 提供了 ZA 存储,这是一个专为矩阵运算设计的二维数据阵列。该 ZA 存储中的子数组可作为图块访问,且图块内的元素可垂直或水平访问。这为操作矩阵数据提供了非常灵活的机制。
- SME2 提供了执行矩阵运算的新指令。例如,
fmopa指令可计算外积。 - SME2 提供了多向量二维谓词机制,确保不会超出矩阵边界。
通过 smstart 指令进入的流式 SVE 模式,可启用 SME2 指令及 ZA 存储功能。该示例以输入矩阵 matLeft 和 matRight 为例。示例利用了矩阵相乘等同于对 matLeft 的每列与 matRight 的每行依次求外积之和这一数学特性。初始输入矩阵以行主序数组形式存储于内存中。矩阵乘法通过计算 matLeft 的一列与 matRight 的一行的外积之和来实现。由于外积运算需要 matLeft 的列元素,代码对 matLeft 数据进行重组,使列元素在内存中连续存储。出于简洁考虑,此处未展示数据重组过程,具体可参阅 SME 程序员指南。
此示例包含三个嵌套循环:
- 最外层循环遍历结果矩阵的行;
- 中间循环遍历结果矩阵的列;
- 最内层循环遍历 K 维度,将结果矩阵元素计算为乘积之和。
矩阵数据通过 ld1w 指令从内存加载到 ZA 存储区。外积计算使用 fmopa 指令。每条 fmopa 指令读取两个 SVE Z 输入向量,并用结果更新整个 SME ZA 分块。二维谓词确保不会超出矩阵的边界。最后, st1w 指令将结果从 ZA 存储写入内存。
matmul_opt:
// matmul_opt(M, K, N, matLeft, matRight, matResult_opt);
// x0 : M
// x1 : K, lda
// x2 : N, ldc, ldb
// x3 : &matLeft
// x4 : &matRight
// x5 : &matResult_opt
// x6 : SVLs-2
// x7 : a_ptr pointer
// x8 : a_ptr end address
// x9 : c_base pointer
// x10: c_ptr0 pointer
// x11: Exit condition for N loop
// x12: M loop counter
// x13: Store loop counter
// x14: Predicate select index
// x15: Exit condition for K loop
// x16: b_base pointer
// x17: b_ptr pointer
// x18: (SVLs+1)*ldc
// x19: ldb + SVLs
// x20: SVLs*lda + SVLs
// x21: c_ptr1 pointer
// x22: SVLs*lda
// x23: SVLs*ldc
// Assumptions:
// nbr in matLeft (M): any
// nbc in matLeft, nbr in matRight (K): any K > 2
// nbc in matRight (N): any
//
// Left matrix is pre-arranged.
//
// 32-bit accumulator mapping with 2x2 tiles processing
stp x19, x20, [sp, #-48]!
stp x21, x22, [sp, #16]
stp x23, x24, [sp, #32]
smstart
// constants
cntw x6 // SVLs
mul x22, x6, x1 // SVLs*lda
mul x23, x6, x2 // SVLs*ldc
add x18, x23, x2 // SVLs*ldc + ldc
add x11, x4, x2, lsl #2 // Exit condition for N loop
mov x12, #0
cntb x6 // SVLb
mov x14, #0
ptrue pn10.b // Predicate as counter for SME2 VLx2 (a_ptr loads)
whilelt pn8.s, x12, x0, vlx2 // tiles predicate (M dimension)
sub w6, w6, #8 // SVLb-8
.Loop_M:
// Extracting tile 0/1 and tile 2/3 predicates (M dimension) from vlx2 predicate.
pext { p2.s, p3.s }, pn8[0]
mov x16, x4 // b_base
mov x9, x5 // c_base
whilelt pn9.b, x16, x11, vlx2 // tiles predicate (N dimension)
.Loop_N:
mov x7, x3 // a_ptr = a_base
mov x17, x16 // b_ptr = b_base
mov x10, x9 // c_ptr0 = c_base
// Extracting tile 0/2 and tile 1/3 predicates (N dimension) from vlx2 predicate.
pext { p0.b, p1.b }, pn9[0]
add x8, x3, x22, lsl #2 // a_base + SVLs*lda FP32 elms [Bytes]
addvl x15, x8, #-1 // Exit condition for K loop
ld1w {z1.s}, p2/z, [x7] // Load 1st vector from a_ptr
zero {za}
ld1w {z2.s-z3.s}, pn9/z, [x17] // Load 2 vectors from b_ptr
fmopa za0.s, p2/m, p0/m, z1.s, z2.s // ZA0 += 1st a_ptr vector OP 1st b_ptr vector
ld1w {z5.s}, p3/z, [x7, x22, lsl #2] // Load 2nd vector from a_ptr
addvl x7, x7, #1 // a_ptr += SVLb [Bytes]
.Loop_K:
fmopa za2.s, p3/m, p0/m, z5.s, z2.s // ZA2 += 2nd a_ptr vector OP 1st b_ptr vector
ld1w {z3.s}, p1/z, [x17, #1, MUL VL] // Load 2nd vector from b_ptr
fmopa za1.s, p2/m, p1/m, z1.s, z3.s // ZA1 += 1st a_ptr vector OP 2nd b_ptr vector
ld1w {z0.s-z1.s}, pn10/z, [x7] // Load next 2 vectors from a_ptr
fmopa za3.s, p3/m, p1/m, z5.s, z3.s // ZA3 += 2nd a_ptr vector OP 2nd b_ptr vector
ld1w {z6.s-z7.s}, pn9/z, [x17, x2, lsl #2] // Load next 2 vectors from b_ptr
fmopa za0.s, p2/m, p0/m, z0.s, z6.s // ZA0 += 1st a_ptr vector OP 1st b_ptr vector
psel pn11, pn10, p3.s[w14, 0] // Select predicate-as-counter
ld1w {z4.s-z5.s}, pn11/z, [x7, x22, lsl #2] // Load next 2 vectors from a_ptr
fmopa za2.s, p3/m, p0/m, z4.s, z6.s // ZA2 += 2nd a_ptr vector OP 1st b_ptr vector
add x17, x17, x2, lsl #3 // b_ptr += 2*ldb FP32 elms [Bytes]
fmopa za1.s, p2/m, p1/m, z0.s, z7.s // ZA1 += 1st a_ptr vector OP 2nd b_ptr vector
fmopa za3.s, p3/m, p1/m, z4.s, z7.s // ZA3 += 2nd a_ptr vector OP 2nd b_ptr vector
ld1w {z2.s-z3.s}, pn9/z, [x17] // Load next 2 vectors from b_ptr
fmopa za0.s, p2/m, p0/m, z1.s, z2.s // ZA0 += 1st a_ptr vector OP 1st b_ptr vector
addvl x7, x7, #2 // a_ptr += 2*SVLb [Bytes]
cmp x7, x15
b.mi .Loop_K
fmopa za2.s, p3/m, p0/m, z5.s, z2.s // ZA2 += 2nd a_ptr vector OP 1st b_ptr vector
fmopa za1.s, p2/m, p1/m, z1.s, z3.s // ZA1 += 1st a_ptr vector OP 2nd b_ptr vector
fmopa za3.s, p3/m, p1/m, z5.s, z3.s // ZA3 += 2nd a_ptr vector OP 2nd b_ptr vector
add x17, x17, x2, lsl #2 // b_ptr += 2*ldb FP32 elms [Bytes]
cmp x7, x8
b.pl .Ktail_end
.Ktail_start:
ld1w {z1.s}, p2/z, [x7]
ld1w {z2.s-z3.s}, pn9/z, [x17]
fmopa za0.s, p2/m, p0/m, z1.s, z2.s
ld1w {z5.s}, p3/z, [x7, x22, lsl #2]
fmopa za2.s, p3/m, p0/m, z5.s, z2.s
fmopa za1.s, p2/m, p1/m, z1.s, z3.s
fmopa za3.s, p3/m, p1/m, z5.s, z3.s
.Ktail_end:
mov w13, #0
psel pn11, pn9, p2.b[w13, 0]
psel pn12, pn9, p3.b[w13, 0]
// Move from ZA tiles to vectors: z0 = za0h[1], z1 = za1h[1], z2 = za2h[1], z3 = za3h[1]
mova { z0.b-z3.b }, za0h.b[w13, 0:3]
st1w { z0.s-z1.s }, pn11, [x10] // Store to c_ptr0
st1w { z2.s-z3.s }, pn12, [x10, x23, lsl #2] // Store to c_ptr0 + SVLs*ldc
.Loop_store_ZA:
psel pn11, pn9, p2.b[w13, 4]
psel pn12, pn9, p3.b[w13, 4]
mova { z0.b-z3.b }, za0h.b[w13, 4:7]
st1w { z0.s-z1.s }, pn11, [x10, x2, lsl #2] // Store to c_ptr0 + ldc
st1w { z2.s-z3.s }, pn12, [x10, x18, lsl #2] // Store to c_ptr0 + (SVLs+1)*ldc
add x10, x10, x2, lsl #3 // c_ptr0 += 2*ldc FP32 elms [Bytes]
add w13, w13, #8
psel pn11, pn9, p2.b[w13, 0]
psel pn12, pn9, p3.b[w13, 0]
mova { z0.b-z3.b }, za0h.b[w13, 0:3]
st1w { z0.s-z1.s }, pn11, [x10] // Store to c_ptr0
st1w { z2.s-z3.s }, pn12, [x10, x23, lsl #2] // Store to c_ptr0 + SVLs*ldc
cmp w13, w6
b.mi .Loop_store_ZA
psel pn11, pn9, p2.b[w13, 4]
psel pn12, pn9, p3.b[w13, 4]
mova { z0.b-z3.b }, za0h.b[w13, 4:7]
st1w { z0.s-z1.s }, pn11, [x10, x2, lsl #2] // Store to c_ptr0 + ldc
st1w { z2.s-z3.s }, pn12, [x10, x18, lsl #2] // Store to c_ptr0 + (SVLs+1)*ldc
addvl x9, x9, #2
addvl x16, x16, #2 // b_base += 2*SVLb [Bytes]
whilelt pn9.b, x16, x11, vlx2 // tile predicate (N dimension)
b.first .Loop_N
add x3, x3, x22, lsl #3 // a_base += 2*SVLs*lda FP32 elms [Bytes]
add x5, x5, x23, lsl #3 // c_base += 2*SVLs*ldc FP32 elms [Bytes]
incw x12, all, mul #2 // M loop counter += 2* SVLs
whilelt pn8.s, x12, x0, vlx2 // tiles predicate (M dimension)
b.first .Loop_M
smstop
ldp x23, x24, [sp, #32]
ldp x21, x22, [sp, #16]
ldp x19, x20, [sp], #48
ret
.size matmul_opt, .-matmul_opt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号